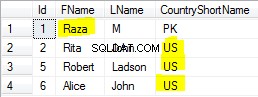
PARTITION BY отделни набори, това ви позволява да можете да работите (ROW_NUMBER(),COUNT(),SUM() и т.н.) върху свързан набор независимо.
Във вашата заявка свързаният набор се състои от редове с подобни cdt.country_code, cdt.account, cdt.currency. Когато разделите на тези колони и приложите ROW_NUMBER върху тях. Тези други колони в тази комбинация/набор ще получат пореден номер от ROW_NUMBER
Но тази заявка е смешна, ако вашият дял е с някакви уникални данни и поставите row_number върху него, то просто ще произведе същото число. Все едно правиш ORDER BY на дял, който гарантирано е уникален. Например, помислете за GUID като уникална комбинация от cdt.country_code, cdt.account, cdt.currency
newid() произвежда GUID, така че какво да очаквате от този израз?
select
hi,ho,
row_number() over(partition by newid() order by hi,ho)
from tbl;
...Добре, всички разделени (нито един не е бил разделен, всеки ред е разделен на собствен ред) номерата на редове на редове са всички настроени на 1
По принцип трябва да разделите на неуникални колони. ORDER BY на OVER се нуждаеше от PARTITION BY да има неуникална комбинация, в противен случай всички row_numbers ще станат 1
Пример, това са вашите данни:
create table tbl(hi varchar, ho varchar);
insert into tbl values
('A','X'),
('A','Y'),
('A','Z'),
('B','W'),
('B','W'),
('C','L'),
('C','L');
Тогава това е аналогично на вашата заявка:
select
hi,ho,
row_number() over(partition by hi,ho order by hi,ho)
from tbl;
Какъв ще бъде резултатът от това?
HI HO COLUMN_2
A X 1
A Y 1
A Z 1
B W 1
B W 2
C L 1
C L 2
Виждате ли комбинацията от HI HO? Първите три реда имат уникална комбинация, следователно те са зададени на 1, B редовете имат същия W, следователно различни ROW_NUMBERS, по същия начин с HI C редове.
Сега, защо е ORDER BY има нужда там? Ако предишният разработчик просто иска да постави row_number на подобни данни (например HI B, всички данни са B-W, B-W), той може просто да направи това:
select
hi,ho,
row_number() over(partition by hi,ho)
from tbl;
Но уви, Oracle (и Sql Server също) не позволява дял без ORDER BY; докато в Postgresql, ORDER BY на PARTITION е по избор:https://www.sqlfiddle.com/#!1/27821/1
select
hi,ho,
row_number() over(partition by hi,ho)
from tbl;
Вашият ORDER BY на вашия дял изглежда малко излишен, не поради грешка на предишния разработчик, някои бази данни просто не позволяват PARTITION без ORDER BY , той може да не успее да намери добър кандидат колона, по която да сортира. Ако и двете колони PARTITION BY и ORDER BY са еднакви, просто премахнете ORDER BY, но тъй като някои бази данни не го позволяват, можете просто да направите това:
SELECT cdt.*,
ROW_NUMBER ()
OVER (PARTITION BY cdt.country_code, cdt.account, cdt.currency
ORDER BY newid())
seq_no
FROM CUSTOMER_DETAILS cdt
Не можете да намерите добра колона, която да използвате за сортиране на подобни данни? Можете също да сортирате на случаен принцип, разделените данни имат същите стойности така или иначе. Можете да използвате GUID например (използвате newid() за SQL Server). Така че това има същия изход, направен от предишния разработчик, жалко е, че някои бази данни не позволяват PARTITION без ORDER BY
Въпреки че наистина, това ми убягва и не мога да намеря добра причина да сложа число на едни и същи комбинации (B-W, B-W в примера по-горе). Създава впечатление, че базата данни има излишни данни. Някак си ми напомни за това:Как да получа един уникален запис от същия списък със записи от таблица? Няма уникално ограничение в таблицата
Наистина изглежда тайнствено да видите PARTITION BY със същата комбинация от колони с ORDER BY, не може лесно да се заключи намерението на кода.
Тест на живо:https://www.sqlfiddle.com/#!3/27821/6
Но както dbaseman също забеляза, безполезно е да се разделят и подреждат на едни и същи колони.
Имате набор от данни като този:
create table tbl(hi varchar, ho varchar);
insert into tbl values
('A','X'),
('A','X'),
('A','X'),
('B','Y'),
('B','Y'),
('C','Z'),
('C','Z');
Тогава вие РАЗДЕЛЯТЕ ОТ hi,ho; и след това ПОРЪЧВАТЕ ОТ hi,ho. Няма смисъл да номерирате подобни данни :-) https://www.sqlfiddle.com/#!3/29ab8/3
select
hi,ho,
row_number() over(partition by hi,ho order by hi,ho) as nr
from tbl;
Изход:
HI HO ROW_QUERY_A
A X 1
A X 2
A X 3
B Y 1
B Y 2
C Z 1
C Z 2
Виждаш ли? Защо трябва да поставяте номера на редове в една и съща комбинация? Какво ще анализирате на тройно A,X, на двойно B,Y, на двойно C,Z? :-)
Просто трябва да използвате PARTITION върху неуникална колона, след което сортирате по уникалната колона(и) на неуникална(и) -ing колона. Примерът ще направи по-ясно:
create table tbl(hi varchar, ho varchar);
insert into tbl values
('A','D'),
('A','E'),
('A','F'),
('B','F'),
('B','E'),
('C','E'),
('C','D');
select
hi,ho,
row_number() over(partition by hi order by ho) as nr
from tbl;
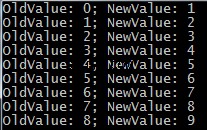
PARTITION BY hi работи с неуникална колона, след което за всяка разделена колона, вие поръчвате по нейната уникална колона(ho), ORDER BY ho
Изход:
HI HO NR
A D 1
A E 2
A F 3
B E 1
B F 2
C D 1
C E 2
Този набор от данни има повече смисъл
Тест на живо:https://www.sqlfiddle.com/#!3/d0b44/1
И това е подобно на вашата заявка със същите колони както на PARTITION BY, така и на ORDER BY:
select
hi,ho,
row_number() over(partition by hi,ho order by hi,ho) as nr
from tbl;
И това е изходът:
HI HO NR
A D 1
A E 1
A F 1
B E 1
B F 1
C D 1
C E 1
Виждаш ли? няма смисъл?
Тест на живо:https://www.sqlfiddle.com/#!3/d0b44/3
Най-накрая това може да е правилната заявка:
SELECT cdt.*,
ROW_NUMBER ()
OVER (PARTITION BY cdt.country_code, cdt.account -- removed: cdt.currency
ORDER BY
-- removed: cdt.country_code, cdt.account,
cdt.currency) -- keep
seq_no
FROM CUSTOMER_DETAILS cdt