В предишен блог обявихме нова функция на ClusterControl 1.7.4, наречена репликация от клъстер към клъстер. Той автоматизира целия процес на настройка на DR клъстер извън вашия първичен клъстер, с репликация между тях. За по-подробна информация, моля, вижте гореспоменатия запис в блога.
Сега в този блог ще разгледаме как да конфигурираме тази нова функция за съществуващ клъстер. За тази задача ще приемем, че имате инсталиран ClusterControl и главният клъстер е разгърнат с него.
Изисквания за главния клъстер
Има някои изисквания към главния клъстер, за да работи:
- Percona XtraDB Cluster версия 5.6.x и по-нова или MariaDB Galera Cluster версия 10.x и по-нова.
- GTID е активиран.
- Бинарното регистриране е активирано на поне един възел на базата данни.
- Резервните идентификационни данни трябва да са еднакви в главния и подчинения клъстер.
Подготовка на главния клъстер
Главният клъстер трябва да бъде подготвен да използва тази нова функция. Изисква конфигурация както от страна на ClusterControl, така и от страна на базата данни.
Конфигурация на ClusterControl
В възела на базата данни проверете резервните потребителски идентификационни данни, съхранени в /etc/my.cnf.d/secrets-backup.cnf (за базирана на RedHat OS) или в /etc/mysql/secrets-backup .cnf (за базирана на Debian OS).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElВ възела ClusterControl редактирайте конфигурационния файл /etc/cmon.d/cmon_ID.cnf (където ID е идентификационният номер на клъстера) и се уверете, че съдържа същите идентификационни данни, съхранявани в secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Всяка промяна в този файл изисква рестартиране на услугата cmon:
$ service cmon restartПроверете параметрите за репликация на базата данни, за да се уверите, че сте активирали GTID и Binary Logging.
Конфигурация на базата данни
В възела на базата данни проверете файла /etc/my.cnf (за базирана на RedHat OS) или /etc/mysql/my.cnf (за базирана на Debian OS), за да видите конфигурацията, свързана с процес на репликация.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Клъстер MariaDB Galera:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7След като проверите конфигурационните файлове, можете да проверите дали е активиран в потребителския интерфейс на ClusterControl. Отидете на ClusterControl -> Изберете Cluster -> Nodes. Там трябва да имате нещо подобно:

Ролята „Master“, добавена в първия възел, означава, че Binary Logging е активирана.
Активиране на бинарно регистриране
Ако не сте активирали двоичното регистриране, отидете на ClusterControl -> Изберете Cluster -> Nodes -> Node Actions -> Enable Binary Logging.
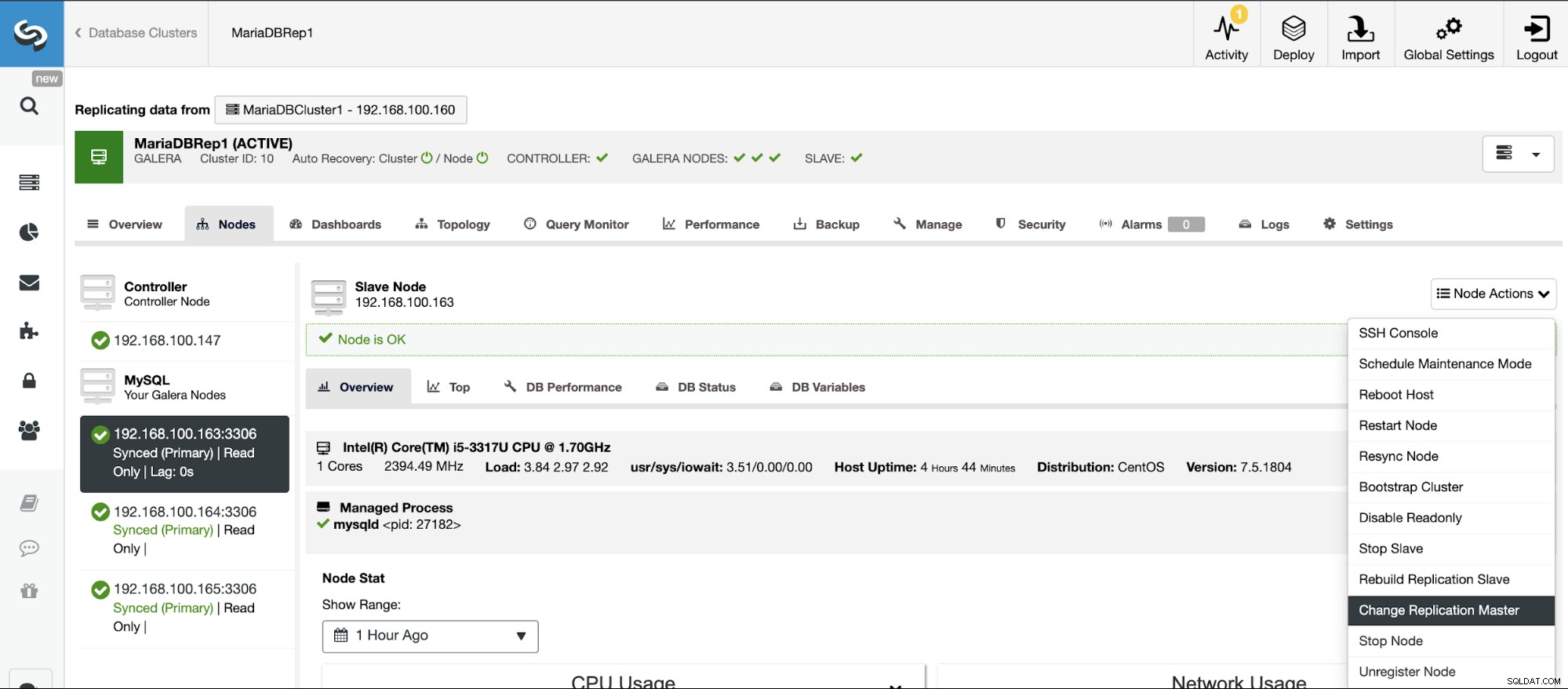
След това трябва да посочите запазването на двоичния дневник и пътя за съхранение то. Трябва също да посочите дали искате ClusterControl да рестартира възела на базата данни след конфигурирането му, или предпочитате да го рестартирате сами.
