Прави са. Присъединяването към текстово поле CHAR(30) – особено такова, което съдържа данни за имена на човек – ще бъде бавно, крайно неефективно и невероятно крехко. Хората променят имената си (бракът е очевидният пример) и няколко души могат да имат едно и също име.
Искате да създадете подходящи индекси на вашите таблици, за да поддържате реда, в който искате да се показват данните, и да забравите клъстерирането. Вашата процедура за оптимизиране на производителността звучи като бедствие, което търси място, където да се случи. Съжалявам, но пускането/създаването на таблиците по този начин създава проблеми.
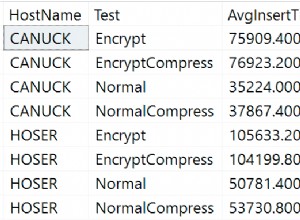
Бих започнал с УНИКАЛЕН ИНДЕКС на customer.id, УНИКАЛЕН ИНДЕКС на транзакция.ticket_number и ИНДЕКС (за производителност, а не за кардиналност, така че налагането на уникалност не е особено важно) за транзакции (id, ticket_number DESC) и да го взема от там. Данните се връщат от таблицата на транзакциите в реда, в който се появяват в индекса.
Бих разгледал групирането само когато всички други възможности за оптимизиране на заявките са изчерпани.