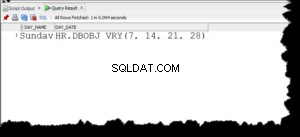
В първата част се оказахме с работещ cmon HA клъстер:
example@sqldat.com:~# s9s controller --list --long
S VERSION OWNER GROUP NAME IP PORT COMMENT
l 1.7.4.3565 system admins 10.0.0.101 10.0.0.101 9501 Acting as leader.
f 1.7.4.3565 system admins 10.0.0.102 10.0.0.102 9501 Accepting heartbeats.
f 1.7.4.3565 system admins 10.0.0.103 10.0.0.103 9501 Accepting heartbeats.
Total: 3 controller(s)Имаме три възела и работят, единият действа като лидер, а останалите са последователи, които са достъпни (те получават удари на сърцето и им отговарят). Оставащото предизвикателство е да конфигурираме достъпа до потребителския интерфейс по начин, който ще ни позволи винаги да имаме достъп до потребителския интерфейс на водещия възел. В тази публикация в блога ще ви представим едно от възможните решения, които ще ви позволят да постигнете точно това.
Настройване на HAProxy
Този проблем не е нов за нас. С всеки клъстер за репликация, MySQL или PostgreSQL, няма значение, има един възел, до който трябва да изпратим своите записи. Един от начините за постигане на това е да използвате HAProxy и да добавите някои външни проверки, които тестват състоянието на възела и въз основа на това да връщат правилните стойности. Това е основно, което ще използваме, за да решим проблема си. Ще използваме HAProxy като добре тестван прокси слой 4 и ще го комбинираме с HTTP проверки на слой 7, които ще напишем точно за нашия случай на употреба. Първо, нека инсталираме HAProxy. Ще го свържем с ClusterControl, но може да бъде инсталиран и на отделен възел (в идеалния случай възли - за премахване на HAProxy като единствена точка на повреда).
apt install haproxyТова настройва HAProxy. След като е готово, трябва да представим нашата конфигурация:
global
pidfile /var/run/haproxy.pid
daemon
user haproxy
group haproxy
stats socket /var/run/haproxy.socket user haproxy group haproxy mode 600 level admin
node haproxy_10.0.0.101
description haproxy server
#* Performance Tuning
maxconn 8192
spread-checks 3
quiet
defaults
#log global
mode tcp
option dontlognull
option tcp-smart-accept
option tcp-smart-connect
#option dontlog-normal
retries 3
option redispatch
maxconn 8192
timeout check 10s
timeout queue 3500ms
timeout connect 3500ms
timeout client 10800s
timeout server 10800s
userlist STATSUSERS
group admin users admin
user admin insecure-password admin
user stats insecure-password admin
listen admin_page
bind *:9600
mode http
stats enable
stats refresh 60s
stats uri /
acl AuthOkay_ReadOnly http_auth(STATSUSERS)
acl AuthOkay_Admin http_auth_group(STATSUSERS) admin
stats http-request auth realm admin_page unless AuthOkay_ReadOnly
#stats admin if AuthOkay_Admin
listen haproxy_10.0.0.101_81
bind *:81
mode tcp
tcp-check connect port 80
timeout client 10800s
timeout server 10800s
balance leastconn
option httpchk
# option allbackups
default-server port 9201 inter 20s downinter 30s rise 2 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:443 check
server 10.0.0.102 10.0.0.102:443 check
server 10.0.0.103 10.0.0.103:443 checkМоже да искате да промените някои от нещата тук, като имената на възела или бекенда, които включват тук IP адреса на нашия възел. Определено ще искате да промените сървърите, които ще включите във вашия HAProxy.
Най-важните битове са:
bind *:81HAProxy ще слуша на порт 81.
option httpchkАктивирахме проверка на слой 7 на бекенд възлите.
default-server port 9201 inter 20s downinter 30s rise 2 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100Проверката на слой 7 ще бъде изпълнена на порт 9201.
След като това стане, стартирайте HAProxy.
Настройване на xinetd и проверка на скрипт
Ще използваме xinetd, за да изпълним проверката и да върнем правилните отговори на HAProxy. Стъпките, описани в този параграф, трябва да се изпълнят на всички cmon HA клъстерни възли.
Първо, инсталирайте xinetd:
example@sqldat.com:~# apt install xinetdСлед като това е направено, трябва да добавим следния ред:
cmonhachk 9201/tcpкъм /etc/services – това ще позволи на xinetd да отвори услуга, която ще слуша на порт 9201. След това трябва да добавим самия файл на услугата. Трябва да се намира в /etc/xinetd.d/cmonhachk:
# default: on
# description: cmonhachk
service cmonhachk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/cmonhachk.py
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Накрая ни трябва скриптът за проверка, който се извиква от xinetd. Както е дефинирано в сервизния файл, той се намира в /usr/local/sbin/cmonhachk.py.