Имайте предвид, че активирането на бинарно регистриране винаги изисква рестартиране на услугата за база данни .
Създаване на подчинен клъстер от графичния интерфейс на ClusterControl
За да създадете нов подчинен клъстер, отидете на ClusterControl -> Изберете Cluster -> Cluster Actions -> Създайте подчинен клъстер.
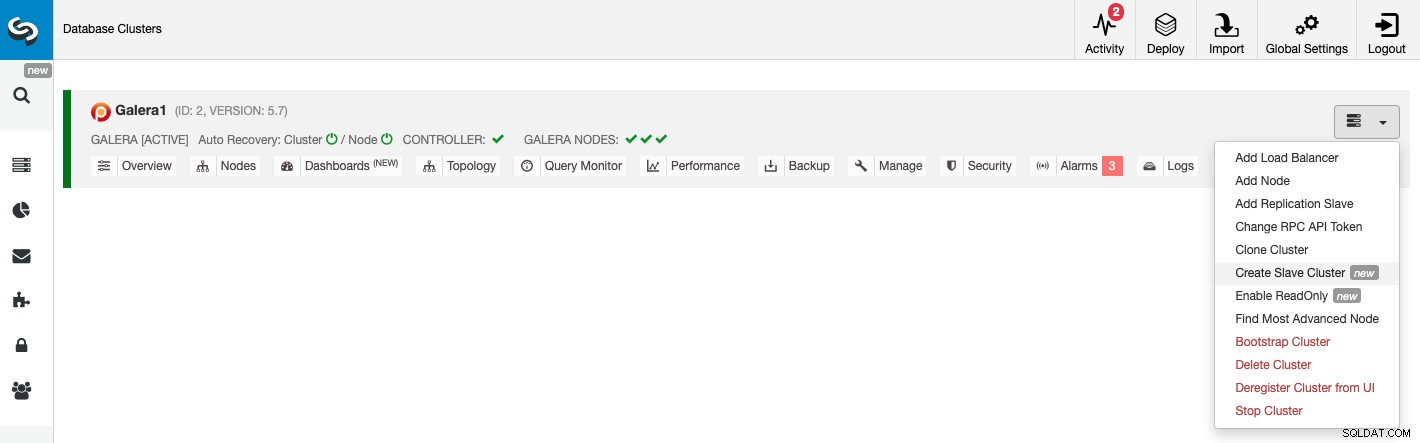
Подчинения клъстер може да бъде създаден чрез поточно предаване на данни от текущия главен клъстер или чрез използване на съществуващ архив.
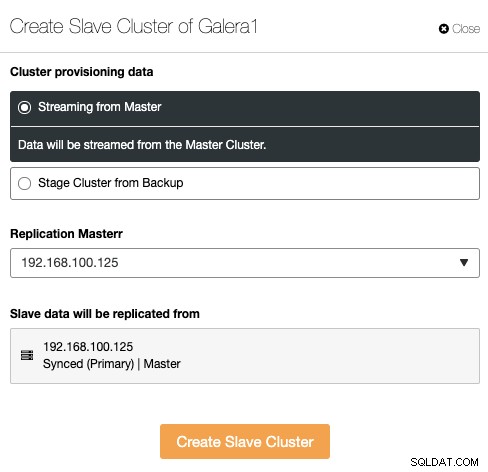
В този раздел трябва също да изберете главния възел на текущия клъстер от който данните ще бъдат репликирани.
