Въпреки че има различни начини за възстановяване на вашата PostgreSQL база данни, един от най-удобните подходи за възстановяване на вашите данни от логическо архивиране. Логическите архиви играят важна роля за планирането при бедствия и възстановяване (DRP). Логическите архиви са направени резервни копия, например с помощта на pg_dump или pg_dumpall, които генерират SQL оператори за получаване на всички данни от таблицата, записани в двоичен файл.
Препоръчва се също да изпълнявате периодични логически архиви, в случай че физическите ви архиви се провалят или са недостъпни. За PostgreSQL възстановяването може да бъде проблематично, ако не сте сигурни какви инструменти да използвате. Инструментът за архивиране pg_dump обикновено се свързва с инструмента за възстановяване pg_restore.
pg_dump и pg_restore действат в тандем, ако възникне бедствие и трябва да възстановите данните си. Въпреки че те служат на основната цел на изхвърляне и възстановяване, това изисква от вас да изпълнявате някои допълнителни задачи, когато трябва да възстановите клъстера си и да извършите отказ (ако вашият активен първичен или главен обект умре поради хардуерна повреда или повреда на системата на VM). В крайна сметка ще намерите и използвате инструменти на трети страни, които могат да се справят с преодоляване на отказ или автоматично възстановяване на клъстер.
В този блог ще разгледаме как работи pg_restore и ще го сравним с това как ClusterControl обработва архивиране и възстановяване на вашите данни в случай на бедствие.
Механизми на pg_restore
pg_restore е полезен при получаване на следните задачи:
- в двойка с pg_dump за генериране на генерирани от SQL файлове, съдържащи данни, роли за достъп, база данни и дефиниции на таблици
- възстановете PostgreSQL база данни от архив, създаден от pg_dump в един от форматите, които не са обикновен текст.
- Той ще издаде командите, необходими за реконструкция на базата данни до състоянието, в което е била по времето, когато е била записана.
- има способността да бъде избирателен или дори да пренарежда елементите, преди да бъдат възстановени въз основа на архивния файл
- Архивните файлове са проектирани да бъдат преносими в различни архитектури.
- pg_restore може да работи в два режима.
- Ако е посочено име на база данни, pg_restore се свързва с тази база данни и възстановява съдържанието на архива директно в базата данни.
- или скрипт, съдържащ SQL командите, необходими за възстановяване на базата данни, се създава и записва във файл или стандартен изход. Неговият изход на скрипт има еквивалент на формата, генериран от pg_dump
- Следователно някои от опциите, контролиращи изхода, са аналогични на опциите pg_dump.
След като възстановите данните, най-добре и препоръчително е да стартирате ANALYZE за всяка възстановена таблица, така че оптимизаторът да има полезна статистика. Въпреки че придобива READ LOCK, може да се наложи да го стартирате по време на нисък трафик или по време на периода на поддръжка.
Предимства на pg_restore
pg_dump и pg_restore в тандем има възможности, които са удобни за използване от DBA.
- pg_dump и pg_restore имат възможността да работят паралелно, като посочи опцията -j. Използването на -j/--jobs <брой-на-задания> ви позволява да укажете колко паралелно изпълнявани задачи могат да се изпълняват, особено за зареждане на данни, създаване на индекси или създаване на ограничения, използвайки множество едновременни задачи.
- Той е удобен за използване, можете избирателно да изхвърляте или зареждате конкретна база данни или таблици
- Позволява и предоставя гъвкавост на потребителя относно това каква конкретна база данни, схема или пренареждане на процедурите да се изпълняват въз основа на списъка. Можете дори да генерирате и зареждате последователността на SQL свободно, като предотвратяване на acls или привилегия в съответствие с вашите нужди. Има много опции, които да отговарят на вашите нужди.
- Той ви предоставя възможност да генерирате SQL файлове точно като pg_dump от архив. Това е много удобно, ако искате да заредите в друга база данни или хост, за да осигурите отделна среда.
- Лесно е за разбиране въз основа на генерираната последователност от SQL процедури.
- Това е удобен начин за зареждане на данни в среда за репликация. Не е необходимо вашата реплика да бъде преподредена, тъй като операторите са SQL, които са репликирани надолу до възлите за готовност и възстановяване.
Ограничения на pg_restore
За логически архиви, очевидните ограничения на pg_restore заедно с pg_dump са производителността и скоростта при използване на инструментите. Може да е удобно, когато искате да предоставите среда на база данни за тестове или разработка и да заредите данните си, но не е приложимо, когато наборът ви от данни е огромен. PostgreSQL трябва да изхвърли вашите данни една по една или да изпълни и приложи вашите данни последователно от двигателя на базата данни. Въпреки че можете да направите това слабо гъвкаво за ускоряване, като посочване на -j или използване на --single-transaction, за да избегнете въздействие върху вашата база данни, зареждането с SQL все още трябва да бъде анализирано от двигателя.
