Управлението на трафика към базата данни може да стане все по-трудно, тъй като количеството му се увеличава и базата данни всъщност се разпределя между множество сървъри. PostgreSQL клиентите обикновено говорят с една крайна точка. Когато първичен възел се повреди, клиентите на базата данни ще продължат да опитват отново същия IP. В случай, че сте се свързали с вторичен възел, приложението трябва да бъде актуализирано с новата крайна точка. Това е мястото, където бихте искали да поставите балансьор на натоварването между приложенията и екземплярите на базата данни. Той може да насочва приложенията към налични/изправни възли на базата данни и да преминава при отказ, когато е необходимо. Друго предимство би било да се увеличи производителността на четене чрез ефективно използване на реплики. Възможно е да се създаде порт само за четене, който балансира четенията в репликите. В този блог ще разгледаме HAProxy. Ще видим какво е, как работи и как да го разположим за PostgreSQL.
Какво е HAProxy?
HAProxy е прокси сървър с отворен код, който може да се използва за внедряване на висока наличност, балансиране на натоварването и прокси за TCP и HTTP базирани приложения.
Като средство за балансиране на натоварването, HAProxy разпределя трафик от един източник към една или повече дестинации и може да дефинира специфични правила и/или протоколи за тази задача. Ако някоя от дестинациите спре да отговаря, тя се маркира като офлайн и трафикът се изпраща към останалите налични дестинации.
Как да инсталирате и конфигурирате HAProxy ръчно
За да инсталирате HAProxy на Linux, можете да използвате следните команди:
На Ubuntu/Debian OS:
$ apt-get install haproxy -yНа CentOS/RedHat OS:
$ yum install haproxy -yСлед това трябва да редактираме следния конфигурационен файл, за да управляваме конфигурацията на HAProxy:
$ /etc/haproxy/haproxy.cfgКонфигурирането на нашия HAProxy не е сложно, но трябва да знаем какво правим. Имаме няколко параметъра за конфигуриране, в зависимост от това как искаме да работи HAProxy. За повече информация можем да проследим документацията относно конфигурацията на HAProxy.
Нека разгледаме пример за основна конфигурация. Да предположим, че имате следната топология на базата данни:
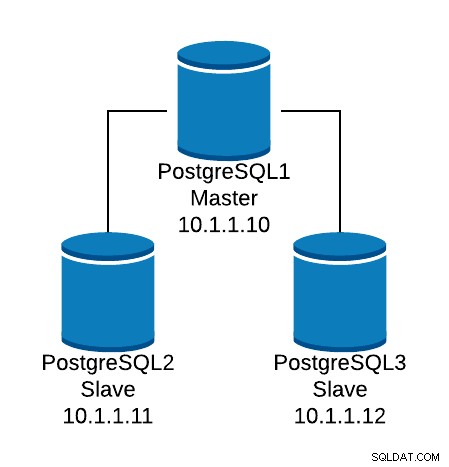 Пример за топология на базата данни
Пример за топология на базата данни Искаме да създадем HAProxy слушател, който да балансира трафика за четене между трите възела.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkКакто споменахме по-рано, тук има няколко параметъра за конфигуриране и тази конфигурация зависи от това, което искаме да направим. Например:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkКак работи HAProxy на ClusterControl
За PostgreSQL HAProxy се конфигурира от ClusterControl с два различни порта по подразбиране, един за четене и запис и един само за четене.