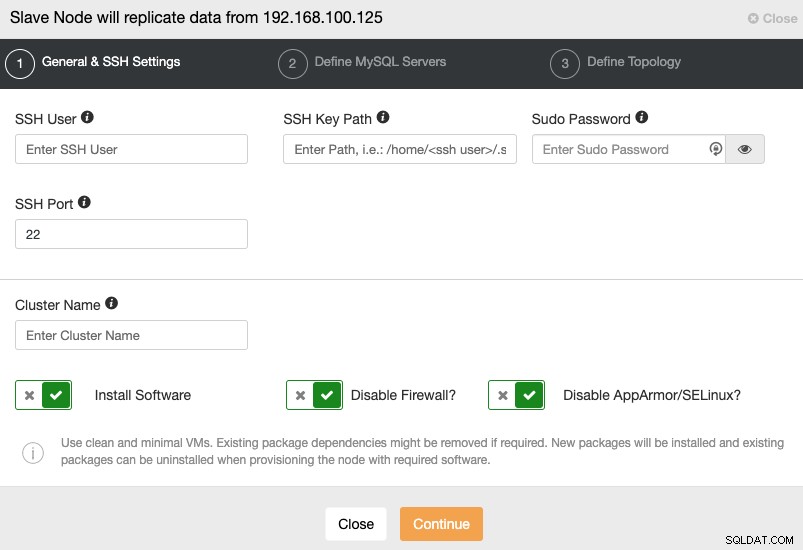
Когато преминете към следващата стъпка, трябва да посочите потребител, ключ или Парола и порт за свързване чрез SSH към вашите сървъри. Освен това имате нужда от име за вашия подчинен клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
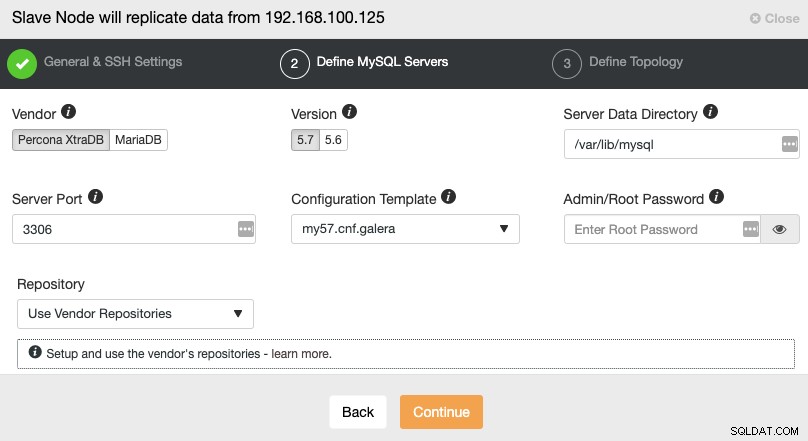
След като настроите информацията за SSH достъп, трябва да дефинирате доставчика на базата данни и версия, datadir, порт на базата данни и администраторска парола. Уверете се, че използвате същия доставчик/версия и идентификационни данни, както се използват от главния клъстер. Можете също да посочите кое хранилище да използвате.
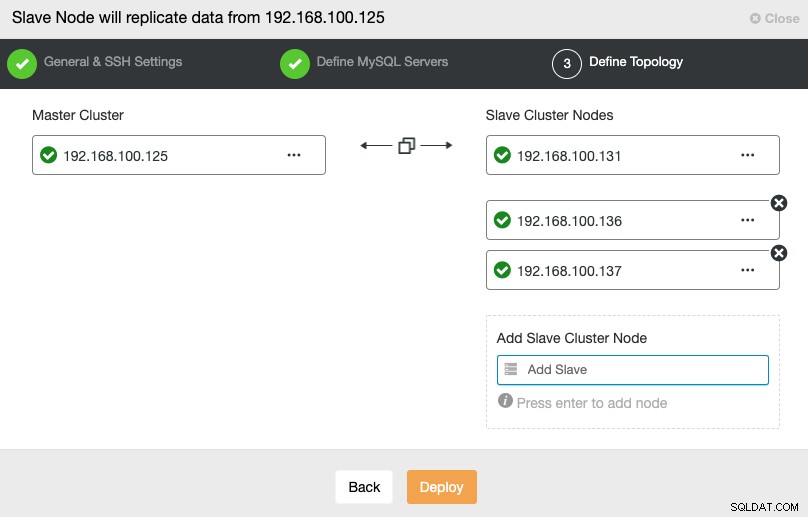
В тази стъпка трябва да добавите сървъри към новия подчинен клъстер. За тази задача можете да въведете както IP адрес, така и име на хост на всеки възел на базата данни.
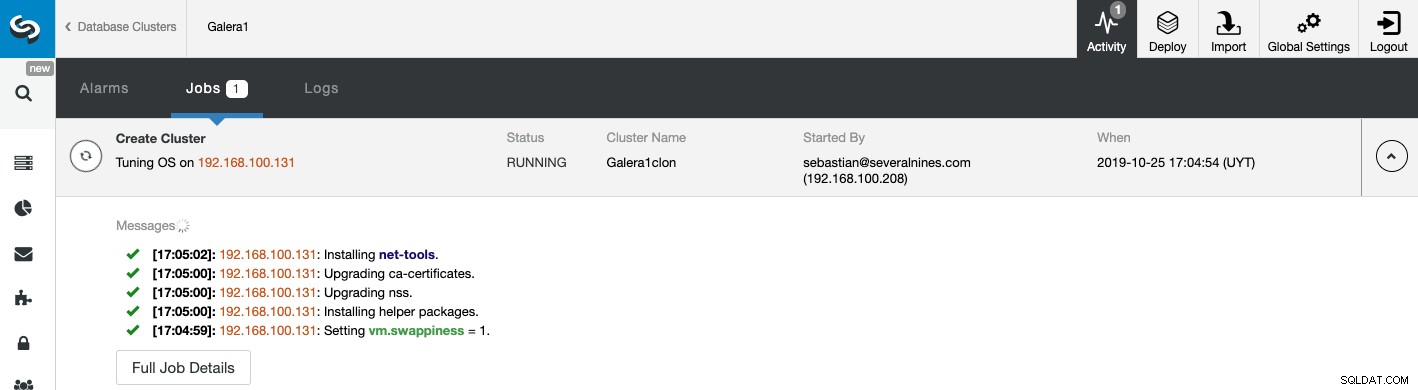
Можете да наблюдавате състоянието на създаването на вашия нов подчинен клъстер от Монитор на активността на ClusterControl. След като задачата приключи, можете да видите клъстера в главния екран на ClusterControl.
