Понякога се случва, че имате много голям текстов или CSV файл за обработка, но първо искате да направите по-малки файлове от този голям файл. Тъй като този голям файл може да отнеме твърде много време за обработка или отваряне. Така че давам пример по-долу за разделяне на голям текстов/CSV файл на множество файлове в PL SQL с помощта на съхранена процедура.
Просто трябва да предадете два параметъра на тази PL SQL процедура, първият е името на обекта на директорията на базата данни, където се намират текстовите файлове, а вторият е името на изходния файл (файлът, който искате да разделите).
Ако обектът на директорията на Oracle не съществува за местоположението на текстови файлове, тогава можете да го създадете, както е показано по-долу:
For windows: CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS 'D:\plsql\text_files';
For Linux/Unix (due to difference in path): CREATE OR REPLACE DIRECTORY CSV_FILE_DIR AS '/plsql/text_files';
Променете пътя по-горе според местоположението на вашите файлове. След това създайте процедурата по-долу, като изпълните нейния скрипт:
CREATE OR REPLACE PROCEDURE split_file (p_db_dir IN VARCHAR2, p_file_name IN VARCHAR2) IS read_file UTL_FILE.file_type; write_file UTL_FILE.file_type; v_string VARCHAR2 (32767); j NUMBER := 1; BEGIN read_file := UTL_FILE.fopen (p_db_dir, p_file_name, 'r'); WHILE j > 0 LOOP write_file := UTL_FILE.fopen (p_db_dir, j || '_' || p_file_name, 'w'); FOR i IN 1 .. 100 LOOP -- example to dividing into 100 rows for each file.. you can increase the number as per your requirement UTL_FILE.get_line (read_file, v_string); UTL_FILE.put_line (write_file, v_string); END LOOP; UTL_FILE.fclose (write_file); j := J + 1; END LOOP; EXCEPTION WHEN OTHERS THEN -- this will handle if reading source file contents finish UTL_FILE.fclose (read_file); UTL_FILE.fclose (write_file); END;
Тази процедура разделя 100 реда за всеки файл, който можете да промените според вашите нужди. Сега изпълнете тази процедура, както е показано по-долу, като предадете името на обекта на директорията на базата данни и името на файла:
BEGIN
split_file ('CSV_FILE_DIR', 'text_file.csv');
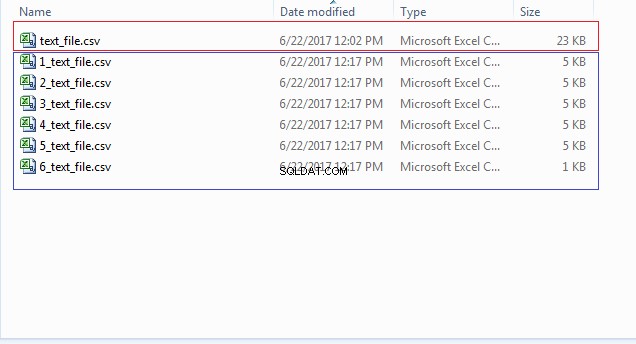
END; Можете да проверите местоположението на вашия файл (CSV_FILE_DIR) за множество файлове, започващи с числа като 1_text_file.csv, 2_text_file.csv и така нататък, както е показано на изображението по-долу: