Galera Cluster идва с много забележителни функции, които не са налични в стандартната MySQL репликация (или групова репликация); автоматично осигуряване на възли, истински мулти-мастер с разрешаване на конфликти и автоматично преминаване при отказ. Съществуват и редица ограничения, които потенциално могат да повлияят на производителността на клъстера. За щастие, ако не сте наясно с тях, има заобиколни решения. И ако го направите правилно, можете да сведете до минимум въздействието на тези ограничения и да подобрите цялостната производителност.
По-рано разгледахме много съвети и трикове, свързани с Galera Cluster, включително стартиране на Galera в AWS Cloud. Тази публикация в блога се потапя ясно в аспектите на производителността, с примери за това как да извлечете максимума от Galera.
Полезен товар за репликация
Малко въведение - Galera репликира набори за запис по време на етапа на комит, прехвърляйки набори за запис от възела инициатор към възлите на приемника синхронно чрез приставката за репликация wsrep. Този плъгин също ще сертифицира набори за запис на възлите на приемника. Ако процесът на сертифициране премине, той връща OK на клиента на възела инициатор и ще бъде приложен към възлите на приемника по-късно асинхронно. В противен случай транзакцията ще бъде върната на възела на инициатора (връщане на грешка към клиента) и наборите за запис, които са били прехвърлени към възлите на получателя, ще бъдат отхвърлени.
Наборът за запис се състои от операции за запис в транзакция, която променя състоянието на базата данни. В Galera Cluster, автоматично попълване е по подразбиране 1 (разрешено). Буквално всеки SQL оператор, изпълнен в Galera Cluster, ще бъде затворен като транзакция, освен ако не започнете изрично с BEGIN, START TRANSACTION или SET autocommit=0. Следната диаграма илюстрира капсулирането на единичен DML израз в набор за запис:
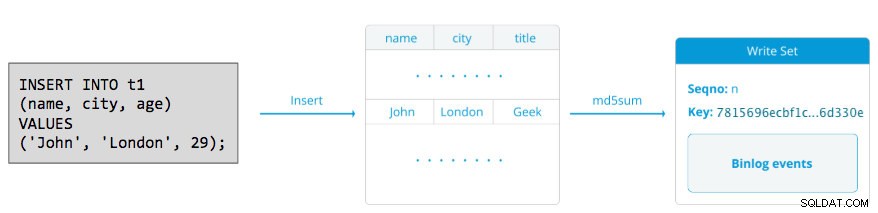
За DML (INSERT, UPDATE, DELETE..), полезният товар на набора за запис се състои от двоични събития в дневника за конкретна транзакция, докато за DDL (ALTER, GRANT, CREATE..), полезният товар на набора за запис е самият DDL оператор. За DML, наборът за запис ще трябва да бъде сертифициран срещу конфликти на приемния възел, докато за DDL (в зависимост от wsrep_osu_method , по подразбиране на TOI), клъстерът на клъстера изпълнява оператора DDL на всички възли в една и съща последователност на общите поръчки, блокирайки други транзакции от извършване, докато DDL е в ход (вижте също RSU). С прости думи, Galera Cluster обработва DDL и DML репликацията по различен начин.
Време за двупосочно пътуване
Като цяло следните фактори определят колко бързо Galera може да репликира набор за запис от възел-инициатор към всички възли-получатели:
- Време за двупосочно пътуване (RTT) до най-отдалечения възел в клъстера от възела инициатор.
- Размерът на набор за запис, който трябва да бъде прехвърлен и сертифициран за конфликт на приемния възел.
Например, ако имаме клъстер Galera с три възела и един от възлите се намира на 10 милисекунди (0,01 секунда), е много малко вероятно да успеете да пишете повече от 100 пъти в секунда в един и същи ред без конфликт. Има популярен цитат от Mark Callaghan, който описва това поведение доста добре:
„[В клъстер на Galera] даден ред не може да бъде променен повече от веднъж на RTT“
За да измерите стойността на RTT, просто изпълнете ping на възела инициатор до най-отдалечения възел в клъстера:
$ ping 192.168.55.173 # the farthest nodeИзчакайте няколко секунди (или минути) и прекратете командата. Последният ред от секцията за пинг статистика е това, което търсим:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msмакс. стойността е 1,340 ms (0,00134 s) и трябва да вземем тази стойност, когато оценяваме минималното транзакции в секунда (tps) за този клъстер. Средното стойността е 0,431 мс (0,000431 s) и можем да използваме, за да изчислим средната стойност tps докато мин стойността е 0,111 ms (0,000111 s), която можем да използваме, за да изчислим максимума tps mdev означава как са били разпределени RTT пробите от средната стойност. По-ниската стойност означава по-стабилен RTT.