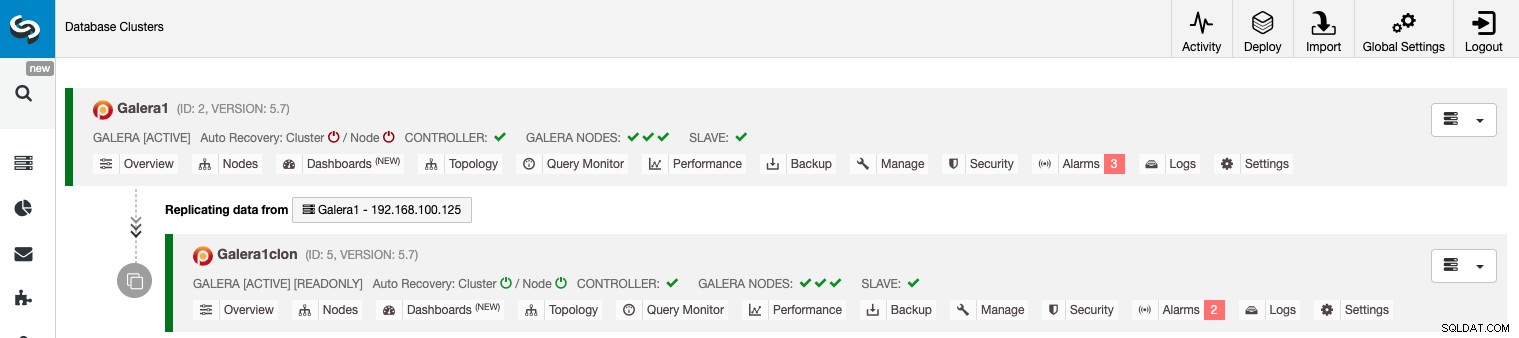
Управление на репликация от клъстер към клъстер с помощта на графичния интерфейс на ClusterControl
Сега вашата репликация от клъстер към клъстер е стартирана и работи, има различни действия за извършване на тази топология с помощта на ClusterControl.
Конфигуриране на активни-активни клъстери
Както можете да видите, по подразбиране подчинения клъстер е настроен в режим само за четене. Възможно е да деактивирате флага само за четене на възлите един по един от потребителския интерфейс на ClusterControl, но имайте предвид, че клъстерирането Active-Active се препоръчва само ако приложенията докосват само несвързани набори от данни в който и да е клъстер, тъй като MySQL/MariaDB не го прави предлага всякакво откриване или разрешаване на конфликти.
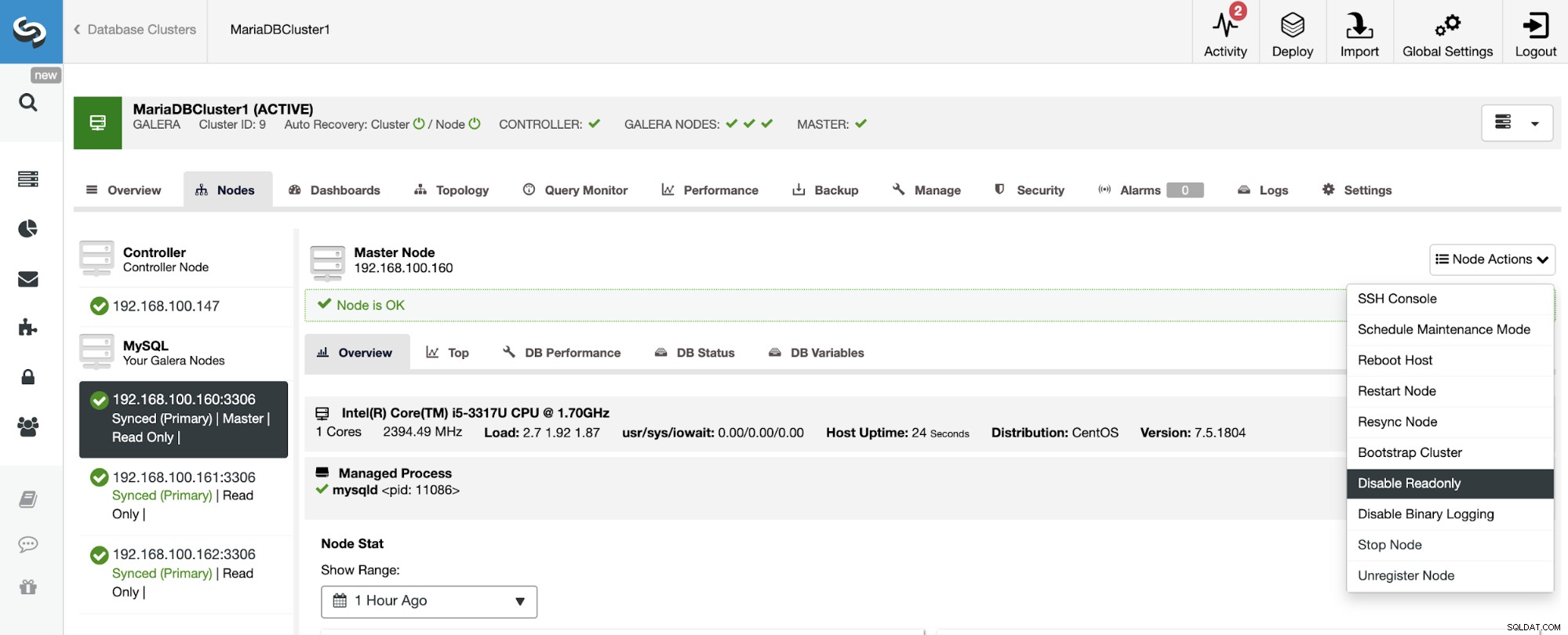
За да деактивирате режима само за четене, отидете на ClusterControl -> Изберете Slave Клъстер -> Възли. В този раздел изберете всеки възел и използвайте опцията Деактивиране само за четене.
