CLUSTER
Ако възнамерявате да използвате CLUSTER , показаният синтаксис е невалиден.
create CLUSTER ticket USING ticket_1_idx;
Изпълнете веднъж:
CLUSTER ticket USING ticket_1_idx;
Това може помагат много с по-големи набори от резултати. Не толкова за един върнат ред.
Postgres помни кой индекс да използва за последващи извиквания. Ако таблицата ви не е само за четене, ефектът се влошава с времето и трябва да стартирате отново на определени интервали:
CLUSTER ticket;
Вероятно само на летливи дялове. Вижте по-долу.
Въпреки това , ако имате много актуализации, CLUSTER (или VACUUM FULL ) всъщност може да е лошо за производителността. Правилното количество раздуване позволява UPDATE за поставяне на нови версии на редове на една и съща страница с данни и избягване на необходимостта от физическо разширяване на основния файл в ОС твърде често. Можете да използвате внимателно настроен FILLFACTOR за да получите най-доброто от двата свята:
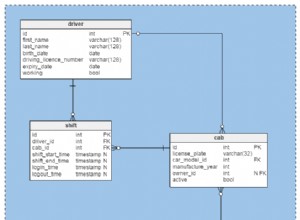
- Коефициент на запълване за последователен индекс, който е PK
pg_repack
CLUSTER взема изключително заключване на масата, което може да е проблем в среда с множество потребители. Цитирайки ръководството:
Когато дадена таблица се клъстерира,
ACCESS EXCLUSIVEзаключване се придобива. Това предотвратява всякакви други операции с база данни (и четене и запис ) от работа с масата доCLUSTERе завършен.
Удебелен акцент мой. Помислете за алтернативния pg_repack :
За разлика от
CLUSTERиVACUUM FULLработи онлайн, без да държи изключително заключване на обработените таблици по време на обработка. pg_repack е ефективен за зареждане, с производителност, сравнима с използването наCLUSTERдиректно.
и:
pg_repack трябва да вземе ексклузивно заключване в края на реорганизацията.
Версия 1.3.1 работи с:
PostgreSQL 8.3, 8.4, 9.0, 9.1, 9.2, 9.3, 9.4
Версия 1.4.2 работи с:
PostgreSQL 9.1, 9.2, 9.3, 9.4, 9.5, 9.6, 10
Запитване
Заявката е достатъчно проста, за да не причинява проблеми с производителността сама по себе си.
Въпреки това, няколко думи за коректността :BETWEEN конструкция включва граници. Заявката ви избира всички от 19 декември, плюс записи от 20 декември, 00:00 часа. Това е изключително малко вероятно изискване. Вероятно е, че наистина искате:
SELECT *
FROM ticket
WHERE created >= '2012-12-19 0:0'
AND created < '2012-12-20 0:0';
Ефективност
Първо, вие питате:
Защо избира последователно сканиране?
Вашето EXPLAIN изходът ясно показва Индексно сканиране , а не последователно сканиране на таблицата. Трябва да има някакво недоразумение.
Ако сте притиснати силно за по-добро представяне, може да успеете да подобрите нещата. Но необходимата основна информация не е под въпрос. Възможните опции включват:
-
Можете да заявите само задължителни колони вместо
*за намаляване на разходите за трансфер (и евентуално други ползи за производителността). -
Можете да разгледате разделяне и поставете практически отрязъци от време в отделни таблици. Добавете индекси към дяловете според нуждите.
-
Ако разделянето не е опция, друга свързана, но по-малко натрапчива техника би била добавянето на един или повече частични индекси .
Например, ако задавате предимно заявки за текущия месец , можете да създадете следния частичен индекс:CREATE INDEX ticket_created_idx ON ticket(created) WHERE created >= '2012-12-01 00:00:00'::timestamp;CREATEнов индекс точно преди началото на нов месец. Можете лесно да автоматизирате задачата с cron задание. По изборDROPчастични индекси за стари месеци по-късно. -
Запазете общия индекс в допълнение за
CLUSTER(което не може да работи с частични индекси). Ако старите записи никога не се променят, разделянето на таблици би помогнало много на тази задача, тъй като трябва само да прегрупирате по-новите дялове. От друга страна, ако записите изобщо не се променят, вероятно нямате нужда отCLUSTER.
Ако комбинирате последните две стъпки, производителността трябва да е страхотна.
Основи на производителността
Може да ви липсва едно от основните положения. Прилагат се всички обичайни съвети за ефективност:
- https://wiki.postgresql.org/wiki/Slow_Query_Questions
- https://wiki.postgresql.org/wiki/Performance_Optimization