Не мога да намеря недостатък във вашия дизайн. Опитах.
Локални настройки и сортиране
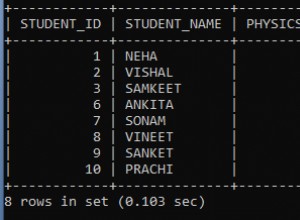
Прегледах отново този въпрос. Разгледайте този тестов случай на sqlfiddle
. Изглежда, че работи добре. Дори създадох локала ca_ES.utf8 в моя локален тестов сървър (PostgreSQL 9.1.6 на Debian Squeeze) и добавих локала към моя DB клъстер:
CREATE COLLATION "ca_ES" (LOCALE = 'ca_ES.utf8');
Получавам същите резултати, както могат да се видят в sqlfiddle по-горе.
Обърнете внимание, че имената на сортирането са идентификатори и трябва да бъдат поставени в двойни кавички, за да се запази изписването на CamelCase като "ca_ES" . Може би е имало известно объркване с други локали във вашата система? Проверете вашите налични съпоставки
:
SELECT * FROM pg_collation;
Обикновено правилата за сортиране се извличат от системни локали . Прочетете за подробности в ръководството тук
. Ако все още получавате неправилни резултати, ще се опитам да актуализирам вашата система и да генерирам отново локала за "ca_ES" . В Debian (и свързани дистрибуции на Linux) това може да се направи с:
dpkg-reconfigure locales
NFC
Имам още една идея:ненормализирани UNICODE низове .
Възможно ли е вашият 'Àudio' всъщност е '̀ ' || 'Audio' ? Това би бил този знак:
SELECT U&'\0300A';
SELECT ascii(U&'\0300A');
SELECT chr(768);
Прочетете повече за акут в wikipedia
.
Трябва да SET standard_conforming_strings = TRUE за да използвате Unicode низове като в първия ред.
Обърнете внимание, че някои браузъри не могат да показват правилно ненормализирани Unicode знаци и много шрифтове нямат подходящ глиф за специалните знаци, така че може да не видите нищо тук или да видите безсмислици. Но UNICODE позволява тази глупост. Тествайте, за да видите какво имате:
SELECT octet_length('̀A') -- returns 3 (!)
SELECT octet_length('À') -- returns 2
Ако това е, което вашата база данни е свила, трябва да се отървете от нея или да понесете последствията. Лечението е да нормализирате вашите низове към NFC . Perl има превъзходни UNICODE-foo умения, можете да използвате техните библиотеки във функция plperlu, за да го направите в PostgreSQL. Направих това, за да се спася от лудостта.
Прочетете инструкциите за инсталиране в тази отлична статия за нормализиране на UNICODE в PostgreSQL от Дейвид Уилър .
Прочетете всички кървави подробности за Unicode Normalization Forms в unicode.org
.