Възстановяване на подчинен клъстер
За да избегнете несъответствия, ако искате да изградите отново подчинен клъстер, това трябва да е клъстер само за четене, това означава, че всички възли трябва да са в режим само за четене.
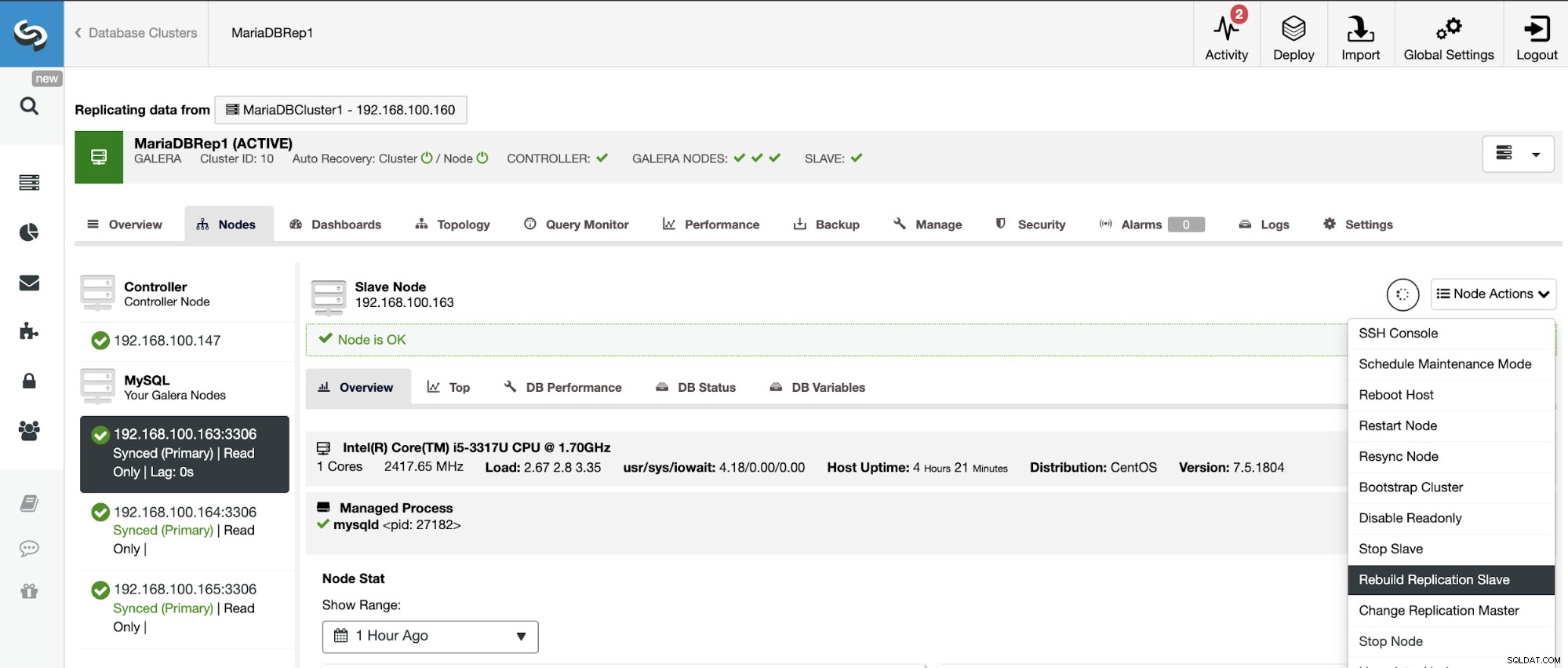
Отидете на ClusterControl -> Изберете Slave Cluster -> Nodes -> Изберете Възел, свързан към главния клъстер -> Действия на възел -> Повторно изграждане на подчинен репликация.
