В днешно време е обичайно да виждате голямо количество данни в базата данни на компанията, но в зависимост от размера може да е трудно да се управлява и производителността може да бъде засегната при голям трафик, ако не я конфигурираме или внедрим по правилен начин . Като цяло, ако имаме огромна база данни и искаме да имаме ниско време за реакция, ще искаме да я мащабираме. PostgreSQL не е изключение в тази точка. Има много налични подходи за мащабиране на PostgreSQL, но първо, нека научим какво е мащабиране.
Мащабируемостта е свойството на система/база данни да се справя с нарастващия брой изисквания чрез добавяне на ресурси.
Причините за това количество искания могат да бъдат временни, например, ако стартираме отстъпка при разпродажба, или постоянни, за увеличаване на клиенти или служители. Във всеки случай трябва да можем да добавяме или премахваме ресурси, за да управляваме тези промени в зависимост от изискванията или увеличаването на трафика.
В този блог ще разгледаме как можем да мащабираме нашата PostgreSQL база данни и кога трябва да го направим.
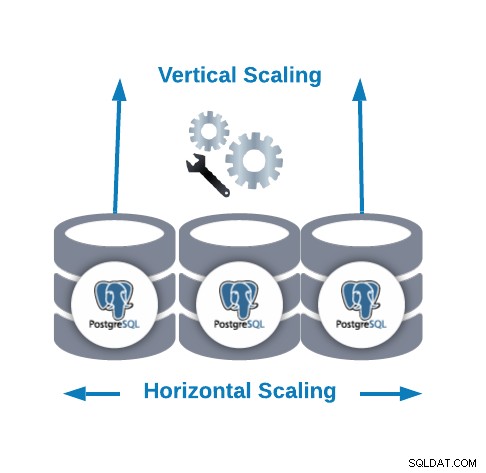
Хоризонтално мащабиране срещу вертикално мащабиране
Има два основни начина за мащабиране на нашата база данни...
- Хоризонтално мащабиране (намаляване):Извършва се чрез добавяне на още възли на базата данни, създавайки или увеличавайки клъстер от база данни.
- Вертикално мащабиране (увеличаване):Извършва се чрез добавяне на повече хардуерни ресурси (CPU, памет, диск) към съществуващ възел на базата данни.
За хоризонтално мащабиране можем да добавим още възли на базата данни като подчинени възли. Може да ни помогне да подобрим производителността на четене, балансирайки трафика между възлите. В този случай ще трябва да добавим балансьор на натоварването, за да разпределим трафика към правилния възел в зависимост от правилата и състоянието на възела.
За да избегнем една точка на неизправност, добавяйки само един балансьор на натоварване, трябва да помислим за добавяне на два или повече възли за балансиране на натоварването и използване на някакъв инструмент като „Keepalived“, за да гарантираме наличността.
Тъй като PostgreSQL няма собствена поддръжка за няколко главни, ако искаме да я внедрим, за да подобрим производителността на запис, ще трябва да използваме външен инструмент за тази задача.
За вертикално мащабиране може да се наложи да промените някакъв конфигурационен параметър, за да позволите на PostgreSQL да използва нов или по-добър хардуерен ресурс. Нека видим някои от тези параметри от документацията на PostgreSQL.
- work_mem:Определя количеството памет, което да се използва от вътрешни операции за сортиране и хеш таблици, преди да се записва във временни дискови файлове. Няколко работещи сесии биха могли да извършват подобни операции едновременно, така че общата използвана памет може да бъде многократно по-голяма от стойността на work_mem.
- maintenance_work_mem:Указва максималното количество памет, което да се използва от операции по поддръжка, като ВАКУУМ, СЪЗДАВАНЕ НА ИНДЕКС и ПРОМЕНЯНЕ НА ТАБЛИЦАТА, ДОБАВЯНЕ НА ВЪНШЕН КЛЮЧ. По-големите настройки може да подобрят производителността при почистване с прахосмукачка и за възстановяване на дъмпове на база данни.
- autovacuum_work_mem:Посочва максималното количество памет, което да се използва от всеки работен процес за автоматично вакуумиране.
- autovacuum_max_workers:Посочва максималния брой процеси за автоматично вакуумиране, които могат да се изпълняват по всяко време.
- max_worker_processes:Задава максималния брой фонови процеси, които системата може да поддържа. Посочете границите на процеса, като вакуумиране, контролни точки и други задачи за поддръжка.
