Изпълнението на бази данни в облачна инфраструктура става все по-популярно в наши дни. Въпреки че облачната виртуална машина може да не е толкова надеждна като сървър от корпоративен клас, основните доставчици на облачни услуги предлагат различни инструменти за увеличаване на наличността на услугите. В тази публикация в блога ще ви покажем как да проектирате вашата база данни MySQL или MariaDB за висока наличност в облака. Ще разгледаме специално уеб услугите на Amazon и Google Cloud Platform, но повечето от съветите могат да се използват и с други доставчици на облак.
И AWS, и Google предлагат услуги за бази данни в своите облаци и тези услуги могат да бъдат конфигурирани за висока наличност. Възможно е да имате копия в различни зони за наличност (или зони в GCP), за да увеличите шансовете си да оцелеете при частичен отказ на услуги в рамките на даден регион. Въпреки че хостваната услуга е много удобен начин за стартиране на база данни, имайте предвид, че услугата е проектирана да се държи по специфичен начин и който може или не може да отговаря на вашите изисквания. Така например, AWS RDS за MySQL има доста ограничен списък от опции, когато става въпрос за обработка на отказ. Разгръщанията с няколко AZ идват с 60-120 секунди време за преодоляване на отказ съгласно документацията. Всъщност, като се има предвид, че „сенчестият“ екземпляр на MySQL трябва да започне от „повреден“ набор от данни, това може да отнеме дори повече време, тъй като може да се изисква повече работа за прилагане или връщане на транзакции от InnoDB регистрационни файлове за повторно изпълнение. Има опция да повишите роба в главен, но това не е възможно, тъй като не можете да подчинявате съществуващите подчинени устройства от новия главен. В случай на управлявана услуга, тя също така е по-сложна и по-трудна за проследяване на проблемите с производителността. Повече прозрения за RDS за MySQL и неговите ограничения в тази публикация в блога.
От друга страна, ако решите да управлявате базите данни, вие сте в различен свят на възможности. Редица неща, които можете да правите на гол метал, са възможни и в екземпляри на EC2 или Compute Engine. Нямате режийни разходи по управлението на основния хардуер и въпреки това запазвате контрола върху това как да проектирате системата. Има две основни опции при проектиране за наличност на MySQL - MySQL репликация и Galera Cluster. Нека ги обсъдим.
Репликация на MySQL
MySQL репликацията е често срещан начин за мащабиране на MySQL с множество копия на данните. Асинхронен или полусинхронен, той позволява да се разпространяват промени, извършени от един записващ, главния, към реплики/подчинени устройства - всяка от които ще съдържа пълния набор от данни и може да бъде повишена, за да стане нов главен. Репликацията може да се използва и за мащабиране на четенията, чрез насочване на трафика за четене към реплики и разтоварване на главния по този начин. Основното предимство на репликацията е лекотата на използване - тя е толкова широко известна и популярна (също така е лесна за конфигуриране), че има много ресурси и инструменти, които да ви помогнат да го управлявате и конфигурирате. Нашият собствен ClusterControl е един от тях – можете да го използвате за лесно разгръщане на настройка за репликация на MySQL с интегрирани балансатори на натоварването, управление на промените в топологията, преодоляване/възстановяване и т.н.
Един основен проблем с репликацията на MySQL е, че тя не е проектирана да обработва разделяне на мрежата или повреда на главния. Ако майсторът падне, трябва да популяризирате една от репликите. Това е ръчен процес, въпреки че може да бъде автоматизиран с външни инструменти (например ClusterControl). Също така няма механизъм за кворум и няма поддръжка за ограждане на неуспешни главни екземпляри в MySQL репликация. За съжаление, това може да доведе до сериозни проблеми в разпределени среди – ако повишите нов главен, докато старият ви се върне онлайн, може в крайна сметка да пишете на два възела, създавайки отклонение на данните и причинявайки сериозни проблеми с последователността на данните.
Ще разгледаме някои примери по-късно в тази публикация, които ви показват как да откриете разделяне на мрежата и да приложите STONITH или някакъв друг механизъм за ограждане за вашата настройка на MySQL репликация.
Galera Cluster
Видяхме в предишния раздел, че при репликацията на MySQL липсва ограда и поддръжка на кворум – това е мястото, където Galera Cluster блести. Той има вградена поддръжка на кворум, също така има механизъм за ограждане, който не позволява на разделени възли да приемат записи. Това прави Galera Cluster по-подходящ от репликацията в настройки с множество центрове за данни. Galera Cluster също поддържа множество писатели и е в състояние да разрешава конфликти при писане. Следователно не сте ограничени до един записващ в настройка с множество центрове за данни, възможно е да имате записващо устройство във всеки център за данни, което намалява латентността между нивото на вашето приложение и база данни. Това не ускорява записите, тъй като всяко записване все още трябва да се изпраща до всеки възел на Galera за сертифициране, но все пак е по-лесно, отколкото да изпращате записи от всички сървъри на приложения през WAN до един-единствен отдалечен главен обект.