Промени в топологията
Ако имате следната топология:
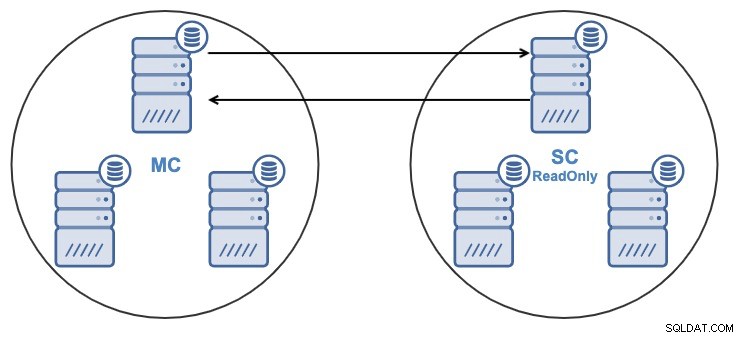
И по някаква причина искате да промените възела за репликация в главния Клъстер. Възможно е да промените главния възел, използван от подчинения клъстер, на друг главен възел в главния клъстер.
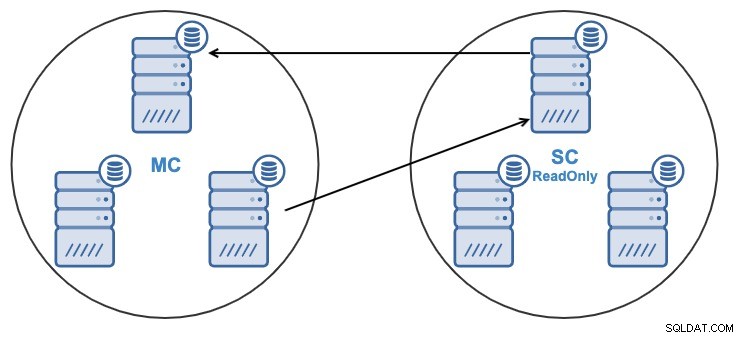
За да се счита за главен възел, трябва да има активиран двоичен журнал .
Отидете на ClusterControl -> Изберете Slave Cluster -> Nodes -> Изберете Възел, свързан към главния клъстер -> Действия на възел -> Спиране на подчинен/стартиране на подчинен.
Спиране/Стартиране на подчинено устройство за репликация
Можете да спрете и стартирате подчинени устройства за репликация по лесен начин с помощта на ClusterControl.
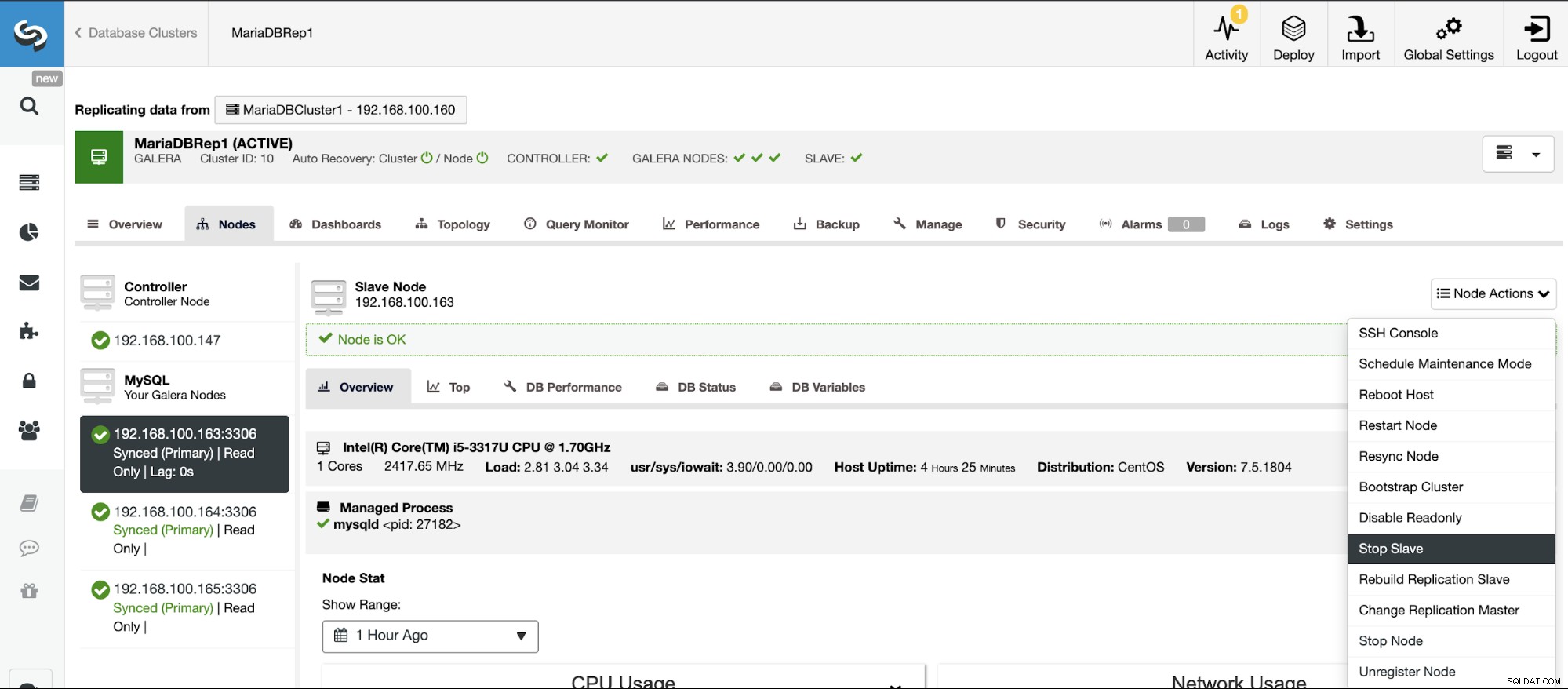
Отидете на ClusterControl -> Изберете Slave Cluster -> Nodes -> Изберете Възел, свързан към главния клъстер -> Действия на възел -> Спиране на подчинен/стартиране на подчинен.
