Нетърпеливи ли да научите всичко и всичко за клъстера Hadoop?
Hadoop е софтуерна рамка за анализиране и съхраняване на огромни количества данни в клъстери от обикновен хардуер. В тази статия ще изучаваме Hadoop клъстер.
Нека първо започнем с въведение в Cluster.
Какво е клъстер?
Клъстерът е колекция от възли. Възлите не са нищо друго освен точка на връзка/пресичане в рамките на мрежа.
Компютърният клъстер е съвкупност от компютри, свързани с мрежа, които могат да комуникират помежду си и работят като единна система.
Какво е Hadoop Cluster?
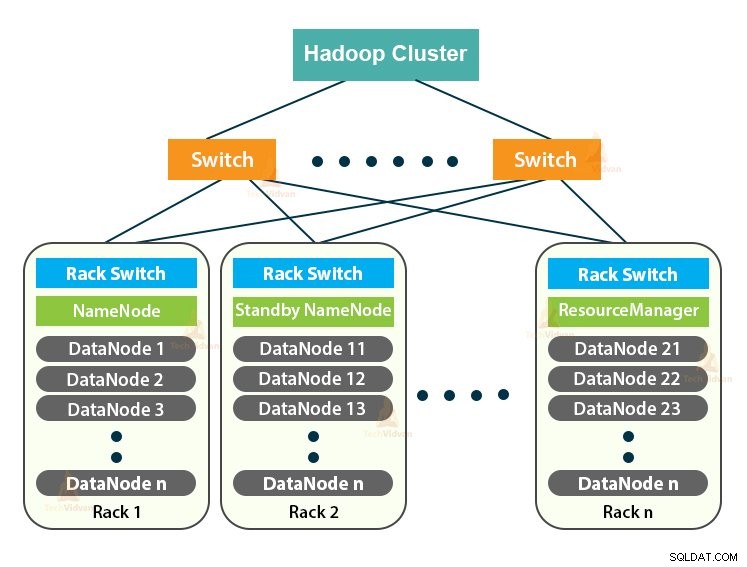
Hadoop Cluster е просто компютърен клъстер, използван за обработка на огромно количество данни по разпределен начин.
Това е изчислителен клъстер, предназначен за съхранение, както и за анализиране на огромни количества неструктурирани или структурирани данни в разпределена изчислителна среда.
Клъстерите Hadoop са известни още като системи без споделено нищо защото нищо не се споделя между възлите в клъстера освен мрежовата честотна лента. Това намалява забавянето на обработката.
По този начин, когато има нужда от обработка на заявки за огромно количество данни, забавянето в целия клъстер се свежда до минимум.
Нека сега проучим архитектурата на клъстера Hadoop.
Архитектура на Hadoop клъстер
Клъстерът Hadoop следва архитектура главен-подчинен. Състои се от главен възел, подчинен възел и клиентски възел.
1. Майстор в Hadoop клъстер
Master в Hadoop Cluster е машина с висока мощност с висока конфигурация на памет и процесор. Двата демона, които са NameNode и ResourceManager, работят на главния възел.
a. Функции на NameNode
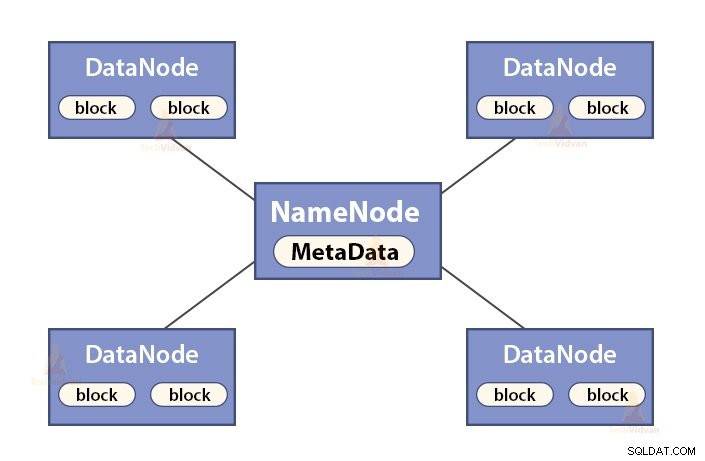
NameNode е главен възел в Hadoop HDFS . NameNode управлява пространството от имена на файловата система. Той съхранява метаданни на файловата система в паметта за бързо извличане. Следователно, той трябва да бъде конфигуриран на машини от висок клас.