Колкото и да е добър Galera, той не винаги е най-добрият избор за всички натоварвания. Galera не е заместител на MySQL/InnoDB. Той споделя общи характеристики с „нормалния“ MySQL – използва InnoDB като машина за съхранение, съдържа целия набор от данни на всеки възел, което прави JOIN осъществими. И все пак, някои от характеристиките на производителността на Galera (като производителността на записи, които са засегнати от мрежовата латентност) се различават от това, което бихте очаквали от настройките за репликация. Поддръжката също изглежда различно:обработката на промяна на схемата работи малко по-различно. Някои дизайни на схеми не са оптимални:ако имате горещи точки във вашите таблици, като често актуализирани броячи, това може да доведе до проблеми с производителността. Има и разлика в най-добрите практики, свързани с пакетната обработка – вместо да изпълнявате заявки в големи транзакции, искате транзакциите ви да са малки.
Прокси ниво
Много е трудно и тромаво да се изгради високодостъпна настройка без прокси сървъри. Разбира се, можете да пишете код във вашето приложение, за да следите екземпляри на база данни, да списвате нездравословните в черния списък, да следите главния(ите) за записване и т.н. Но това е много по-сложно от просто изпращане на трафик към една крайна точка - където идва прокси. ClusterControl ви позволява да разгръщате ProxySQL, HAProxy и MaxScale. Ще дадем някои примери с помощта на ProxySQL, тъй като той ни дава добра гъвкавост при контролиране на трафика на база данни.
ProxySQL може да бъде разгърнат по няколко начина. Като за начало, той може да бъде разгърнат на отделни хостове и Keepalived може да се използва за предоставяне на виртуален IP. Виртуалният IP ще бъде преместен, ако някой от екземплярите на ProxySQL се провали. В облака тази настройка може да бъде проблематична, тъй като добавянето на IP към интерфейса обикновено не е достатъчно. Ще трябва да модифицирате конфигурацията и скриптовете на Keepalived, за да работят с еластичен IP (или статичен - но може да бъде извикан от вашия доставчик на облак). Тогава човек ще използва облачен API или CLI, за да премести този IP адрес към друг хост. Поради тази причина бихме предложили да разпределите ProxySQL заедно с приложението. Всеки сървър на приложения ще бъде конфигуриран да се свързва с локалния ProxySQL, използвайки Unix сокети. Тъй като ProxySQL използва ангелски процес, сривовете на ProxySQL могат да бъдат открити/рестартирани в рамките на секунда. В случай на хардуерен срив, този конкретен сървър на приложения ще изпадне заедно с ProxySQL. Останалите сървъри на приложения все още могат да имат достъп до съответните им локални копия на ProxySQL. Тази конкретна настройка има допълнителни функции. Сигурност - ProxySQL, от версия 1.4.8, няма поддръжка за SSL от страна на клиента. Той може да настрои само SSL връзка между ProxySQL и бекенда. Колокирането на ProxySQL на хоста на приложението и използването на Unix сокети е добро решение. ProxySQL също има способността да кешира заявки и ако ще използвате тази функция, има смисъл да я държите възможно най-близо до приложението, за да намалите латентността. Препоръчваме ви да използвате този модел за внедряване на ProxySQL.
Типични настройки
Нека да разгледаме примери за високодостъпни настройки.
Единен център за данни, MySQL репликация
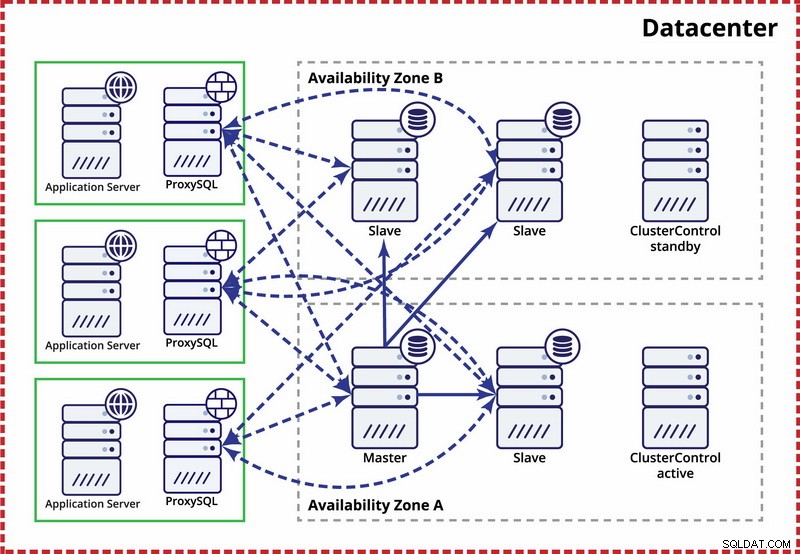
Предположението тук е, че има две отделни зони в центъра за данни. Всяка зона има излишно и отделно захранване, мрежа и свързаност, за да се намали вероятността две зони да се повредят едновременно. Възможно е да се настрои топология на репликация, обхващаща и двете зони.