Нулиране на подчинено устройство за репликация
Използвайки това действие, можете да нулирате процеса на репликация, като използвате НУЛИРАНЕ НА ПЛАВЕНО или НУЛИРАНЕ НА ВСИЧКО ДЛЪЖНО. Разликата между тях е, че RESET SLAVE не променя нито един параметър за репликация като главен хост, порт и идентификационни данни. За да изтриете тази информация, трябва да използвате RESET SLAVE ALL, което премахва цялата конфигурация на репликация, така че с помощта на тази команда връзката за репликация от клъстер към клъстер ще бъде унищожена.
Преди да използвате тази функция, трябва да спрете процеса на репликация (моля, вижте предишната функция).
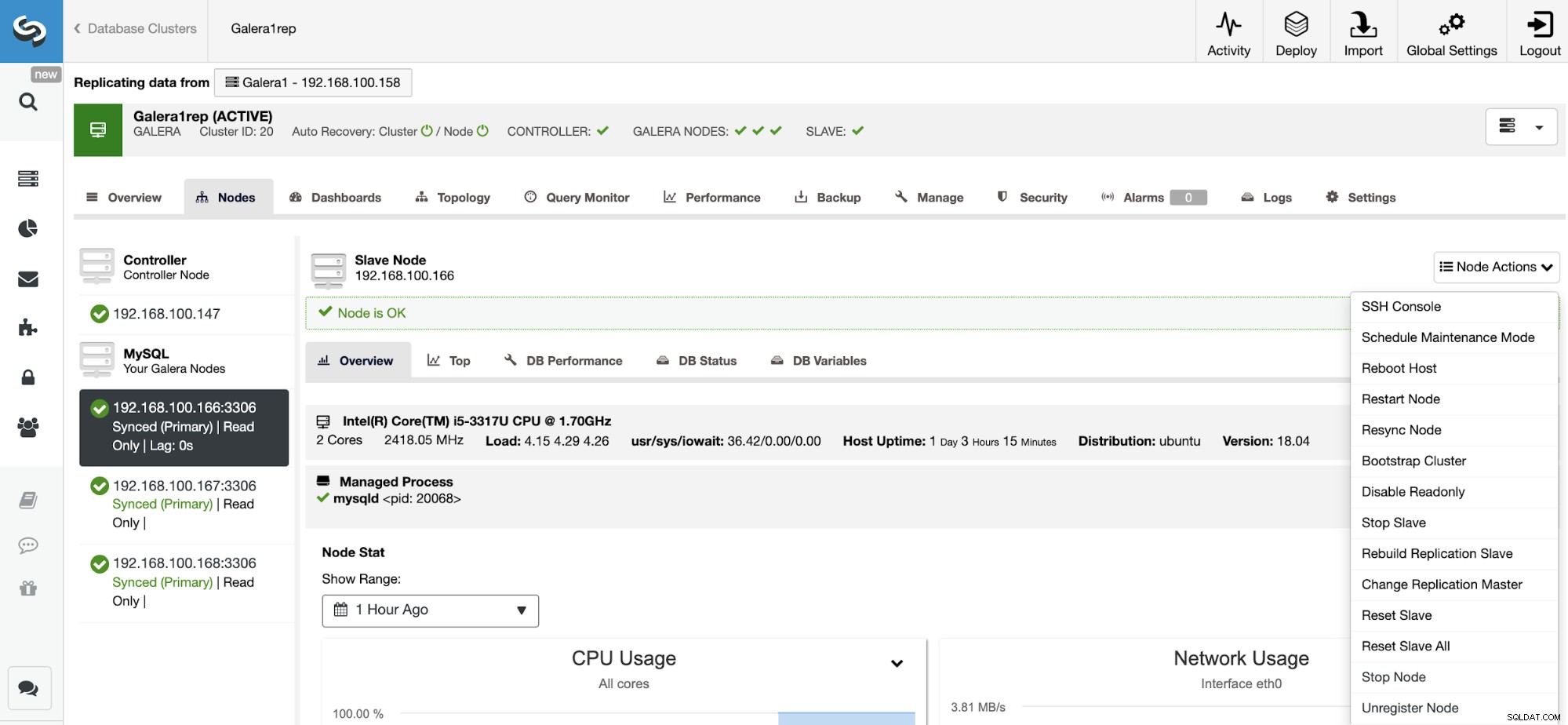
Отидете на ClusterControl -> Изберете Slave Cluster -> Nodes -> Изберете Възел, свързан към главния клъстер -> Действия на възел -> Нулиране на подчинен/Нулиране на подчинено устройство на всички.
Управление на репликация от клъстер към клъстер с помощта на ClusterControl CLI
В предишния раздел успяхте да видите как да управлявате репликация от клъстер към клъстер с помощта на потребителския интерфейс на ClusterControl. Сега нека да видим как да го направите с помощта на командния ред.
Забележка:Както споменахме в началото на този блог, ще приемем, че имате инсталиран ClusterControl и главният клъстер е разгърнат с него.
Създайте подчинен клъстер
Първо, нека видим примерна команда за създаване на подчинен клъстер с помощта на ClusterControl CLI:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logСега стартирате вашия процес за създаване на подчинен, нека видим всеки използван параметър:
- Клъстер:За изброяване и манипулиране на клъстери.
- Създаване:Създайте и инсталирайте нов клъстер.
- Име на клъстер:Името на новия подчинен клъстер.
- Тип клъстер:Типът клъстер за инсталиране.
- Версия на доставчика:Версията на софтуера.
- Възли:Списък на новите възли в подчинения клъстер.
- Os-user:Потребителското име за SSH командите.
- Os-key-file:Ключовият файл, който да се използва за SSH връзка.
- Db-admin:Потребителското име на администратора на базата данни.
- Db-admin-passwd:Паролата за администратора на базата данни.
- Remote-cluster-id:Главен идентификатор на клъстер за репликацията от клъстер към клъстер.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Използвайки флага --log, ще можете да виждате регистрационните файлове в реално време:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Конфигуриране на активни-активни клъстери
Както видяхте по-рано, можете да деактивирате режима само за четене в новия клъстер, като го деактивирате във всеки възел, така че нека да видим как да го направите от командния ред.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logНека видим всеки параметър:
- Възел:За обработка на възли.
- Задаване-четене-запис:Задайте възела на режим четене-запис.
- Възли:Възелът, където да го промените.
- Cluster-id:Идентификаторът на клъстера, в който е възелът.
След това ще видите:
192.168.100.166:3306: Setting read_only=OFF.Възстановяване на подчинен клъстер
Можете да изградите отново подчинен клъстер, като използвате следната команда:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logПараметрите са:
- Репликация:За наблюдение и контрол на репликацията на данни.
- Етап:Етап/преизграждане на подчинен репликация.
- Мастер:Главният главен адрес на репликация в главния клъстер.
- Slave:Подчинения за репликация в подчинения клъстер.
- Cluster-id:Идентификаторът на подчинения клъстер.
- Remote-cluster-id:Идентификаторът на главния клъстер.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Регистърът на заданията трябва да е подобен на този:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Промени в топологията
Можете да промените топологията си, като използвате друг възел в главния клъстер, от който репликирате данните, така че например можете да изпълните:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logНека проверим използваните параметри.
- Репликация:За наблюдение и контрол на репликацията на данни.
- Отказ при отказ:Поемете ролята на главен от неуспешен/стар майстор.
- Master:Новият главен код за репликация в главния клъстер.
- Slave:Подчинения за репликация в Slave Cluster.
- Cluster-id:ИД на подчинения клъстер.
- Remote-Cluster-id:Идентификаторът на главния клъстер.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Ще видите този дневник:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Спиране/Стартиране на подчинено устройство за репликация
Можете да спрете да репликирате данните от главния клъстер по този начин:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logЩе видите това:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.И сега можете да го стартирате отново:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logИ така, ще видите:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Сега нека проверим използваните параметри.
- Репликация:За наблюдение и контрол на репликацията на данни.
- Спиране/Стартиране:За да накарате подчинения да спре/започне репликацията.
- Slave:Подчинен възел за репликация.
- Cluster-id:Идентификаторът на клъстера, в който е подчинения възел.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Нулиране на подчинено устройство за репликация
Използвайки тази команда, можете да нулирате процеса на репликация, като използвате RESET SLAVE или RESET SLAVE ALL. За повече информация относно тази команда, моля, проверете използването й в предишния раздел на потребителския интерфейс на ClusterControl.
Преди да използвате тази функция, трябва да спрете процеса на репликация (моля, вижте предишната команда).
НУЛИРАНЕ НА ДОБРЕНО:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logРегистърът трябва да бъде като:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.НУЛИРАНЕ НА ВСИЧКО ДОБРЕНО:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logИ този регистрационен файл трябва да бъде:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Нека видим използваните параметри както за НУЛИРАНЕ НА ПЛАВЕНО, така и за НУЛИРАНЕ НА ВСИЧКИ ДЛЪЖЕН.
- Репликация:За наблюдение и контрол на репликацията на данни.
- Нулиране:Нулирайте подчинения възел.
- Принудително:Използвайки този флаг, ще използвате командата RESET SLAVE ALL на подчинения възел.
- Slave:Подчинен възел за репликация.
- Cluster-id:Идентификаторът на подчинения клъстер.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Заключение
Тази нова функция ClusterControl ще ви позволи бързо да създавате репликация от клъстер към клъстер и да я управлявате по лесен и удобен начин. Тази среда ще подобри топологията на вашата база данни/клъстер и би била полезна за план за възстановяване след бедствие, среда за тестване и още повече опции, споменати в блога за преглед.