Освен това, документацията на PostgreSQL посочва следните ограничения, с нашите допълнения, докато наблюдавахме тези инструменти (pg_dump и pg_restore):
- Когато се възстановяват данни в вече съществуваща таблица и се използва опцията --disable-triggers, pg_restore излъчва команди за деактивиране на тригери в потребителски таблици, преди да вмъкне данните, след което издава команди, за да ги активира отново след като данните са били въведени. Ако възстановяването е спряно по средата, системните каталози може да са оставени в грешно състояние.
- pg_restore не може избирателно да възстанови големи обекти; например само тези за конкретна таблица. Ако архивът съдържа големи обекти, тогава всички големи обекти ще бъдат възстановени или нито един от тях, ако са изключени чрез -L, -t или други опции.
- Очаква се и двата инструмента да генерират огромно количество размери (файлове, директория или tar архив), особено за огромна база данни.
- За pg_dump, когато изхвърля една таблица или като обикновен текст, pg_dump не обработва големи обекти. Големите обекти трябва да се изхвърлят с цялата база данни, като се използва един от нетекстовите архивни формати.
- Ако имате tar архиви, генерирани от тези инструменти, имайте предвид, че tar архивите са ограничени до размер, по-малък от 8 GB. Това е присъщо ограничение на файловия формат tar. Следователно този формат не може да се използва, ако текстовото представяне на таблица надвишава този размер. Общият размер на tar архива и който и да е от другите изходни формати не е ограничен, освен евентуално от операционната система.
Използване на pg_restore
Използването на pg_restore е доста удобно и лесно за използване. Тъй като е сдвоен в тандем с pg_dump, и двата инструмента работят достатъчно добре, стига целевият изход да отговаря на другия. Например следният pg_dump няма да бъде полезен за pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Този резултат ще бъде съвместим с psql, който изглежда както следва:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Но това няма да успее за pg_restore, тъй като няма обикновен формат за следване:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerСега нека преминем към по-полезни термини за pg_restore.
pg_restore:Изпускане и възстановяване
Помислете за просто използване на pg_restore, при което имате пускане на база данни, напр.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Възстановяването му с pg_restore е много лесно,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump -C/--create тук посочва, че създава базата данни, след като се срещне в заглавката. -d postgres сочи към базата данни на postgres, но това не означава, че ще създаде таблиците към базата данни на postgres. Това изисква базата данни да съществува. Ако -C не е посочено, таблиците и записите ще се съхраняват в тази база данни, посочена с аргумент -d.
Селективно възстановяване по таблица
Възстановяването на таблица с pg_restore е лесно и просто. Например, имате две таблици, а именно таблици "b" и "d". Да приемем, че изпълнявате следната команда pg_dump по-долу,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Където съдържанието на тази директория ще изглежда както следва,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Ако искате да възстановите таблица (а именно "d" в този пример),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Ще има,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Копиране на таблици от база данни в различна база данни
Може дори да копирате съдържанието на съществуващата си база данни и да я имате в целевата си база данни. Например, имам следните бази данни,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Най-голямата база данни е празна база данни, докато ние ще копираме това, което е в базата данни на maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)За да го копираме, трябва да изхвърлим данните от базата данни maxtest, както следва,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: След това го заредете или възстановете, както следва,
Сега разполагаме с данни за най-добрата база данни и таблиците са съхранени съответно.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Генерирайте SQL файл с пренареждане
Виждал съм много използване на pg_restore, но изглежда, че тази функция обикновено не се показва. Намерих този подход за много интересен, тъй като ви позволява да поръчате въз основа на това, което не искате да включите, и след това да генерирате SQL файл от поръчката, която искате да продължите.
Например, ще използваме примерния pgdump_data.tar, който генерирахме по-рано, и ще създадем списък. За да направите това, изпълнете следната команда:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listТова ще генерира файл, както е показано по-долу:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresСега, нека го пренаредим или да кажем, че премахнах създаването на SEQUENCE, както и създаването на ограничението. Това ще изглежда по следния начин,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresЗа да генерирате файла в SQL формат, просто направете следното:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Сега файлът /tmp/selective_data.out ще бъде генериран от SQL файл и може да се чете, ако използвате psql, но не и pg_restore. Това, което е страхотно в това, е, че можете да генерирате SQL файл в съответствие с вашия шаблон, върху който данните могат да бъдат възстановени само от съществуващ архив или резервно копие, направено чрез pg_dump с помощта на pg_restore.