Тук използваме ClusterControl за управление на отказ. За да разрешим сценария с разделяне на мозъка между зоните за наличност, ние разпределяме активния ClusterControl с главния. Ние също така поставяме в черния списък подчинени устройства в другата зона на наличност, за да сме сигурни, че автоматичното преминаване на отказ няма да доведе до налични два главни.
Множество центрове за данни, MySQL репликация
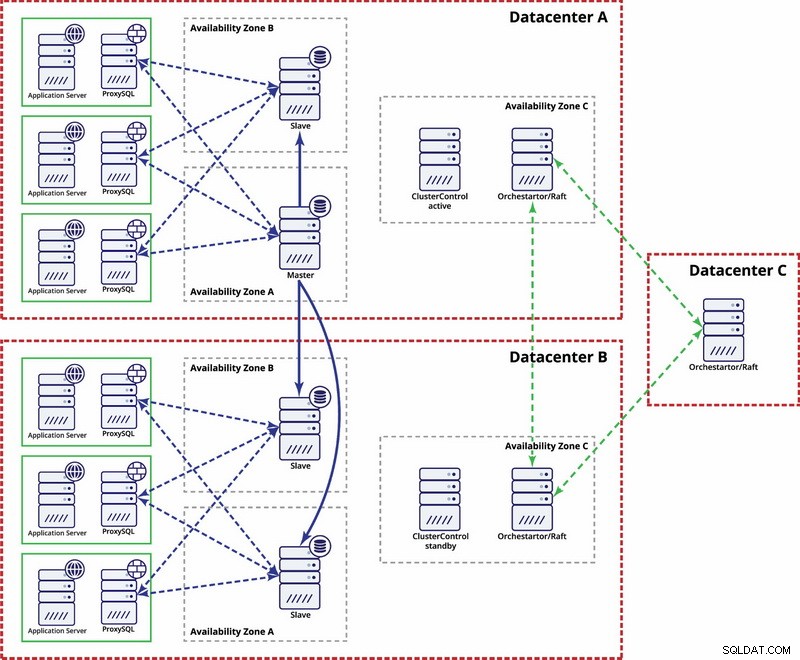
В този пример използваме три центъра за данни и Orchestrator/Raft за изчисляване на кворума. Може да се наложи да напишете свои собствени скриптове за внедряване на STONITH, ако master е в разделения сегмент на инфраструктурата. ClusterControl се използва за възстановяване на възли и функции за управление.
Множество центрове за данни, клъстер Galera
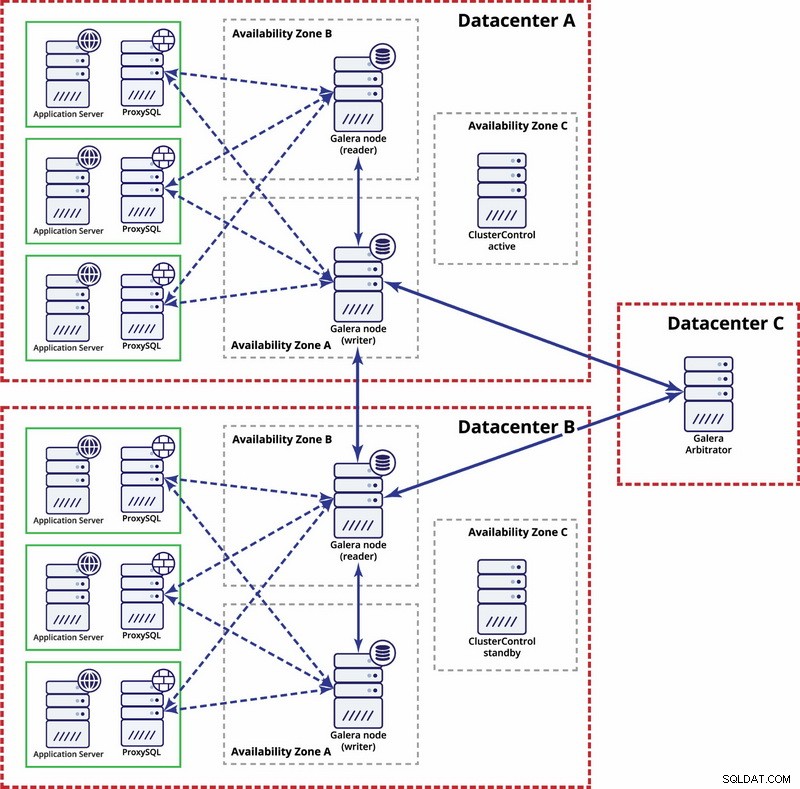
В този случай използваме три центъра за данни с арбитър на Galera в третия - това прави възможно справянето с целия отказ на центъра за данни и намалява риска от разделяне на мрежата, тъй като третият център за данни може да се използва като реле.
За по-нататъшно четене, разгледайте белия документ „Как да проектираме високодостъпни среди за бази данни с отворен код“ и гледайте повторението на уебинара „Проектиране на бази данни с отворен код за висока достъпност“.