Функциите на NameNode са:
- Управлява пространството от имена на файловата система
- Съхранява метаданни за блокове на файл, местоположение на блокове, разрешения и т.н.
- Той изпълнява операции на файловата система за пространство от имена като отваряне, затваряне, преименуване на файлове и директории и т.н.
- Поддържа и управлява DataNode.
б. Функции на Resource Manager
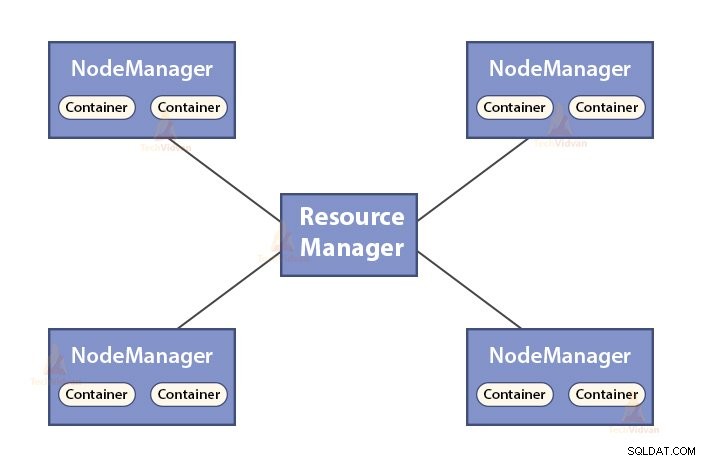
- ResourceManager е главният демон на YARN.
- ResourceManager управлява ресурсите между всички приложения в системата.
- Той следи живи и мъртви възли в клъстера.
2. Роби в клъстера Hadoop
Подчинените в клъстера Hadoop са евтин стоков хардуер. Двата демона, които са DataNodes и YARN NodeManagers, работят на подчинените възли.
a. Функции на DataNodes
- DataNodes съхранява действителните бизнес данни. Той съхранява блоковете на файл.
- Той извършва създаване, изтриване, репликация на блок въз основа на инструкциите от NameNode.
- DataNode е отговорен за обслужването на клиентски операции за четене/запис.
б. Функции на NodeManager
- NodeManager е подчинения демон на YARN.
- Той отговаря за контейнерите, наблюдава тяхното използване на ресурсите (като процесор, диск, памет, мрежа) и отчита същото на ResourceManager.
- NodeManager също така проверява здравето на възела, на който се изпълнява.
3. Клиентски възел в клъстер Hadoop
Клиентските възли в Hadoop не са нито главен възел, нито подчинени възли. Имат инсталиран Hadoop с всички настройки на клъстера.
Функции на клиентски възли
- Клиентските възли зареждат данни в клъстера Hadoop.
- Изпраща задания на MapReduce, като описва как трябва да се обработват тези данни.
- Извличане на резултатите от заданието след приключване на обработката.
Можем да мащабираме клъстера Hadoop, като добавим още възли. Това прави Hadoop линейно мащабируем . С всяко добавяне на възел получаваме съответно увеличение на пропускателната способност. Ако имаме „n“ възли, тогава добавянето на 1 възел дава (1/n) допълнителна изчислителна мощност.