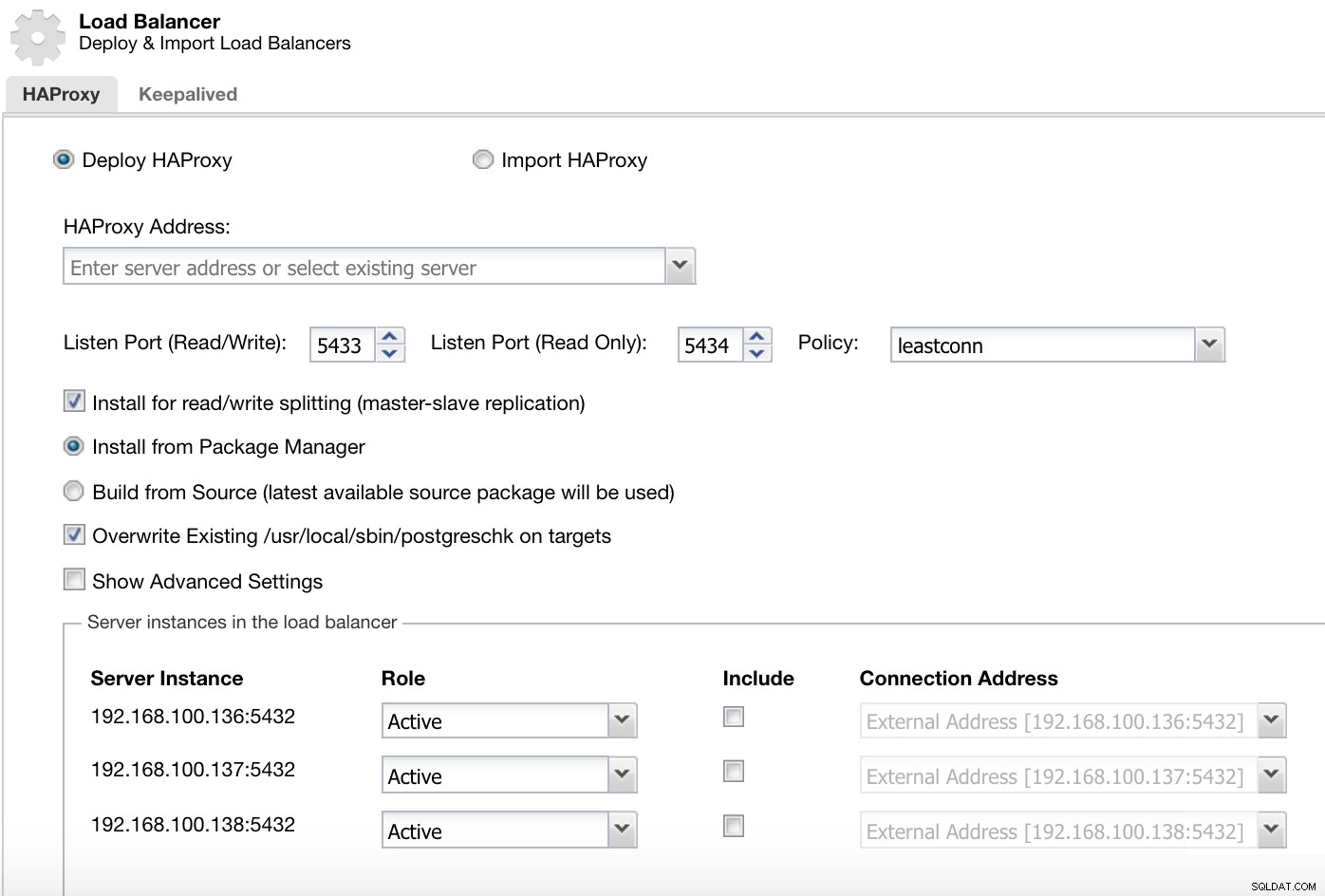 Информация за внедряване на ClusterControl Load Balancer 1
Информация за внедряване на ClusterControl Load Balancer 1 В нашия порт за четене и запис имаме нашия главен сървър като онлайн, а останалите ни възли като офлайн, а в порта само за четене имаме и главният, и подчинените онлайн.