Следователно транзакциите в секунда могат да бъдат оценени чрез разделяне на RTT (в секунда) на 1 секунда:

В резултат,
- Минимални tps:1 / 0,00134 (макс. RTT) =746,26 ~ 746 tps
- Средна tps:1 / 0,000431 (ср. RTT) =2320,19 ~ 2320 tps
- Максимален tps:1 / 0,000111 (мин RTT) =9009,01 ~ 9009 tps
Имайте предвид, че това е само оценка за предвиждане на производителността на репликация. Не можем да направим много, за да подобрим това от страна на базата данни, след като всичко е разгърнато и работи. Освен ако преместите или мигрирате сървърите на бази данни по-близо един до друг, за да подобрите RTT между възлите или да надстроите периферните устройства или инфраструктурата на мрежата. Това ще изисква прозорец за поддръжка и правилно планиране.
Разбийте големи транзакции
Друг фактор е размерът на транзакцията. След като наборът за запис бъде прехвърлен, ще има процес на сертифициране. Сертифицирането е процес за определяне дали възелът може да приложи набора за запис или не. Galera генерира псевдоключове за контролна сума MD5 от всеки пълен ред. Цената на сертифицирането зависи от размера на набора за запис, което се изразява в редица уникални ключове за търсене в индекса за сертифициране (хеш таблица). Ако актуализирате 500 000 реда в една транзакция, например:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Горното ще генерира единичен набор за запис с 500 000 двоични регистрационни събития в него. Този огромен набор за запис не надвишава wsrep_max_ws_size (по подразбиране на 2GB), така че ще бъде прехвърлен от приставката за репликация на Galera към всички възли в клъстера, удостоверявайки тези 500 000 реда на възлите на приемника за всякакви конфликтни транзакции, които все още са в подчинената опашка. Накрая статусът на сертифициране се връща на приставката за групова репликация. Колкото по-голям е размерът на транзакцията, толкова по-голям е рискът тя да бъде в конфликт с други транзакции, които идват от друг главен. Конфликтните транзакции губят ресурсите на сървъра, плюс причиняват огромно връщане назад към възела на инициатора. Обърнете внимание, че операцията за връщане назад в MySQL е много по-бавна и по-малко оптимизирана от операцията за записване.
Горният SQL оператор може да бъде пренаписан в по-удобен за Galera израз с помощта на прост цикъл, като примера по-долу:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneГорната команда на обвивката ще актуализира 1000 реда на транзакция 500 пъти и ще изчака 2 секунди между изпълненията. Можете също да използвате съхранена процедура или други средства, за да постигнете подобен резултат. Ако пренаписването на SQL заявката не е опция, просто инструктирайте приложението да изпълни голямата транзакция по време на прозорец за поддръжка, за да намалите риска от конфликти.
За огромни изтривания помислете за използването на pt-архиватор от Percona Toolkit – работа с ниско въздействие и само напред, за да изтриете стари данни от таблицата, без да влияете много на OLTP заявките.
Паралелни подчинени нишки
В Galera приложението е многонишков процес. Applier е нишка, работеща в Galera за прилагане на входящите набори за запис от друг възел. Което означава, че е възможно всички приемници да изпълняват множество DML операции, които идват направо от иницииращия (главен) възел едновременно. Паралелната репликация на Galera се прилага само към транзакции, когато е безопасно да се направи това. Подобрява вероятността възелът да се синхронизира с възела инициатор. Скоростта на репликация обаче все още е ограничена до RTT и размера на набора за запис.
За да извлечем най-доброто от това, трябва да знаем две неща:
- Броят на ядрата, които сървърът има.
- Стойността на wsrep_cert_deps_distance състояние.
Състоянието wsrep_cert_deps_distance ни казва потенциалната степен на успоредяване. Това е стойността на средното разстояние между най-високите и най-ниските стойности на seqno, които могат да бъдат приложени паралелно. Можете да използвате wsrep_cert_deps_distance променлива на състоянието, за да определите максималния възможен брой подчинени нишки. Имайте предвид, че това е средна стойност във времето. Следователно, за да получите добра стойност, трябва да ударите клъстера с операции за запис чрез тестово натоварване или сравнителен тест, докато не видите стабилна стойност.
За да получите броя на ядрата, можете просто да използвате следната команда:
$ grep -c processor /proc/cpuinfo
4В идеалния случай 2, 3 или 4 нишки подчинен апликатор на ядро на процесора е добро начало. По този начин минималната стойност за подчинените нишки трябва да бъде 4 пъти броя на процесорните ядра и не трябва да надвишава wsrep_cert_deps_distance стойност:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Можете да контролирате броя на подчинените нишки на приложението, като използвате wsrep_slave_thread променлива. Въпреки че това е динамична променлива, само увеличаването на броя ще има незабавен ефект. Ако намалите стойността динамично, ще отнеме известно време, докато нишката на приложението излезе, след като приключи прилагането. Препоръчителната стойност е някъде между 16 и 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Обърнете внимание, че за да работят паралелни подчинени нишки, трябва да бъде зададено следното (което обикновено е предварително конфигурирано за Galera Cluster):
innodb_autoinc_lock_mode=2Кеш на Galera (gcache)
Galera използва предварително разпределен файл със специфичен размер, наречен gcache, където възел на Galera съхранява копие на набори за запис в стил на кръгов буфер. По подразбиране размерът му е 128MB, което е доста малко. Инкременталното прехвърляне на състояние (IST) е метод за подготовка на съединител чрез изпращане само на липсващите набори за запис, налични в gcache на донора. IST е по-бърз от прехвърлянето на моментна снимка на състоянието (SST), не е блокиращ и няма значително въздействие върху производителността върху донора. Това трябва да бъде предпочитаната опция, когато е възможно.
IST може да бъде постигнат само ако всички промени, пропуснати от съединителя, все още са в gcache файла на донора. Препоръчителната настройка за това е да бъде толкова голяма, колкото целия набор от данни на MySQL. Ако дисковото пространство е ограничено или скъпо, определянето на правилния размер на размера на gcache е от решаващо значение, тъй като може да повлияе на производителността на синхронизиране на данни между възлите на Galera.
Изявлението по-долу ще ни даде представа за количеството данни, репликирани от Galera. Изпълнете следния оператор на един от възлите на Galera по време на пиковите часове (тестван на MariaDB>10.0 и PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Можем да преценим, че възелът Galera може да има приблизително 16 минути престой, без да се изисква SST да се присъедини (освен ако Galera не може да определи състоянието на свързване). Ако това е твърде кратко време и имате достатъчно дисково пространство на вашите възли, можете да промените wsrep_provider_options="gcache.size=
Също така се препоръчва да използвате gcache.recover=yes в wsrep_provider_options (Galera>3.19), където Galera ще се опита да възстанови gcache файла до използваемо състояние при стартиране, вместо да го изтрие, като по този начин запазва възможността да има IST и избягва SST колкото е възможно повече. Codership и Percona са разгледали подробно това в своите блогове. IST винаги е най-добрият метод за синхронизиране, след като възел се присъедини отново към клъстера. Той е 50% по-бърз от xtrabackup или mariabackup и 5 пъти по-бърз от mysqldump.
Асинхронно подчинено устройство
Възлите на Galera са тясно свързани, при което производителността на репликация е толкова бърза, колкото и най-бавният възел. Galera използва механизъм за контрол на потока, за да контролира потока на репликация между членовете и да елиминира всяко подчинено забавяне. Репликацията може да бъде изцяло бърза или бавна на всеки възел и се настройва автоматично от Galera. Ако искате да научите за контрола на потока, прочетете тази публикация в блога на Jay Janssen от Percona.
В повечето случаи тежките операции като продължителна аналитика (интензивно четене) и архивиране (интензивно четене, заключване) често са неизбежни, което потенциално може да влоши производителността на клъстера. Най-добрият начин да изпълните този тип заявки е като ги изпратите до слабо свързан реплики сървър, например, асинхронен подчинен.