Възстановяване на PostgreSQL с ClusterControl
ClusterControl не използва pg_restore или pg_dump като част от своя набор от функции. Използваме pg_dumpall за генериране на логически архиви и, за съжаление, изходът не е съвместим с pg_restore.
Има няколко други начина за генериране на резервно копие в PostgreSQL, както се вижда по-долу.
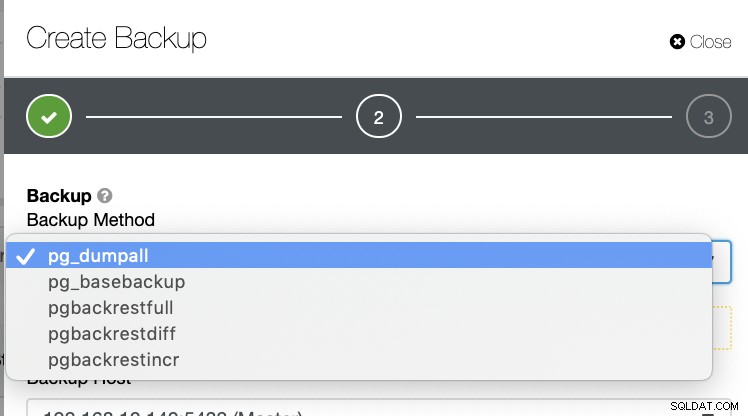
Няма такъв механизъм, при който можете избирателно да съхранявате таблица, база данни, или копирайте от една база данни в друга база данни.
ClusterControl поддържа Recovery Point-in-Time Recovery (PITR), но това не ви позволява да управлявате възстановяването на данни толкова гъвкаво, колкото с pg_restore. За целия списък с методи за архивиране само pg_basebackup и pgbackrest могат да PITR.
Как ClusterControl обработва възстановяването е, че има способността да възстанови неуспешен клъстер, стига автоматичното възстановяване да е активирано, както е показано по-долу.

След като главният се повреди, подчиненият може автоматично да възстанови клъстера, както ClusterControl изпълнява при отказ (което се извършва автоматично). За частта за възстановяване на данни единствената ви възможност е да имате възстановяване в целия клъстер, което означава, че идва от пълен архив. Няма възможност за селективно възстановяване на целевата база данни или таблица, която само искате да възстановите. Ако искате да направите това, възстановете пълния архив, лесно е да направите това с ClusterControl. Можете да отидете в разделите за архивиране, както е показано по-долу,
