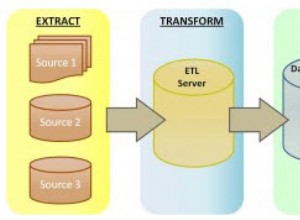
В момента с помощта на spring всички данни се извличат и потокът се прилага само към данни, които вече са в паметта.
Ако погледнете източника на org.springframework.data.jpa.provider.PersistenceProvider изглежда, че използва ScrollableResults за поточно предаване на данните.
Обикновено ScrollableResults извлече всички данни в паметта.
Можете да намерите интересен пълен анализ, като използвате MySql база данни тук , но вероятно същото работи и за база данни на Postgres.
Така че също така, ако мислите да използвате решение, което не се нуждае от много памет, в действителност го прави, защото основната реализация не използва оптимална реализация.