- max_parallel_workers:Задава максималния брой работници, които системата може да поддържа за паралелни операции. Паралелните работници се вземат от групата работни процеси, установени от предишния параметър.
- max_parallel_maintenance_workers:Задава максималния брой паралелни работници, които могат да бъдат стартирани от една команда на помощната програма. Понастоящем единствената команда за паралелна помощна програма, която поддържа използването на паралелни работници, е CREATE INDEX и то само при изграждане на индекс на B-дърво.
- effective_cache_size:Задава предположението на планиращия за ефективния размер на дисковия кеш, който е достъпен за една заявка. Това се взема предвид в оценките на разходите за използване на индекс; по-висока стойност прави по-вероятно да се използват индексни сканирания, по-ниска стойност прави по-вероятно да се използват последователни сканирания.
- shared_buffers:Задава количеството памет, която сървърът на базата данни използва за споделени буфери на паметта. За добра производителност обикновено са необходими настройки, значително по-високи от минималните.
- temp_buffers:Задава максималния брой временни буфери, използвани от всяка сесия на база данни. Това са локални буфери за сесия, използвани само за достъп до временни таблици.
- effective_io_concurrency:Задава броя на едновременните дискови I/O операции, които PostgreSQL очаква да могат да бъдат изпълнени едновременно. Повишаването на тази стойност ще увеличи броя на I/O операциите, които всяка отделна сесия на PostgreSQL се опитва да инициира паралелно. Понастоящем тази настройка засяга само сканирането на растерни карти.
- max_connections:Определя максималния брой едновременни връзки към сървъра на базата данни. Увеличаването на този параметър позволява на PostgreSQL да изпълнява повече бекенд процеси едновременно.
В този момент има въпрос, който трябва да зададем. Как можем да разберем дали трябва да мащабираме нашата база данни и как можем да знаем най-добрия начин да го направим?
Наблюдение
Мащабирането на нашата PostgreSQL база данни е сложен процес, така че трябва да проверим някои показатели, за да можем да определим най-добрата стратегия за нейното мащабиране.
Можем да наблюдаваме използването на процесора, паметта и диска, за да определим дали има някакъв проблем с конфигурацията или ако всъщност, трябва да мащабираме нашата база данни. Например, ако виждаме голямо натоварване на сървъра, но активността на базата данни е ниска, вероятно не е необходимо да я мащабираме, трябва само да проверим параметрите на конфигурацията, за да ги съпоставим с нашите хардуерни ресурси.
Проверката на дисковото пространство, използвано от възела PostgreSQL на база данни, може да ни помогне да потвърдим дали имаме нужда от повече диск или дори разделяне на таблица. За да проверим дисковото пространство, използвано от база данни/таблица, можем да използваме някаква функция на PostgreSQL като pg_database_size или pg_table_size.
От страната на базата данни трябва да проверим
- Обем на връзката
- Изпълнение на заявки
- Използване на индекс
- Подуване
- Закъснение при репликация
Това може да са ясни показатели за потвърждение дали е необходимо мащабирането на нашата база данни.
ClusterControl като система за мащабиране и наблюдение
ClusterControl може да ни помогне да се справим и с двата начина на мащабиране, които видяхме по-рано, и да наблюдаваме всички необходими показатели, за да потвърдим изискването за мащабиране. Да видим как...
Ако все още не използвате ClusterControl, можете да го инсталирате и да разположите или импортирате текущата си PostgreSQL база данни, като изберете опцията „Импортиране“ и следвайте стъпките, за да се възползвате от всички функции на ClusterControl като архивиране, автоматично превключване при отказ, сигнали, наблюдение, и още.
Хоризонтално мащабиране
За хоризонтално мащабиране, ако отидем в действията на клъстера и изберем „Добавяне на подчинен за репликация“, можем или да създадем нова реплика от нулата, или да добавим съществуваща PostgreSQL база данни като реплика.