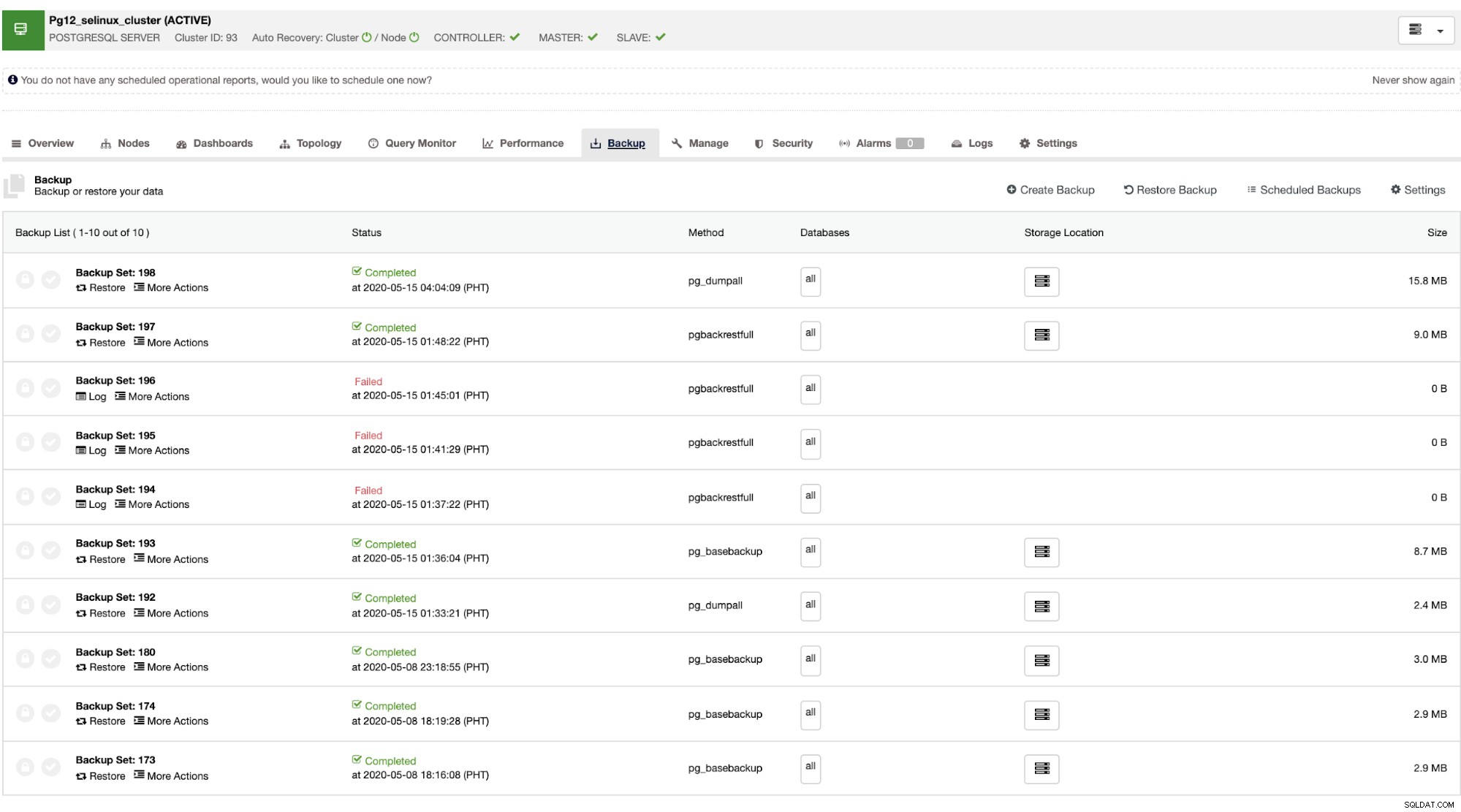
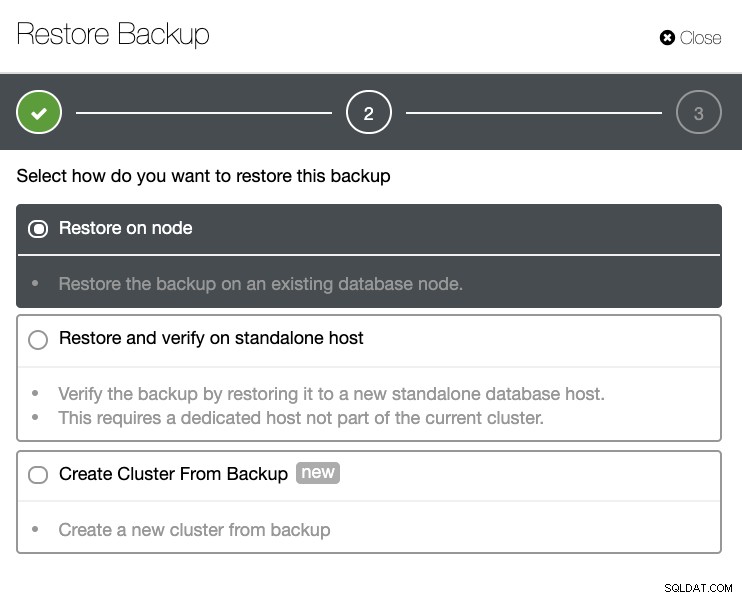
Ще имате пълен списък с успешни и неуспешни архиви. След това възстановяването може да стане, като изберете целевото архивиране и щракнете върху бутона „Възстановяване“. Това ще ви позволи да възстановите на съществуващ възел, регистриран в ClusterControl, или да проверите на самостоятелен възел, или да създадете клъстер от резервното копие.
Заключение
Използването на pg_dump и pg_restore опростява подхода за архивиране/думпиране и възстановяване. Въпреки това, за широкомащабна среда на база данни, това може да не е идеалният компонент за възстановяване след бедствие. За минимална процедура за избор и възстановяване, използването на комбинацията от pg_dump и pg_restore ви предоставя силата да изхвърляте и зареждате вашите данни според вашите нужди.
За производствени среди (особено за корпоративни архитектури) можете да използвате подхода ClusterControl, за да създадете резервно копие и възстановяване с автоматично възстановяване.
Комбинацията от подходи също е добър подход. Това ви помага да намалите RTO и RPO и в същото време да използвате най-гъвкавия начин за възстановяване на вашите данни, когато е необходимо.