Асинхронно подчинено устройство се репликира от възел на Galera, използвайки стандартния MySQL протокол за асинхронна репликация. Няма ограничение за броя на подчинените устройства, които могат да бъдат свързани към един възел на Galera и е възможно свързването му с междинен главен. Операциите на MySQL, които се изпълняват на този сървър, няма да повлияят на производителността на клъстера, с изключение на първоначалната фаза на синхронизиране, където трябва да се направи пълно архивиране на възела Galera, за да се постави подчинения, преди да се установи връзката за репликация (въпреки че ClusterControl ви позволява да изградите асинхронния първо подчинен от съществуващ резервно копие, преди да го свържете към клъстера).
GTID (Global Transaction Identifier) осигурява по-добро картографиране на транзакциите между възли и се поддържа в MySQL 5.6 и MariaDB 10.0. С GTID операцията за преодоляване на срив на подчинен към друг главен (друг възел на Galera) е опростена, без да е необходимо да се определя точният регистрационен файл и позицията. Galera също идва със собствена реализация на GTID, но тези две са независими един от друг.
Мащабирането на асинхронно подчинено устройство е с едно щракване, ако използвате функцията ClusterControl -> Добавяне на подчинено устройство за репликация:
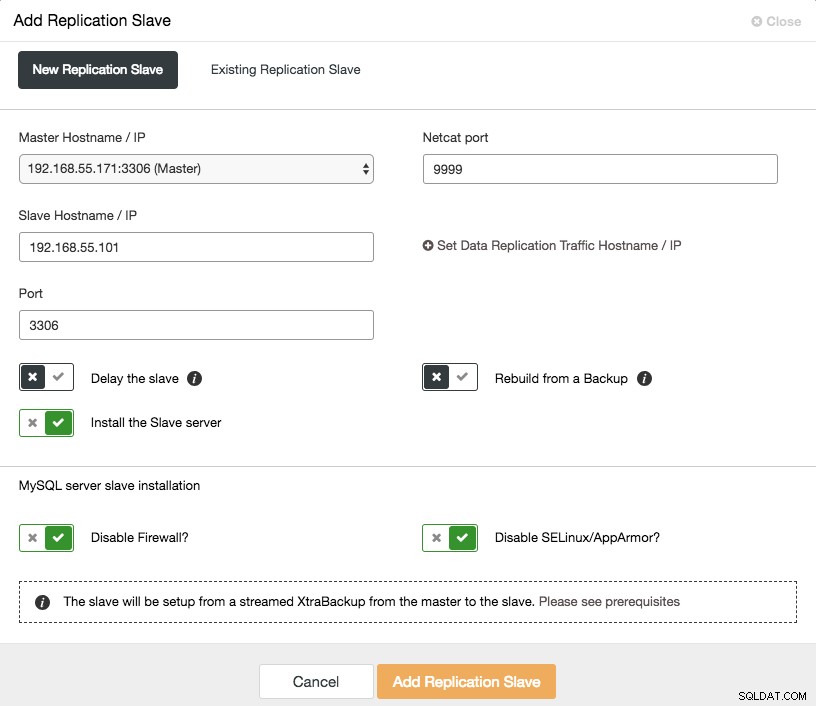
Обърнете внимание, че двоичните регистрационни файлове трябва да бъдат активирани на главния (избрания възел на Galera), преди да можем да продължим с тази настройка. Ние също така разгледахме ръчния начин в тази предишна публикация.