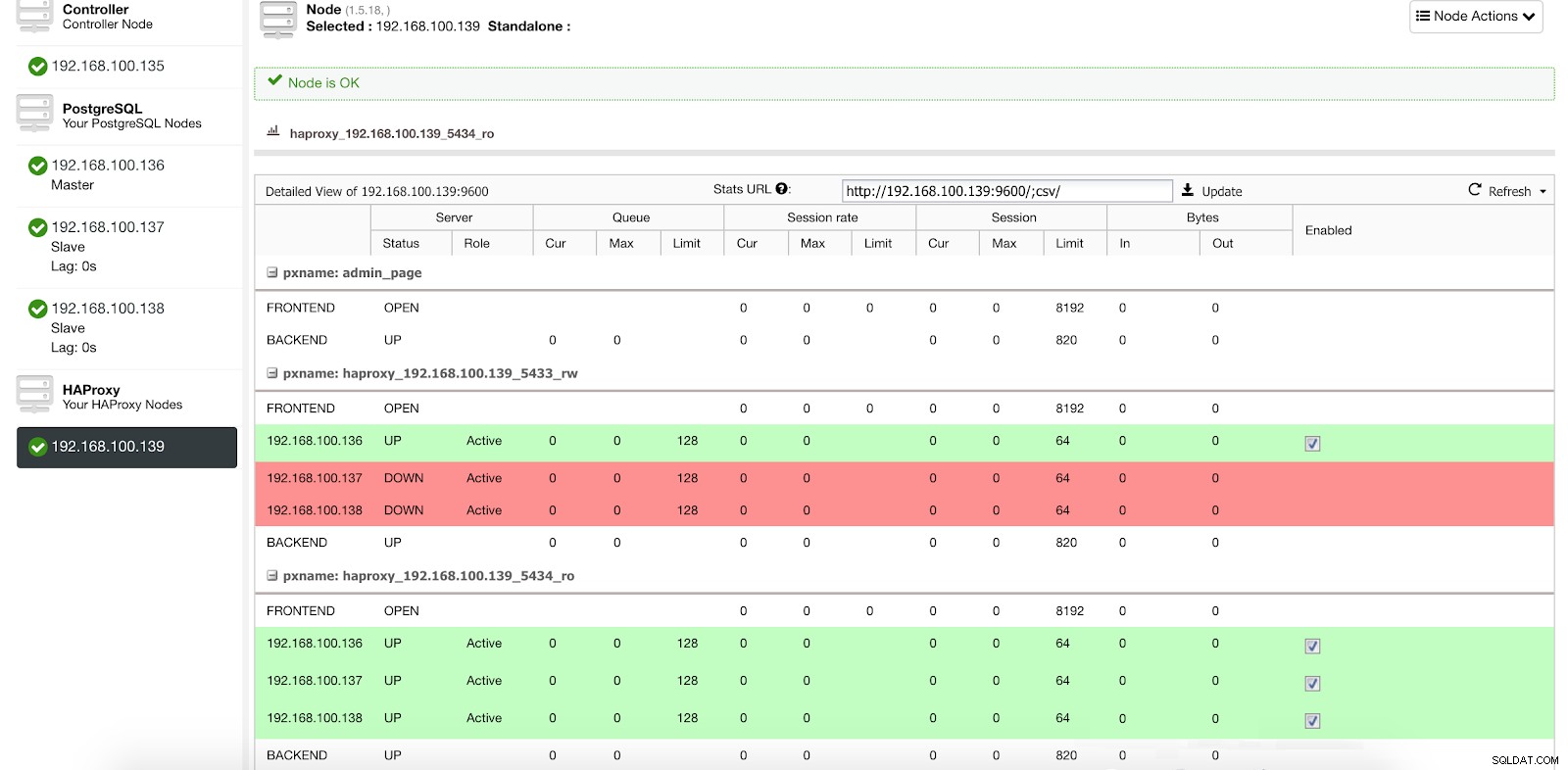 Статистика на ClusterControl Load Balancer 1
Статистика на ClusterControl Load Balancer 1 Когато HAProxy открие, че един от нашите възли, главен или подчинен, не е достъпен, той автоматично го маркира като офлайн и не го взема предвид при изпращане на трафик. Откриването се извършва от скриптове за проверка на здравето, които са конфигурирани от ClusterControl в момента на внедряването. Те проверяват дали екземплярите са актуални, дали са в процес на възстановяване или са само за четене.
Когато ClusterControl повиши подчинен в главен, нашият HAProxy маркира стария главен сървър като офлайн (и за двата порта) и поставя повишения възел онлайн (в порта за четене-запис).