#!/usr/bin/python3.5
import subprocess
import re
import sys
from pathlib import Path
import os
def ret_leader():
leader_str = """HTTP/1.1 200 OK\r\n
Content-Type: text/html\r\n
Content-Length: 48\r\n
\r\n
<html><body>This node is a leader.</body></html>\r\n
\r\n"""
print(leader_str)
def ret_follower():
follower_str = """
HTTP/1.1 503 Service Unavailable\r\n
Content-Type: text/html\r\n
Content-Length: 50\r\n
\r\n
<html><body>This node is a follower.</body></html>\r\n
\r\n"""
print(follower_str)
def ret_unknown():
unknown_str = """
HTTP/1.1 503 Service Unavailable\r\n
Content-Type: text/html\r\n
Content-Length: 59\r\n
\r\n
<html><body>This node is in an unknown state.</body></html>\r\n
\r\n"""
print(unknown_str)
lockfile = "/tmp/cmonhachk_lockfile"
if os.path.exists(lockfile):
print("Lock file {} exists, exiting...".format(lockfile))
sys.exit(1)
Path(lockfile).touch()
try:
with open("/etc/default/cmon", 'r') as f:
lines = f.readlines()
pattern1 = "RPC_BIND_ADDRESSES"
pattern2 = "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}"
m1 = re.compile(pattern1)
m2 = re.compile(pattern2)
for line in lines:
res1 = m1.match(line)
if res1 is not None:
res2 = m2.findall(line)
i = 0
for r in res2:
if r != "127.0.0.1" and i == 0:
i += 1
hostname = r
command = "s9s controller --list --long | grep {}".format(hostname)
output = subprocess.check_output(command.split())
state = output.splitlines()[1].decode('UTF-8')[0]
if state == "l":
ret_leader()
if state == "f":
ret_follower()
else:
ret_unknown()
finally:
os.remove(lockfile)След като създадете файла, уверете се, че е изпълним:
chmod u+x /usr/local/sbin/cmonhachk.pyИдеята зад този скрипт е, че тества състоянието на възлите с помощта на командата “s9s controller --list --long” и след това проверява изхода, свързан с IP, който може да намери на локален възел. Това позволява на скрипта да определи дали хостът, на който се изпълнява, е лидер или не. Ако възелът е водещ, скриптът връща код „HTTP/1.1 200 OK“, който HAProxy интерпретира като възелът е наличен и насочва трафика към него. В противен случай връща „HTTP/1.1 503 Service Unavailable“, което се третира като възел, който не е здрав и трафикът няма да се насочва там. В резултат на това, без значение кой възел ще стане водещ, HAProxy ще го открие и ще го маркира като наличен в бекенда:

Може да се наложи да рестартирате HAProxy и xinetd, за да приложите промените в конфигурацията преди всички частите ще започнат да работят правилно.
Наличието на повече от един HAProxy гарантира, че имаме начин за достъп до потребителския интерфейс на ClusterControl, дори ако един от възлите на HAProxy няма да успее, но все още имаме две (или повече) различни имена на хостове или IP за свързване с потребителския интерфейс на ClusterControl. За да го направим по-удобно, ще разположим Keepalived върху HAProxy. Той ще следи състоянието на услугите HAProxy и ще присвоява виртуален IP на една от тях. Ако този HAProxy стане недостъпен, VIP ще бъде преместен в друго налично HAProxy. В резултат на това ще имаме една точка на влизане (VIP или име на хост, свързано с нея). Стъпките, които ще предприемем тук, трябва да бъдат изпълнени на всички възли, където е инсталиран HAProxy.
Първо, нека инсталираме keepalived:
apt install keepalivedСлед това трябва да го конфигурираме. Ще използваме следния конфигурационен файл:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 102
unicast_src_ip 10.0.0.101
unicast_peer {
10.0.0.102
10.0.0.103
}
virtual_ipaddress {
10.0.0.130 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.sh
}Трябва да промените този файл на различни възли. IP адресите трябва да бъдат конфигурирани правилно и приоритетът трябва да е различен на всички възли. Моля, също така конфигурирайте VIP, който има смисъл във вашата мрежа. Може също да искате да промените интерфейса – използвахме eth1, където IP се присвоява на виртуални машини, създадени от Vagrant.
Стартирайте keepalived с този конфигурационен файл и трябва да сте готови. Докато VIP е настроен на един HAProxy възел, трябва да можете да го използвате, за да се свържете с правилния потребителски интерфейс на ClusterControl:

Това завършва нашето въведение от две части във високодостъпните клъстери на ClusterControl. Както казахме в началото, това все още е в бета състояние, но с нетърпение очакваме обратна връзка от вашите тестове.