В предишния ми блог обсъдихме различни начини за избор или сканиране на данни от една таблица. Но на практика извличането на данни от една таблица не е достатъчно. Това изисква избор на данни от множество таблици и след това корелиране между тях. Съотношението на тези данни между таблиците се нарича свързване на таблици и може да се извърши по различни начини. Тъй като свързването на таблици изисква входни данни (напр. от сканирането на таблицата), то никога не може да бъде листов възел в генерирания план.
Напр. разгледайте прост пример за заявка като SELECT * FROM TBL1, TBL2 където TBL1.ID> TBL2.ID; и да предположим, че генерираният план е както следва:
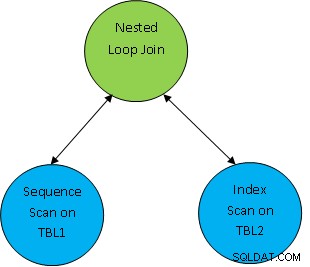
Така че тук първите и двете таблици се сканират и след това се обединяват като според условието на корелация като TBL.ID> TBL2.ID
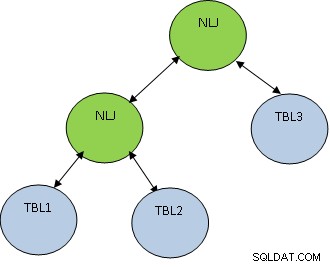
В допълнение към метода на присъединяване, редът на присъединяване също е много важен. Помислете за примера по-долу:
ИЗБЕРЕТЕ * ОТ TBL1, TBL2, TBL3, КЪДЕТО TBL1.ID=TBL2.ID И TBL2.ID=TBL3.ID;
Имайте предвид, че TBL1, TBL2 И TBL3 имат съответно 10, 100 и 1000 записа.
Условието TBL1.ID=TBL2.ID връща само 5 записа, докато TBL2.ID=TBL3.ID връща 100 записа, след което е по-добре първо да се присъедините към TBL1 и TBL2, така че да получи по-малък брой записи се присъедини към TBL3. Планът ще бъде както е показано по-долу:
PostgreSQL поддържа следния вид обединения:
- Присъединяване на вложен цикъл
- Присъединяване към хеш
- Сливане на присъединяване
Всеки от тези методи на присъединяване е еднакво полезен в зависимост от заявката и други параметри, напр. заявка, таблични данни, клауза за присъединяване, селективност, памет и т.н. Тези методи за присъединяване се прилагат от повечето релационни бази данни.
Нека създадем таблица за предварителна настройка и да попълним някои данни, които ще се използват често за по-добро обяснение на тези методи за сканиране.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEВъв всичките ни следващи примери ние разглеждаме конфигурационния параметър по подразбиране, освен ако не е посочено друго.
Присъединяване на вложен цикъл
Присъединяването на вложен цикъл (NLJ) е най-простият алгоритъм за присъединяване, при който всеки запис на външна връзка се съпоставя с всеки запис на вътрешна връзка. Съединяването между релация A и B с условие A.ID Присъединяването на вложен цикъл (NLJ) е най-често срещаният метод за присъединяване и може да се използва за почти всеки набор от данни с всякакъв тип клауза за присъединяване. Тъй като този алгоритъм сканира всички кортежи от вътрешна и външна връзка, се счита за най-скъпата операция за свързване. Съгласно горната таблица и данни, следната заявка ще доведе до присъединяване на вложен цикъл, както е показано по-долу: Тъй като клаузата за присъединяване е „<“, единственият възможен метод за присъединяване тук е присъединяване на вложен цикъл. Забележете тук един нов вид възел като Materialize; този възел действа като кеш на междинния резултат, т.е. вместо да извлича всички кортежи на релация многократно, първият извлечен резултат се съхранява в паметта и при следващата заявка за получаване на кортеж ще бъде обслужен от паметта, вместо да се извлича отново от страниците с релации . В случай, че всички кортежи не могат да се поберат в паметта, тогава кортежите за преливане отиват във временен файл. Това е най-вече полезно в случай на присъединяване на вложен цикъл и до известна степен в случай на Merge Join, тъй като те разчитат на повторно сканиране на вътрешна връзка. Materialize Node не е ограничен само до кеширане на резултата от релацията, но може да кешира резултатите от всеки възел по-долу в дървото на плана. СЪВЕТ:В случай, че клаузата за присъединяване е „=“ и е избрано присъединяване на вложен цикъл между релация, тогава е наистина важно да се проучи дали може да се избере по-ефективен метод за свързване, като например хеширане или свързване с обединяване, от настройка на конфигурацията (напр. work_mem, но не само) или чрез добавяне на индекс и т.н. Някои от заявките може да нямат клауза за присъединяване, в този случай единственият избор за присъединяване е присъединяването на вложен цикъл. напр. разгледайте следните заявки според данните за предварителна настройка: Съединяването в горния пример е просто декартово произведение на двете таблици. Този алгоритъм работи на две фази: Съединението между релация A и B с условие A.ID =B.ID може да бъде представено по-долу: Съгласно по-горе таблица и данни за предварителна настройка, следната заявка ще доведе до хеш присъединяване, както е показано по-долу: Тук хеш таблицата се създава в таблицата blogtable2, защото това е по-малката таблица, така че минималната памет, необходима за хеш таблицата и цялата хеш таблица, може да се побере в паметта. Обединяването при сливане е алгоритъм, при който всеки запис на външна връзка се съпоставя с всеки запис на вътрешна връзка, докато има възможност за съвпадение на клауза за присъединяване. Този алгоритъм за присъединяване се използва само ако и двете отношения са сортирани и операторът на клаузата за присъединяване е „=“. Съединението между релация A и B с условие A.ID =B.ID може да бъде представено по-долу: Примерната заявка, която доведе до хеш присъединяване, както е показано по-горе, може да доведе до обединяване с обединяване, ако индексът бъде създаден и в двете таблици. Това е така, защото данните от таблицата могат да бъдат извлечени в сортиран ред поради индекса, който е един от основните критерии за метода на обединяване на сливане: И така, както виждаме, и двете таблици използват индексно сканиране вместо последователно сканиране, поради което и двете таблици ще излъчват сортирани записи. PostgreSQL поддържа различни конфигурации, свързани с планиране, които могат да се използват за намек на оптимизатора на заявки да не избира някакъв конкретен вид методи за присъединяване. Ако методът на присъединяване, избран от оптимизатора, не е оптимален, тогава тези конфигурационни параметри могат да бъдат изключени, за да принуди оптимизатора на заявки да избере различен вид методи за присъединяване. Всички тези конфигурационни параметри са „включени“ по подразбиране. По-долу са параметрите на конфигурацията на планировщика, специфични за методите на присъединяване. Има много конфигурационни параметри, свързани с плана, използвани за различни цели. В този блог се ограничава само до методи за присъединяване. Тези параметри могат да се променят от конкретна сесия. Така че, в случай че искаме да експериментираме с плана от конкретна сесия, тогава тези конфигурационни параметри могат да бъдат манипулирани и другите сесии ще продължат да работят както са. Сега разгледайте горните примери за свързване с обединяване и хеш присъединяване. Без индекс, оптимизаторът на заявки избра Hash Join за заявката по-долу, както е показано по-долу, но след използване на конфигурацията, той превключва към обединяване с обединяване дори без индекс: Първоначално се избира Hash Join, тъй като данните от таблиците не са сортирани. За да избере плана за присъединяване за сливане, той трябва първо да сортира всички записи, извлечени от двете таблици, и след това да приложи присъединяването за сливане. Така че цената на сортирането ще бъде допълнителна и следователно общата цена ще се увеличи. Така че вероятно в този случай общата (включително увеличената) цена е повече от общата цена на Hash Join, така че е избрано Hash Join. След като конфигурационният параметър enable_hashjoin бъде променен на „off“, това означава, че оптимизаторът на заявки директно присвоява цена за хеш присъединяване като цена за деактивиране (=1.0e10, т.е. 10000000000.00). Цената на всяко възможно присъединяване ще бъде по-малка от тази. Така че, същият резултат от заявката в Merge Join след enable_hashjoin е променен на „off“, тъй като дори да се включи цената за сортиране, общата цена на обединяването е по-малка от цената за деактивиране. Сега разгледайте примера по-долу: Както можем да видим по-горе, въпреки че свързаният с вложен цикъл конфигурационен параметър е променен на „изключено“, той все пак избира Присъединяване на вложен цикъл, тъй като няма алтернативна възможност за друг вид метод на присъединяване за получаване избрани. По-просто казано, тъй като Nested Loop Join е единственото възможно присъединяване, тогава каквато и да е цената, то винаги ще бъде победител (Същото както преди бях победител в състезание на 100 метра, ако бягах сам...:-)). Също така забележете разликата в цената в първия и втория план. Първият план показва действителната цена на присъединяването на вложен цикъл, но вторият показва цената за деактивиране на същото. Всички видове методи за присъединяване на PostgreSQL са полезни и се избират въз основа на естеството на заявката, данните, клаузата за присъединяване и т.н. В случай, че заявката не се изпълнява според очакванията, т.е. методите за присъединяване не са избрани според очакванията тогава, потребителят може да си играе с различни налични параметри за конфигурация на плана и да види дали нещо липсва.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Присъединяване към хеш
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Присъединяване към сливане
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Конфигурация
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Заключение