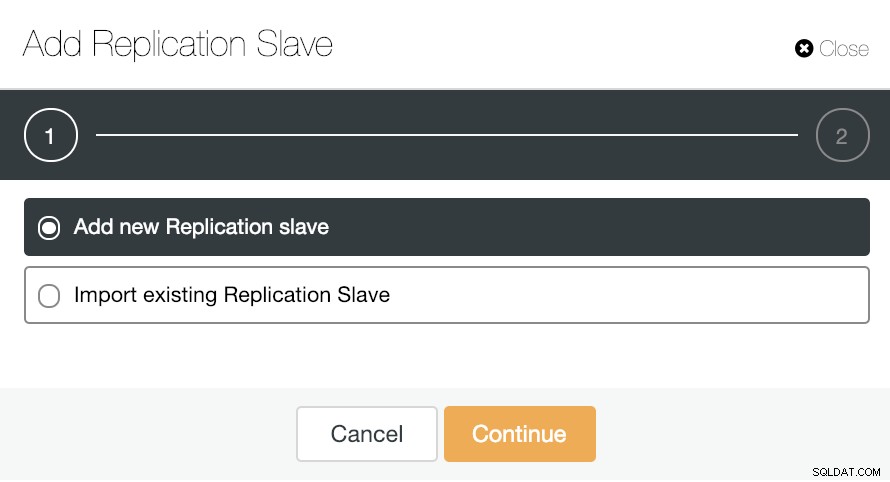
Нека видим как добавянето на нов подчинен репликация може да бъде наистина лесна задача.
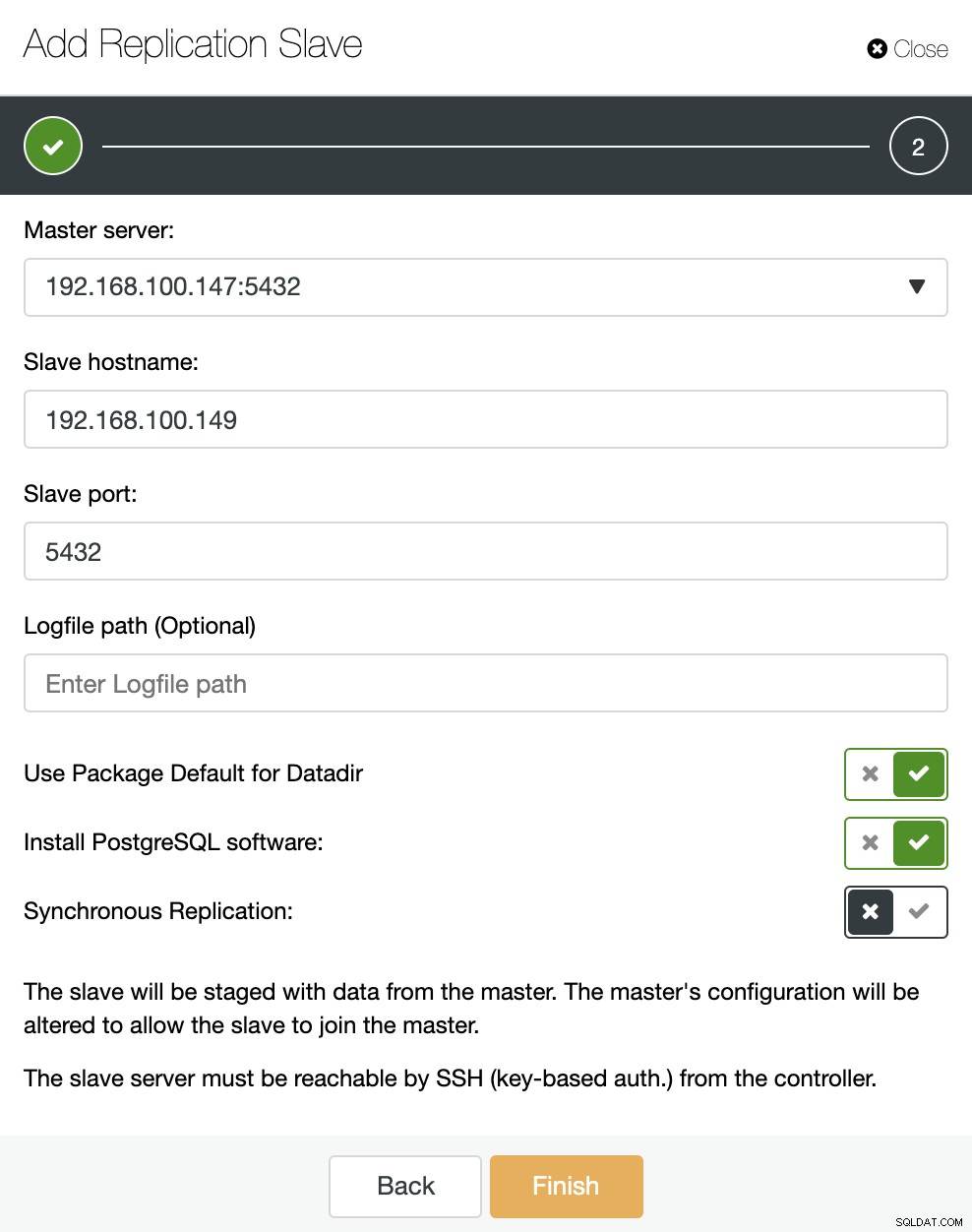
Както можете да видите на изображението, трябва само да изберем нашия главен сървър, да въведете IP адреса за нашия нов подчинен сървър и порта на базата данни. След това можем да изберем дали искаме ClusterControl да инсталира софтуера вместо нас и дали подчинената за репликация да бъде синхронна или асинхронна.
По този начин можем да добавим толкова копия, колкото искаме, и да разпределим трафика за четене между тях с помощта на балансьор на натоварване, който също можем да приложим с ClusterControl.
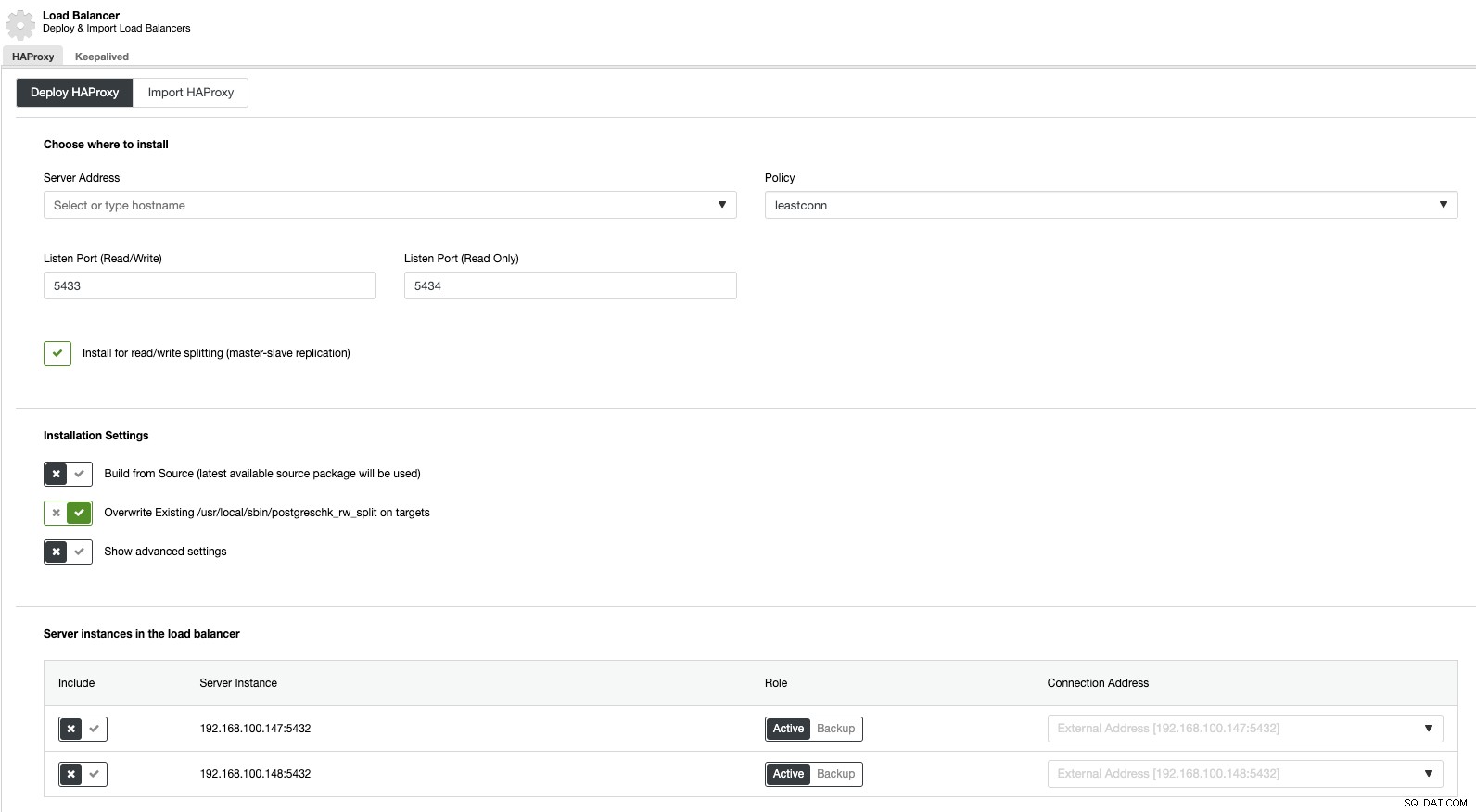
Сега, ако отидем в действията на клъстера и изберем „Добавяне на Load Balancer“, можем да разположим нов HAProxy Load Balancer или да добавим съществуващ.
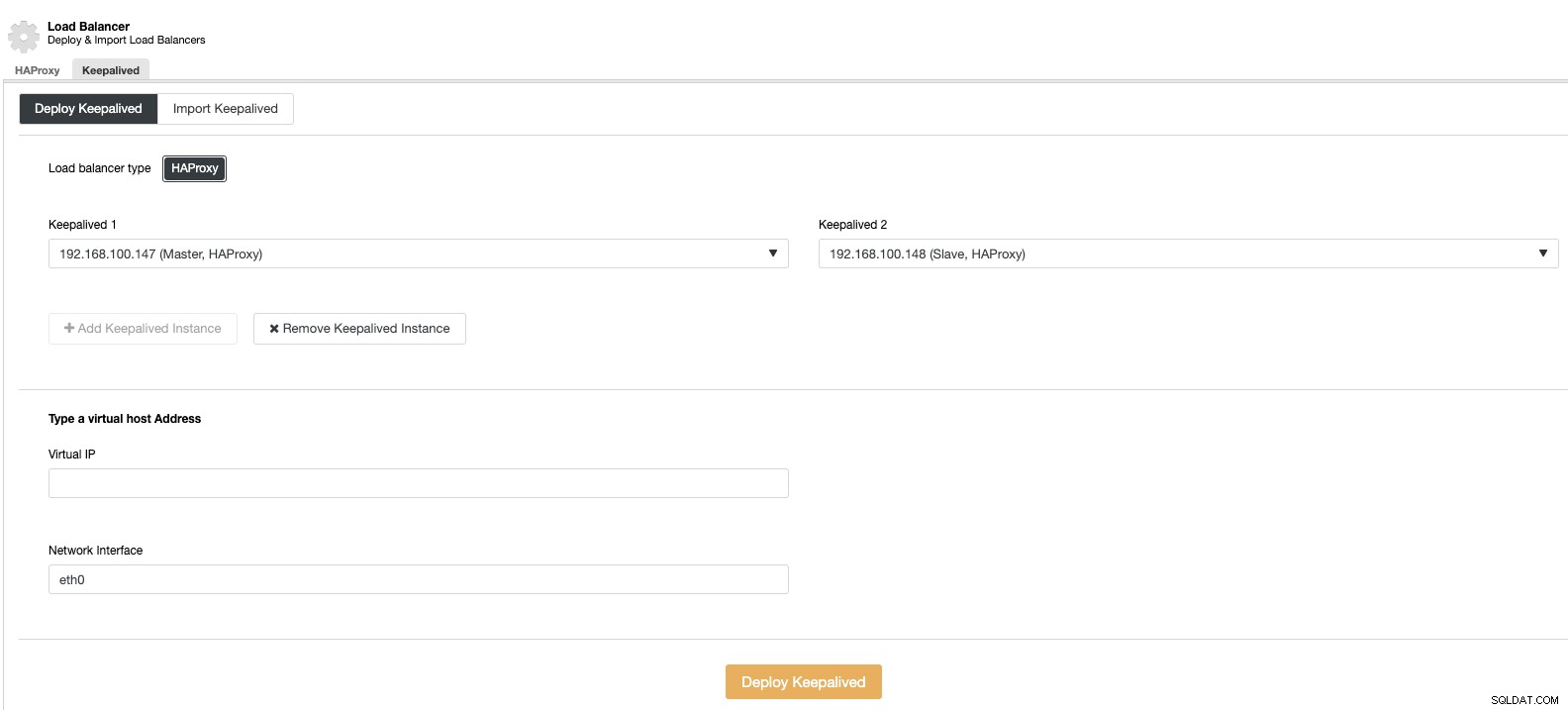
И след това, в същата секция за балансиране на натоварването, можем да добавим услуга Keepalived, работеща на възлите за балансиране на натоварването, за да подобрим нашата среда с висока наличност.
Вертикално мащабиране
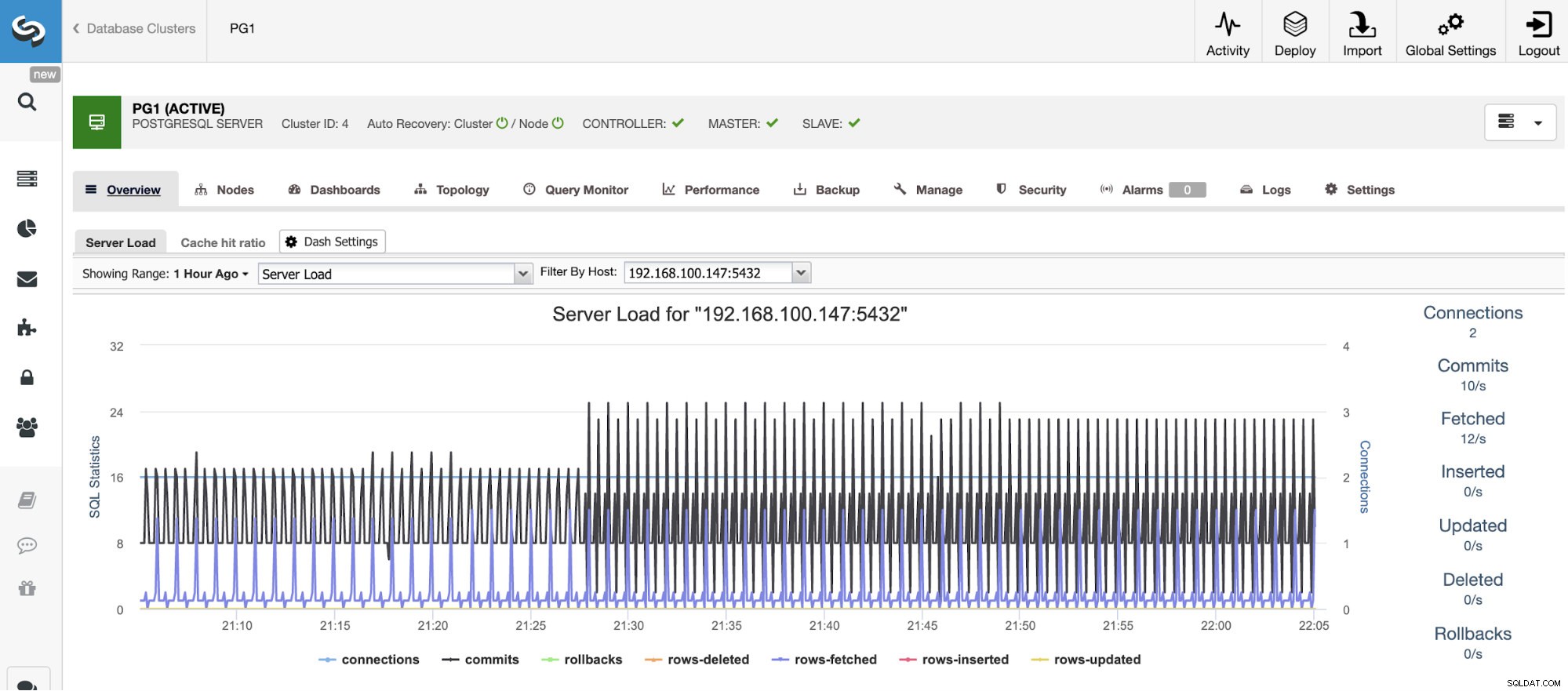
За вертикално мащабиране с ClusterControl можем да наблюдаваме нашите възли на базата данни както от операционната система, така и от страната на базата данни. Можем да проверим някои показатели като използване на процесора, памет, връзки, водещи заявки, изпълнявани заявки и дори повече. Можем също да активираме раздела Табло за управление, което ни позволява да виждаме показателите по-подробно и по-приятелски начин.
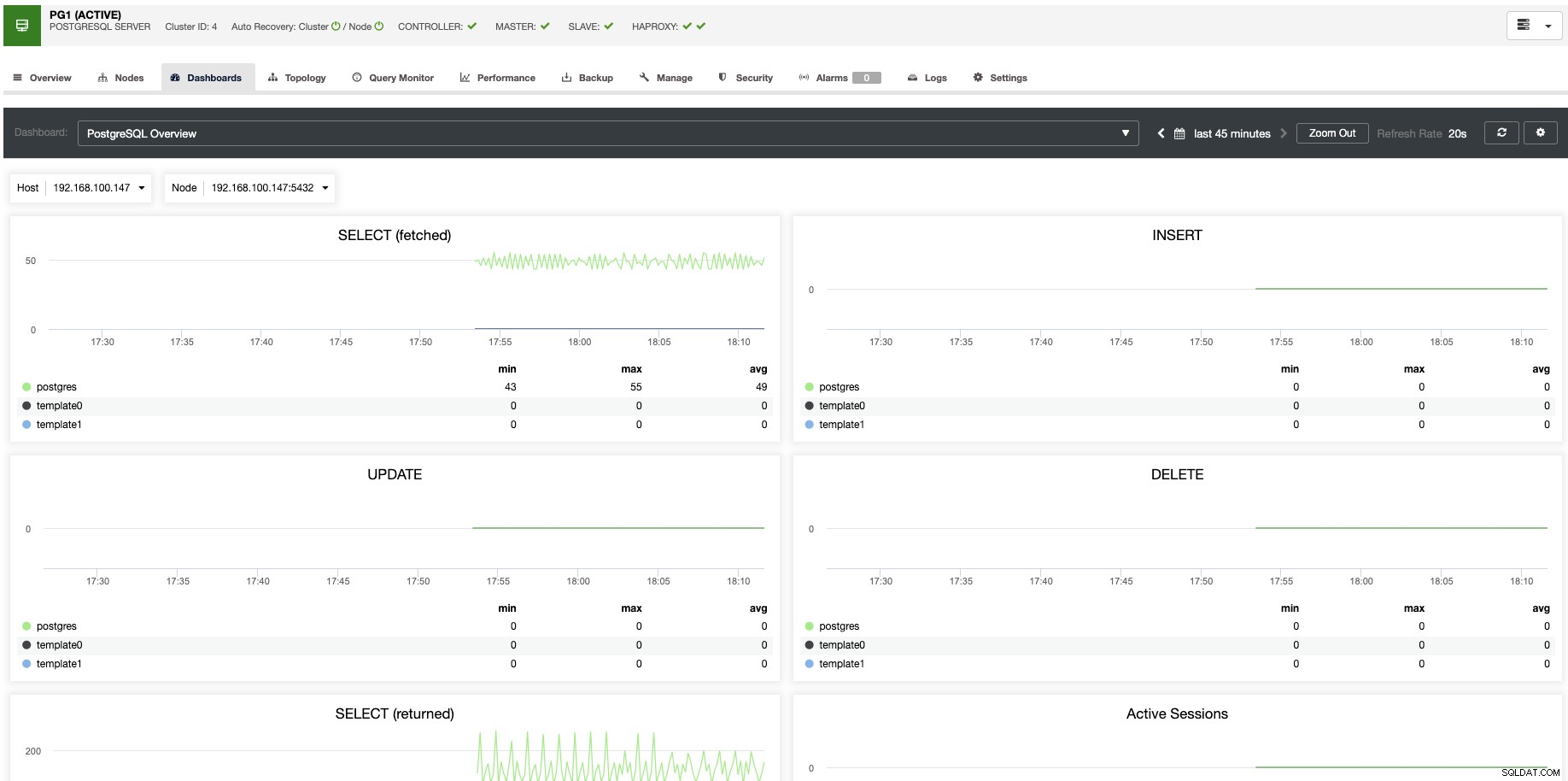
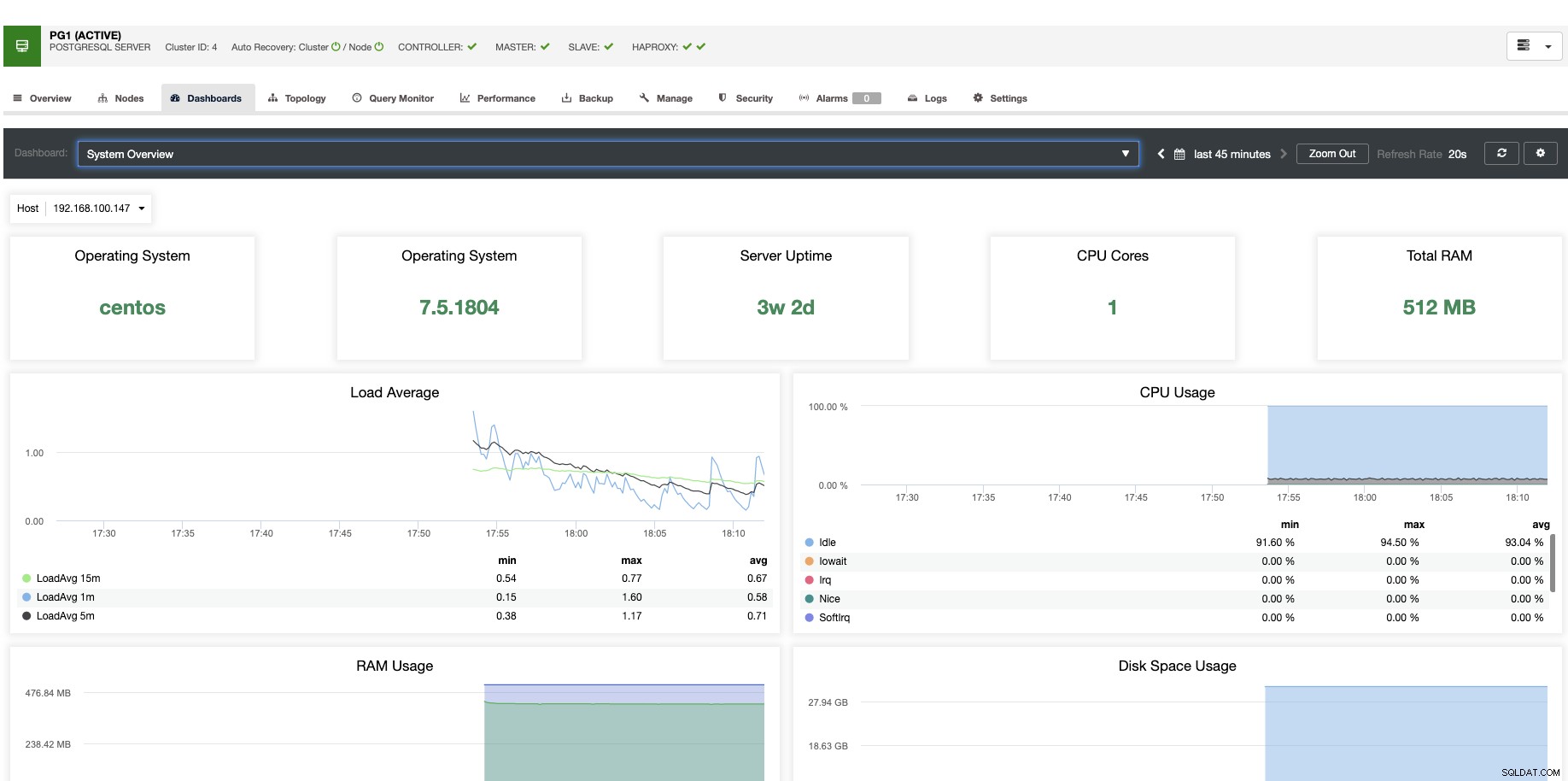
От ClusterControl можете също да изпълнявате различни задачи за управление, като рестартиране на хост, повторно изграждане на подчинено устройство за репликация или популяризиране на подчинено с едно щракване.
Заключение
Мащабирането на PostgreSQL бази данни може да бъде трудоемка задача. Трябва да знаем какво трябва да мащабираме и кой е най-добрият начин да го направим. В крайна сметка ръчното управление и мащабиране на клъстери става доста обременяващо след определен момент, така че повечето се обръщат към инструменти като нашия.
Ако изберете ръчния маршрут, проверете кога да помислите за добавяне на допълнителен възел към вашия клъстер. Искате ли да избегнете неприятностите? Оценете ClusterControl безплатно в продължение на 30 дни, за да видите как неговите функции правят справянето с голям мащаб с отворен код лесно и ефективно.
Въпреки това искате да управлявате и мащабирате базите си данни, следвайте ни в Twitter или LinkedIn или се абонирайте за нашия бюлетин, за да получавате най-новите новини и най-добри практики при управление на инфраструктура на база данни с отворен код и ще се видим скоро!