Следната екранна снимка от ClusterControl показва топологията на клъстера, тя илюстрира нашата архитектура на клъстер Galera с асинхронен подчинен:
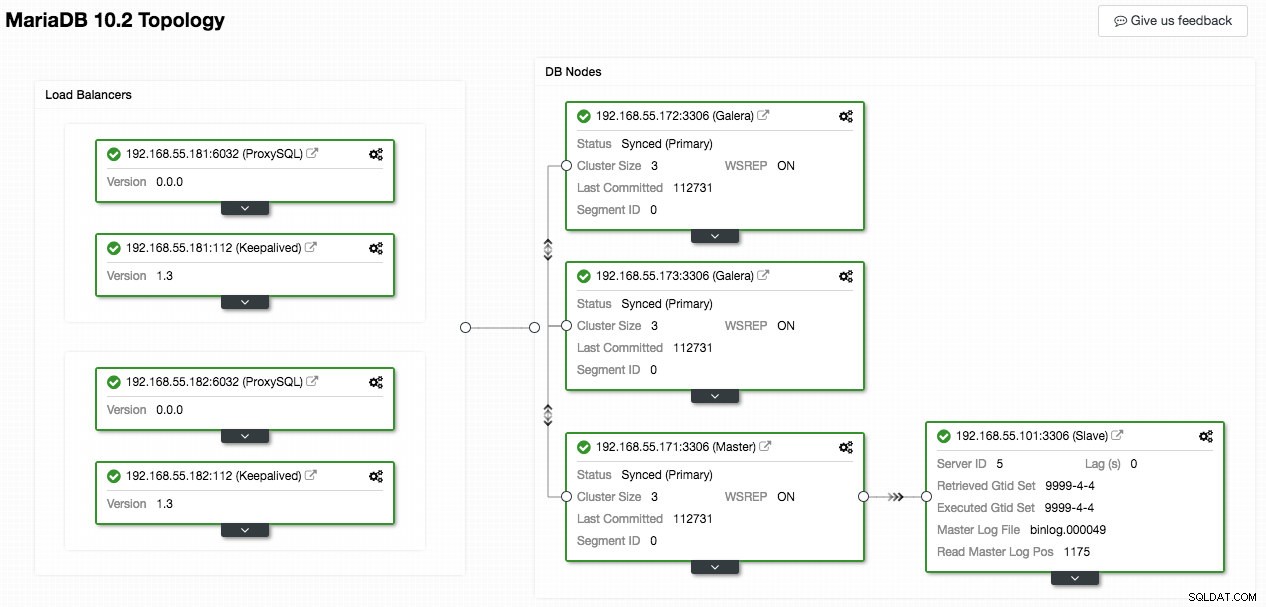
ClusterControl автоматично открива топологията и генерира супер готина диаграма, както по-горе. Можете също да изпълнявате административни задачи директно от тази страница, като щракнете върху иконата на зъбно колело горе вдясно на всяко поле.
Обратно прокси, поддържащо SQL
ProxySQL и MariaDB MaxScale са интелигентни обратни прокси сървъри, които разбират MySQL протокола и могат да действат като шлюз, рутер, балансьор на натоварване и защитна стена пред вашите възли на Galera. С помощта на доставчик на виртуални IP адреси като LVS или Keepalived, и комбинирайки това с технологията за репликация с множество глави на Galera, можем да имаме високодостъпна услуга за база данни, елиминирайки всички възможни единични откази (SPOF) от точката на приложение -от изглед. Това със сигурност ще подобри достъпността и надеждността на архитектурата като цяло.
Друго предимство с този подход е, че ще имате възможността да наблюдавате, пренаписвате или пренасочвате входящите SQL заявки въз основа на набор от правила, преди да ударят действителния сървър на база данни, като минимизирате промените от страна на приложението или клиента и насочвате заявките към по-подходящ възел за оптимална производителност. Рисковите заявки за Galera като LOCK TABLES и FLUSH TABLES WITH READ LOCK могат да бъдат предотвратени много напред, преди да причинят хаос в системата, като същевременно могат да повлияят на заявки като заявки за „гореща точка“ (ред, до който различни заявки искат да имат достъп по едно и също време) да бъдат пренаписани или пренасочени към един възел на Galera, за да се намали рискът от конфликти на транзакции. За тежки заявки само за четене, като OLAP или архивиране, можете да ги насочите към асинхронен подчинен, ако имате такъв.
Обратното прокси също следи състоянието на базата данни, заявките и променливите, за да разбере промените в топологията и да произведе точно решение за маршрутизиране към бекенд сървърите. Косвено, той централизира наблюдението на възлите и прегледа на клъстера, без да е необходимо редовно да проверявате всеки един възел на Galera. Следната екранна снимка показва таблото за наблюдение на ProxySQL в ClusterControl:
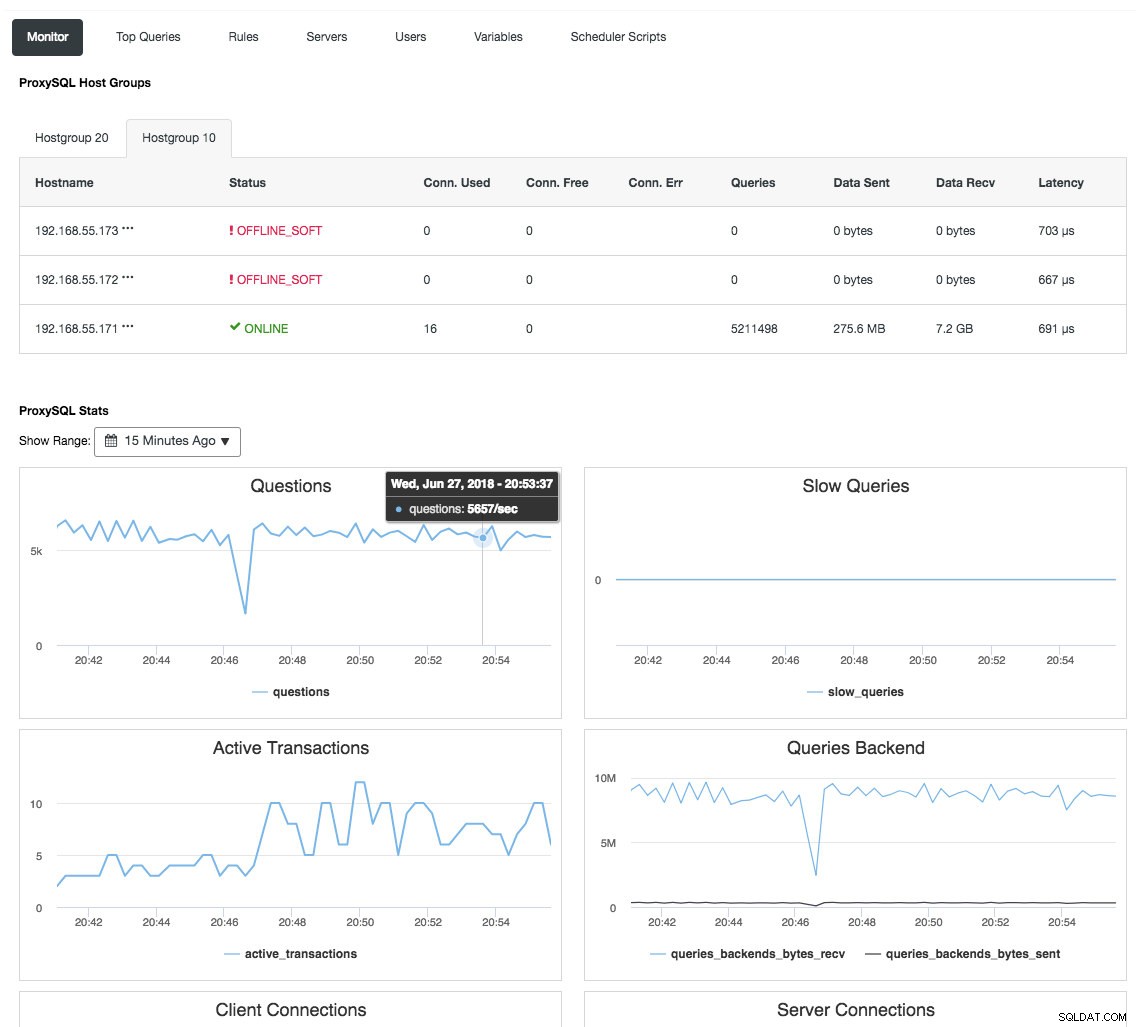
Има и много други предимства, които балансьорът на натоварване може да донесе, за да подобри значително Galera Cluster, както е разгледано подробно в тази публикация в блога, Станете ClusterControl DBA:Направете вашите DB компоненти HA чрез Load Balancers.
Последни мисли
С добро разбиране за това как Galera Cluster работи вътрешно, можем да заобиколим някои от ограниченията и да подобрим услугата за база данни. Приятно групиране!