Hadoop клъстер с един възел срещу Hadoop клъстер с много възли
1. Hadoop клъстер с един възел
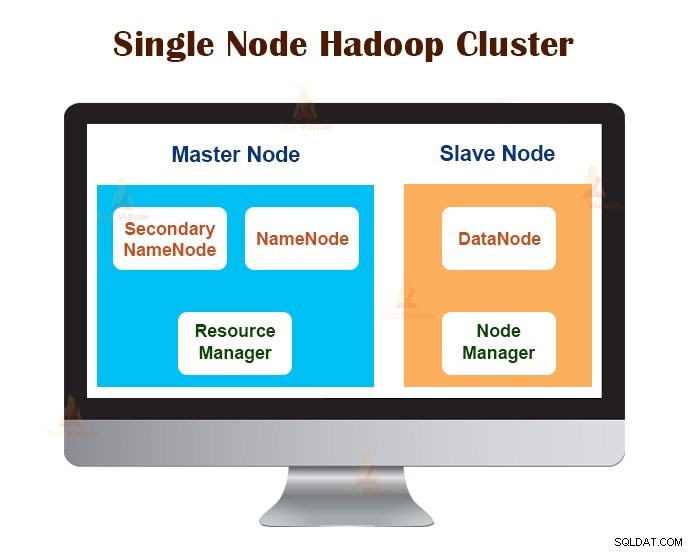
Hadoop клъстер с един възел е разположен на една машина. Всички демони като NameNode, DataNode, ResourceManager, NodeManager работят на една и съща машина/хост.
При настройка на клъстер с един възел всичко работи на един JVM екземпляр. Потребителят на Hadoop не трябваше да прави никакви конфигурационни настройки, освен да зададе променливата JAVA_HOME.
Коефициентът на репликация по подразбиране за един възел Hadoop клъстер винаги е 1.
2. Hadoop клъстер с много възли
Multi-Node Hadoop Cluster се разполага на множество машини. Всички демони в клъстера Hadoop с множество възли са стартирани и работят на различни машини/хостове.
Hadoop клъстер с множество възли следва архитектурата главен-подчинен. Демоните Namenode и ResourceManager работят на главните възли, които са компютърни машини от висок клас.
Демоните DataNodes и NodeManagers работят на подчинените възли (работни възли), които са евтин хардуер за стоки.
В клъстера Hadoop с множество възли подчинените машини могат да присъстват на всяко място, независимо от местоположението на физическото местоположение на главния сървър.
Комуникационни протоколи, използвани в Hadoop Cluster
Комуникационните протоколи HDFS са наслоени в горната част на TCP/IP протокола. Клиентът установява връзка с NameNode чрез конфигурируемия TCP порт на NameNode машината.
Клъстерът Hadoop установява връзка с клиента чрез ClientProtocol. Освен това DataNode разговаря с NameNode, използвайки DataNode Protocol.
Абстракцията на Remote Procedure Call (RPC) обгръща протокола на клиента и протокола DataNode. По дизайн NameNode не инициира никакви RPC. Той отговаря само на RPC заявките, издадени от клиенти или DataNodes.
Най-добри практики за изграждане на Hadoop клъстер
Производителността на клъстер Hadoop зависи от различни фактори, базирани на добре оразмерените хардуерни ресурси, които използват процесор, памет, честотна лента на мрежата, твърд диск и други добре конфигурирани софтуерни слоеве.
Създаването на Hadoop клъстер е нетривиална работа. Това изисква отчитане на различни фактори като избор на правилния хардуер, оразмеряване на клъстерите Hadoop и конфигуриране на клъстера Hadoop.
Нека сега разгледаме всеки един от тях в подробности.
1. Избор на подходящ хардуер за Hadoop клъстер
Много организации, когато настройват инфраструктурата на Hadoop, са в затруднено положение, тъй като не са наясно с вида машини, които трябва да закупят, за да настроят оптимизирана среда на Hadoop и идеалната конфигурация, която трябва да използват.
За да изберете правилния хардуер за Hadoop Cluster, трябва да имате предвид следните точки:
- Обемът данни, които клъстерът ще обработва.
- Типа натоварвания, с които клъстерът ще работи (свързани с процесора, I/O).
- