В случай, че не сте го виждали, току-що пуснахме ClusterControl 1.7.5 със значителни подобрения и нови полезни функции. Някои от функциите включват Cluster Wide Maintenance, поддръжка за версия CentOS 8 и Debian 10, поддръжка на PostgreSQL 12, поддръжка на MongoDB 4.2 и Percona MongoDB v4.0, както и новата MySQL Freeze Frame.
Чакайте, но какво е MySQL Freeze Frame? Това нещо ново ли е за MySQL?
Е, това не е нещо ново в самото ядро на MySQL. Това е нова функция, която добавихме към ClusterControl 1.7.5, която е специфична за MySQL бази данни. MySQL Freeze Frame в ClusterControl 1.7.5 ще покрива следните неща:
- Статус на MySQL моментна снимка преди отказ на клъстера.
- Списък на процесите на MySQL на моментна снимка преди отказ на клъстера (очаквайте скоро).
- Проверете клъстерни инциденти в оперативни отчети или от инструмента на командния ред s9s.
Това са ценни набори от информация, които могат да помогнат за проследяване на грешки и коригиране на вашите MySQL/MariaDB клъстери, когато нещата тръгнат на юг. В бъдеще планираме да включим и моментни снимки на стойностите на състоянието на SHOW ENGINE InnoDB. Така че, моля, следете нашите бъдещи издания.
Обърнете внимание, че тази функция все още е в бета състояние, очакваме да събираме повече набори от данни, докато работим с нашите потребители. В този блог ще ви покажем как да използвате тази функция, особено когато имате нужда от допълнителна информация, когато диагностицирате вашия MySQL/MariaDB клъстер.
ClusterControl при обработка на неуспех на клъстер
При откази на клъстер ClusterControl не прави нищо, освен ако автоматичното възстановяване (клъстер/възел) не е активирано, както по-долу:

След като е активиран, ClusterControl ще се опита да възстанови възел или да възстанови клъстера чрез извеждане на цялата топология на клъстера.
За MySQL, например в репликация главен-подчинен, той трябва да има поне един жив главен във всеки даден момент, независимо от броя на наличните подчинени устройства. ClusterControl се опитва да коригира топологията поне веднъж за клъстери за репликация, но предоставя повече повторни опити за мулти-главна репликация като NDB Cluster и Galera Cluster. Възстановяването на възел се опитва да възстанови неуспешен възел на базата данни, напр. когато процесът е бил убит (ненормално изключване) или процесът е претърпял OOM (извън памет). ClusterControl ще се свърже с възела чрез SSH и ще се опита да изведе MySQL. По-рано писахме в блог за това как ClusterControl извършва автоматично възстановяване на базата данни и отказ, така че, моля, посетете тази статия, за да научите повече за схемата за автоматично възстановяване на ClusterControl.
В предишната версия на ClusterControl <1.7.5 тези опити за възстановяване задействаха аларми. Но едно нещо, което нашите клиенти пропуснаха, беше по-пълен доклад за инцидент с информация за състоянието точно преди повредата на клъстера. Докато не осъзнахме този недостатък и добавихме тази функция в ClusterControl 1.7.5. Нарекохме го "MySQL Freeze Frame". Към момента на писането на MySQL Freeze Frame предлага кратко обобщение на инциденти, водещи до промени в състоянието на клъстера точно преди срива. Най-важното е, че включва в края на отчета списъка с хостове и техните променливи и стойности на MySQL Global Status.
Как MySQL Freeze Frame се различава с автоматичното възстановяване?
MySQL Freeze Frame не е част от автоматичното възстановяване на ClusterControl. Независимо дали автоматичното възстановяване е деактивирано или активирано, MySQL Freeze Frame винаги ще върши своята работа, стига да бъде открит отказ на клъстер или възел.
Как работи MySQL Freeze Frame?
В ClusterControl има определени състояния, които класифицираме като различни типове състояние на клъстера. MySQL Freeze Frame ще генерира доклад за инцидент, когато се задействат тези две състояния:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
В ClusterControl CLUSTER_DEGRADED е, когато можете да пишете в клъстер, но един или повече възли не работят. Когато това се случи, ClusterControl ще генерира доклада за инцидента.
За CLUSTER_FAILURE, въпреки че номенклатурата му се обяснява, това е състоянието, в което вашият клъстер се проваля и вече не е в състояние да обработва четения или записвания. Тогава това е състояние CLUSTER_FAILURE. Независимо дали процесът на автоматично възстановяване се опитва да отстрани проблема или е деактивиран, ClusterControl ще генерира доклада за инцидента.
Как да активирате MySQL Freeze Frame?
MySQL Freeze Frame на ClusterControl е активиран по подразбиране и генерира доклад за инцидент само когато състоянията CLUSTER_DEGRADED или CLUSTER_FAILURE се задействат или срещат. Така че няма нужда от страна на потребителя да задава конфигурация на ClusterControl, ClusterControl ще го направи автоматично за вас.
Намиране на доклада за инцидента на MySQL Freeze Frame
От момента на писане има 4 начина, по които можете да намерите доклада за инцидента. Те могат да бъдат намерени, като направите следните раздели по-долу.
Използване на раздела Оперативни отчети
Оперативните отчети от предишните версии се използват само за създаване, планиране или изброяване на оперативните отчети, генерирани от потребителите. От версия 1.7.5 включихме доклада за инцидента, генериран от нашата функция за замразяване на MySQL. Вижте примера по-долу:
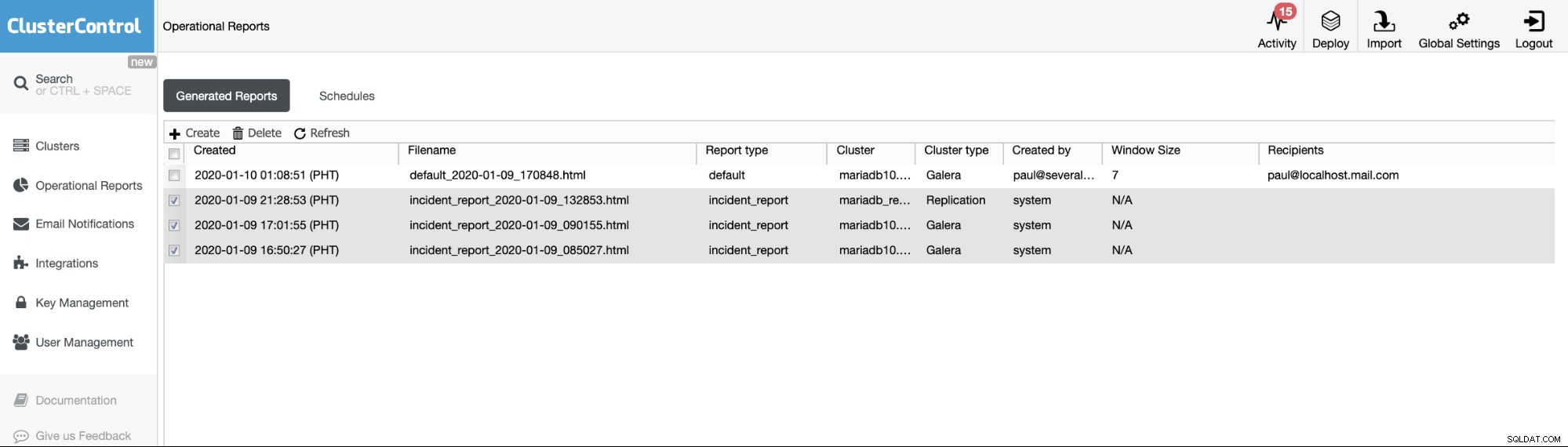
Отметените елементи или артикули с тип отчет ==incident_report са инцидентът отчети, генерирани от функцията MySQL Freeze Frame в ClusterControl.
Използване на отчети за грешки
Като изберете клъстера и генерирате отчет за грешка, т.е. преминавате през този процес:<изберете клъстера> → Регистри → Отчети за грешки → Създайте доклад за грешка. Това ще включва доклада за инцидента под хоста на ClusterControl.
Използване на s9s CLI команден ред
В генериран доклад за инцидент той включва инструкции или намек за това как можете да използвате това с командата s9s CLI. По-долу е показано какво е показано в доклада за инцидента:
Съвет! Използването на инструмента s9s CLI ви позволява лесно да преглеждате данни в този отчет, напр.:
s9s report --list --long
s9s report --cat --report-id=NТака че, ако искате да намерите и генерирате отчет за грешка, можете да използвате този подход:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportАко искам да извлека променливите wsrep_* на конкретен хост, мога да направя следното:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Ръчно намиране чрез път на системния файл
ClusterControl генерира тези отчети за инциденти в хоста, където се изпълнява ClusterControl. ClusterControl създава директория в /home/
Има ли опасности или предупреждения при използване на MySQL Freeze Frame?
ClusterControl не променя и не променя нищо във вашите MySQL възли или клъстер. MySQL Freeze Frame просто ще чете SHOW GLOBAL STATUS (от този момент) на определени интервали, за да запази записи, тъй като не можем да предвидим състоянието на MySQL възел или клъстер, когато може да се срине или когато може да има проблеми с хардуера или диска. Не е възможно да се предвиди това, така че запазваме стойностите и следователно можем да генерираме доклад за инцидент в случай, че конкретен възел се повреди. В такъв случай опасността от това е почти никаква. Теоретично може да добави серия от клиентски заявки към сървъра(ите) в случай, че някои заключвания се държат в MySQL, но ние все още не сме го забелязали. Серията от тестове не показва това, така че ще се радваме, ако можете да позволите знаем или подайте заявка за поддръжка в случай, че възникнат проблеми.
Има определени ситуации, при които докладът за инцидент може да не може да събере глобални променливи на състоянието, ако проблемът с мрежата е бил проблемът преди ClusterControl да замрази конкретна рамка за събиране на данни. Това е напълно разумно, защото няма начин ClusterControl да събира данни за по-нататъшна диагностика, тъй като на първо място няма връзка с възела.
Накрая, може да се чудите защо не всички променливи са показани в секцията ГЛОБАЛЕН СТАТУС? Междувременно зададохме филтър, при който празните или 0 стойности са изключени в доклада за инцидента. Причината е, че искаме да спестим малко дисково пространство. След като тези доклади за инциденти вече не са необходими, можете да ги изтриете чрез раздела Оперативни отчети.
Тестване на функцията MySQL Freeze Frame
Вярваме, че имате нетърпение да опитате това и да видите как работи. Но моля, уверете се, че не изпълнявате или тествате това в жива или производствена среда. Ще покрием 2 фази на сценарий в MySQL/MariaDB, една за настройка главен-подчинен и една за настройка от тип Galera.
Сценарий за тестване за настройка главен-подчинен
При настройка главен-подчинен(и) е лесно и лесно да се опита.
Първа стъпка
Уверете се, че сте деактивирали режимите за автоматично възстановяване (клъстер и възел), както по-долу:

така че няма да се опитва или да се опитва да коригира тестовия сценарий.
Стъпка втора
Отидете до своя главен възел и опитайте да зададете само за четене:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Трета стъпка
Този път се вдигна аларма и така се генерира доклад за инцидент. Вижте по-долу как изглежда моят клъстер:

и алармата се задейства:

и отчетът за инцидента беше генериран:

Тестов сценарий за настройка на клъстер на Galera
За настройка, базирана на Galera, трябва да се уверим, че клъстерът вече няма да е наличен, т.е. повреда в целия клъстер. За разлика от теста Master-Slave, можете да оставите автоматичното възстановяване активирано, тъй като ще си играем с мрежовите интерфейси.
Забележка:За тази настройка се уверете, че имате няколко интерфейса, ако тествате възлите в отдалечен екземпляр, тъй като не можете да изведете интерфейса нагоре, когато надолу по този интерфейс, където сте свързани.
Първа стъпка
Създайте клъстер Galera с 3 възела (например с помощта на vagrant)
Стъпка втора
Издайте командата (точно както по-долу), за да симулирате мрежов проблем и направете това с всички възли
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Трета стъпка
Сега свали клъстера ми и има това състояние:

вдигна аларма,

и генерира доклад за инцидент:

За примерен доклад за инцидент, можете да използвате този необработен файл и да го запишете като html.
Доста е лесно да опитате, но отново, моля, направете това само в среда, която не е на живо и не е продуцирана.
Заключение
MySQL Freeze Frame в ClusterControl може да бъде полезен при диагностициране на сривове. Когато отстранявате неизправности, имате нужда от богата информация, за да определите причината и точно това предоставя MySQL Freeze Frame.