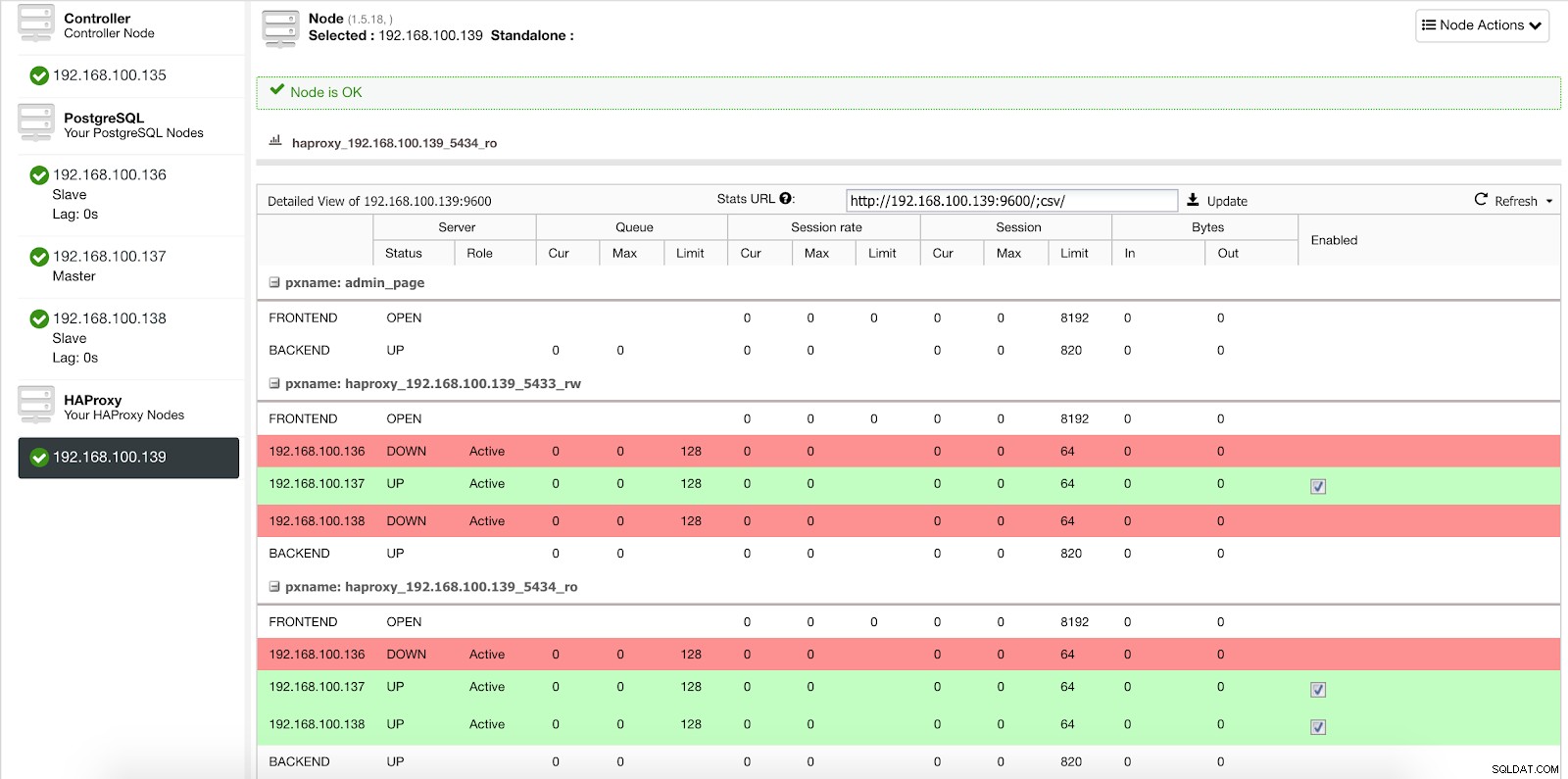 ClusterControl Load Balancer Stats 2
ClusterControl Load Balancer Stats 2 По този начин нашите системи продължават да работят нормално и без наша намеса.
Как да разположите HAProxy с ClusterControl
В нашия пример създадохме среда с 1 главен и 2 подчинени - вижте екранна снимка на изгледа на топологията в ClusterControl. Сега ще добавим нашия HAProxy балансьор на натоварване.
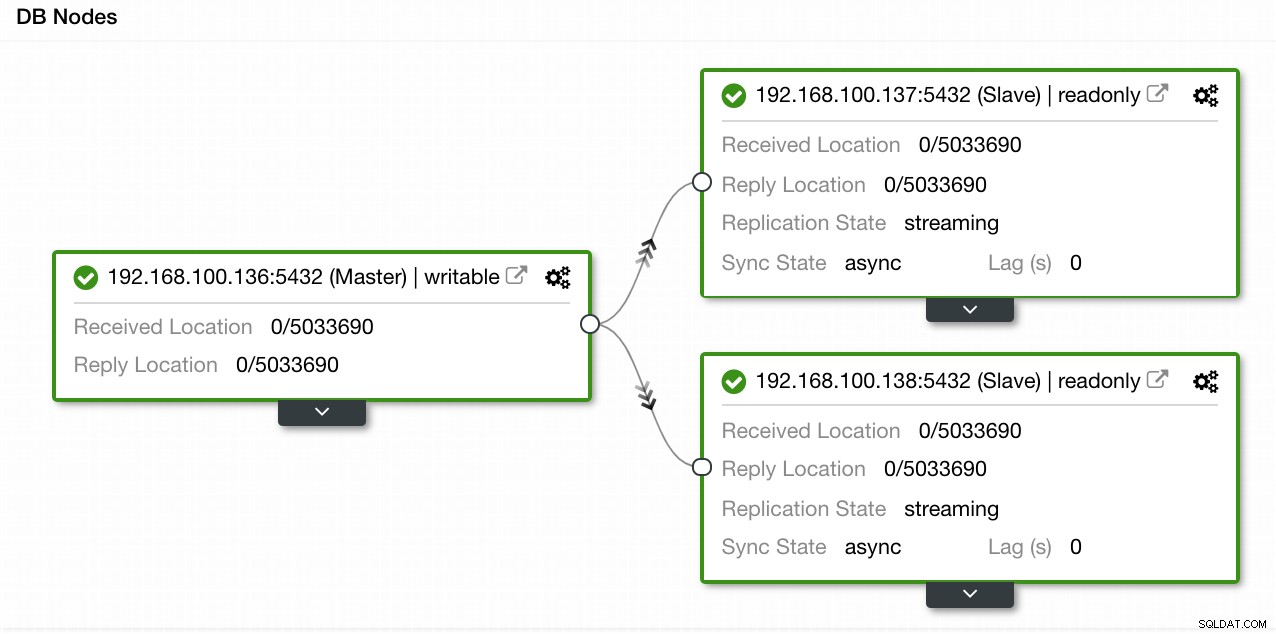 ClusterControl Topology View 1
ClusterControl Topology View 1 За тази задача трябва да отидем в ClusterControl -> PostgreSQL Cluster Actions -> Add Load Balancer
 Меню за действия на клъстера на ClusterControl
Меню за действия на клъстера на ClusterControl Тук трябва да добавим информацията, която ClusterControl ще използва за инсталиране и конфигуриране на нашия HAProxy балансьор на натоварване.
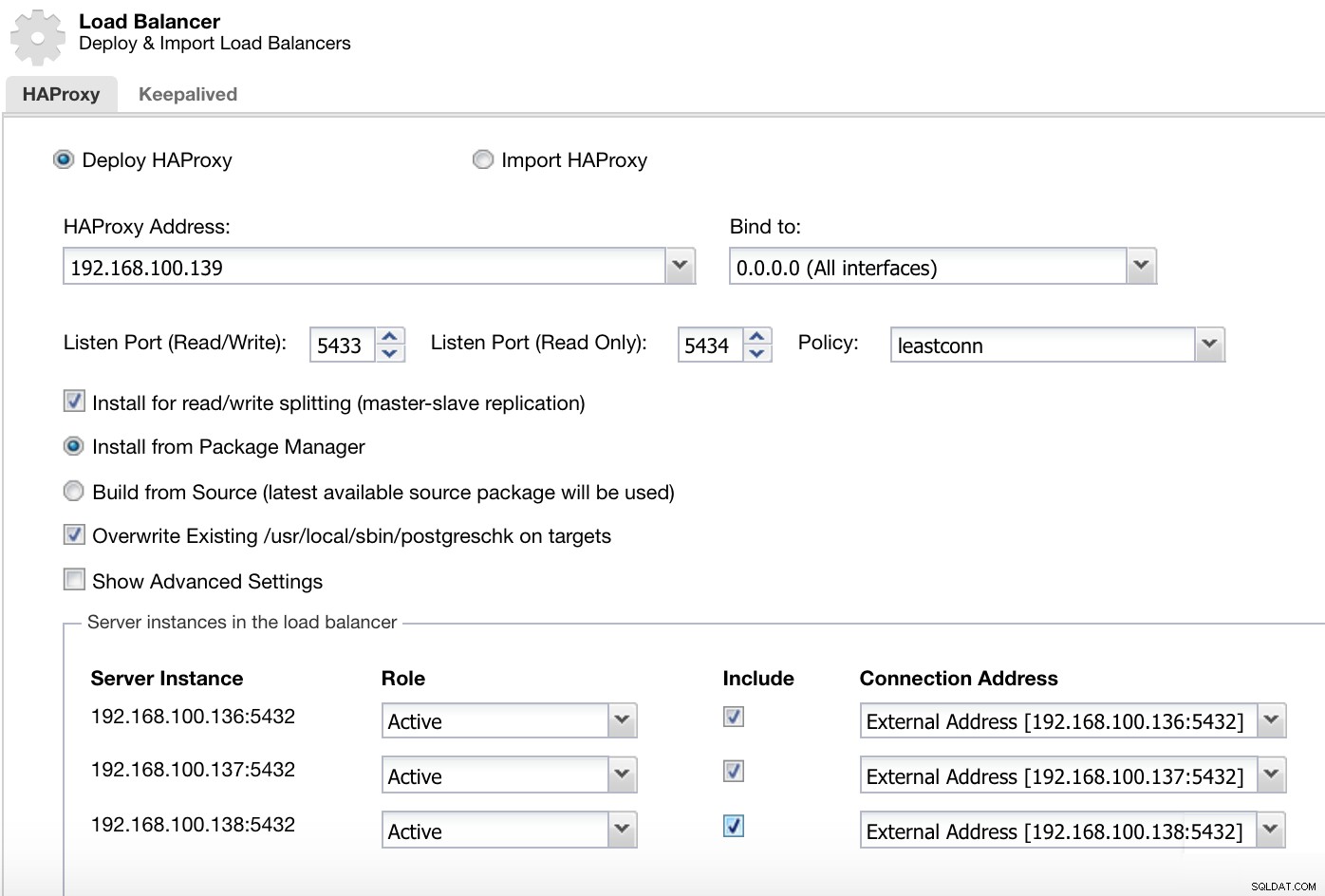 Информация за внедряване на ClusterControl Load Balancer 2
Информация за внедряване на ClusterControl Load Balancer 2 Информацията, която трябва да представим е:
Действие:Разгръщане или импортиране.
HAProxy адрес:IP адрес за нашия HAProxy сървър.
Свързване към:интерфейс или IP адрес, където HAProxy ще слуша.
Порт за слушане (четене/запис):Порт за режим на четене/запис.
Порт за слушане (само за четене):Порт за режим само за четене.
Политика:Може да бъде:
- leastconn:Сървърът с най-малък брой връзки получава връзката.
- roundrobin:Всеки сървър се използва на ред, според теглото му.
- източник:IP адресът на източника се хешира и се разделя на общото тегло на работещите сървъри, за да се определи кой сървър ще получи заявката.
Инсталирайте за разделяне на четене/запис:За репликация главен-подчинен.
Източник:Можем да изберем Инсталиране от мениджър на пакети или изграждане от източник.
Презаписване на съществуващ postgreschk върху цели.
И ние трябва да изберем кои сървъри искате да добавите към конфигурацията на HAProxy и малко допълнителна информация като:
Роля:Може да бъде активен или резервен.
Включете:Да или Не.
Информация за адреса на връзката.
Също така можем да конфигурираме разширени настройки като администратор на потребител, име на бекенда, изчакване и други.
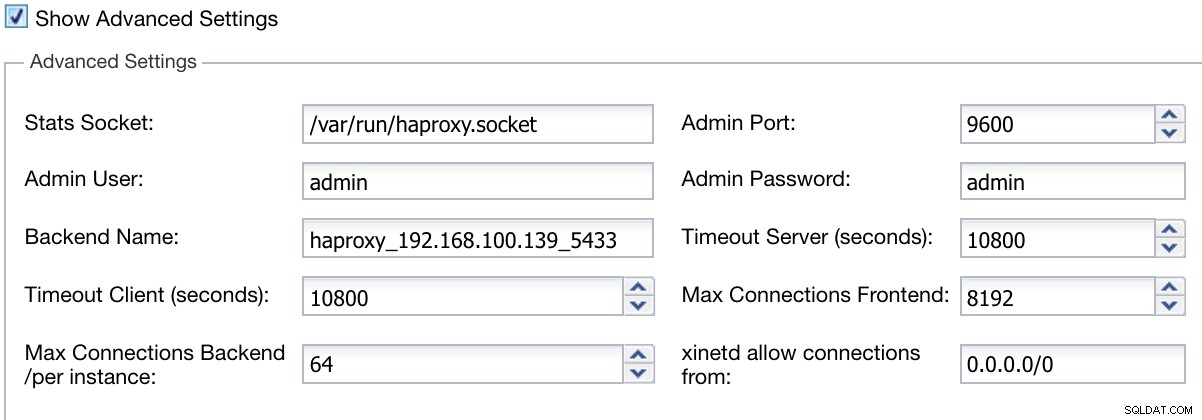 Разширена информация за внедряване на ClusterControl Load Balancer
Разширена информация за внедряване на ClusterControl Load Balancer Когато завършите конфигурацията и потвърдите внедряването, можем да проследим напредъка в секцията за активност на потребителския интерфейс на ClusterControl.
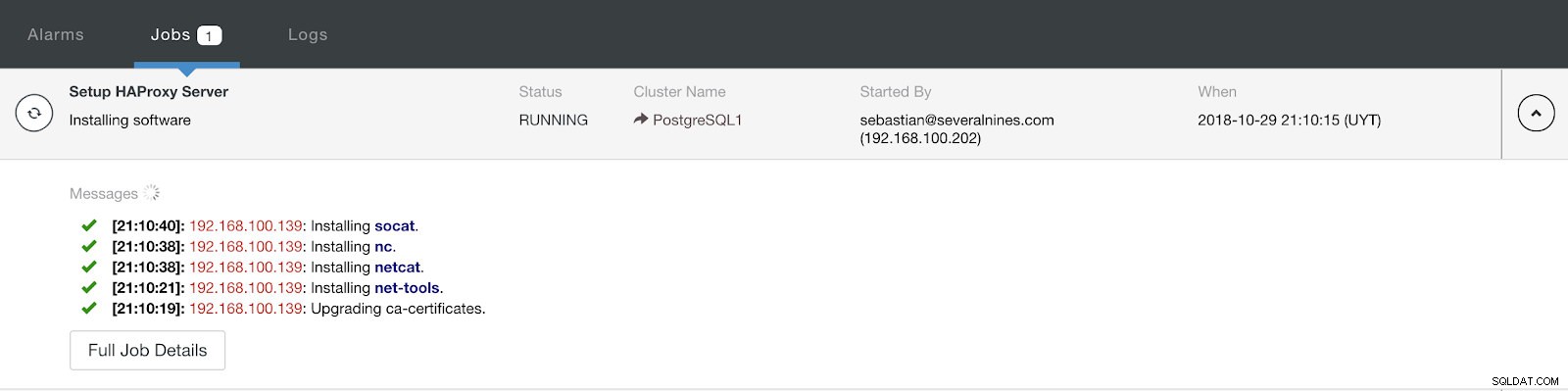 Раздел за активност на ClusterControl
Раздел за активност на ClusterControl Когато приключи, трябва да имаме следната топология:
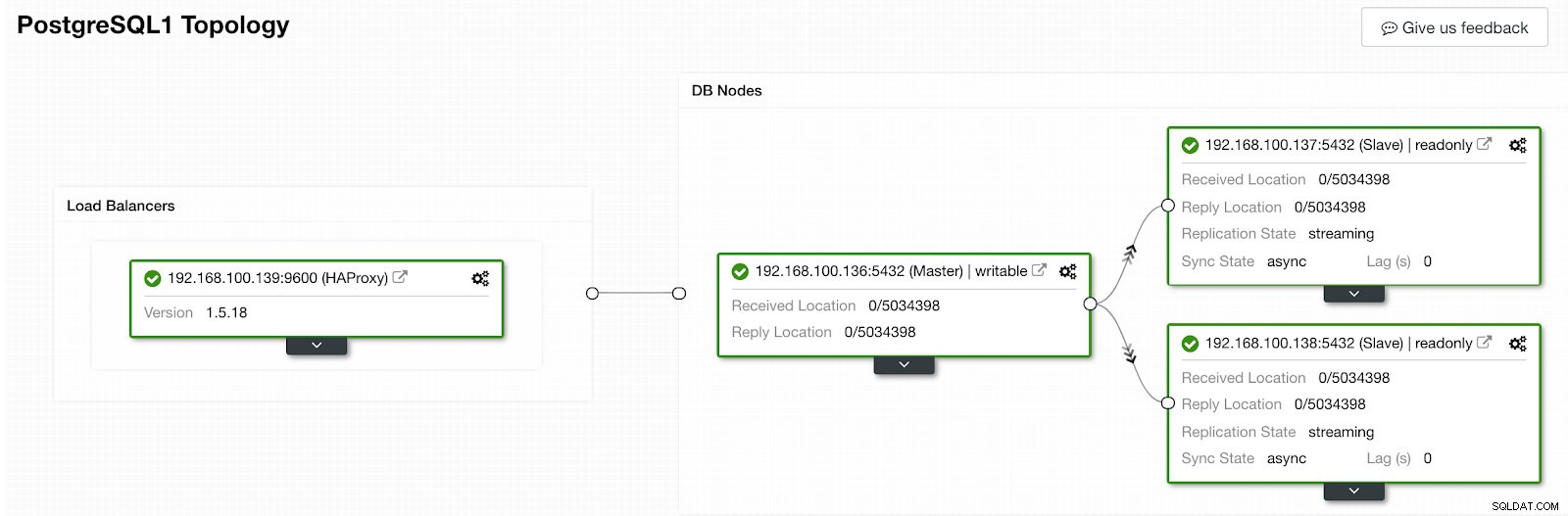 ClusterControl Topology View 2
ClusterControl Topology View 2 Можем да подобрим нашия HA дизайн, като добавим нов HAProxy възел и конфигурираме услугата Keepalived между тях. Всичко това може да се извърши от ClusterControl. За повече информация можете да проверите предишния ни блог за PostgreSQL и HA.
Използване на ClusterControl CLI за добавяне на HAProxy Load Balancer
Известен също като s9s-tools, този допълнителен пакет беше въведен във версия 1.4.1 на ClusterControl, която съдържа двоичен файл, наречен s9s. Това е инструмент на командния ред за взаимодействие, контрол и управление на вашата инфраструктура на базата данни с помощта на ClusterControl. Проектът на командния ред s9s е с отворен код и може да бъде намерен в GitHub.
Започвайки от версия 1.4.1, скриптът за инсталиране автоматично ще инсталира пакета (s9s-tools) на възела ClusterControl.
ClusterControl CLI отваря нова врата за автоматизация на клъстерите, където можете лесно да го интегрирате със съществуващи инструменти за автоматизация на внедряване като Ansible, Puppet, Chef или Salt.
Нека да разгледаме пример за това как да създадете HAProxy балансиране на натоварването с IP адрес 192.168.100.142 на клъстер ID 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.И тогава можем да проверим всички наши възли от командния ред:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5За повече информация относно s9s и как да го използвате, можете да проверите официалната документация или това как да блогвате по тази тема.
Заключение
В този блог разгледахме как HAProxy може да ни помогне да управляваме трафика, идващ от приложението в нашата база данни PostgreSQL. Проверихме как може да бъде разгърнат и конфигуриран ръчно и след това видяхме как може да бъде автоматизиран с ClusterControl. За да избегнете превръщането на HAProxy в единна точка на отказ (SPOF), уверете се, че сте разположили поне два екземпляра на HAProxy и внедрите нещо като Keepalived и Virtual IP върху тях.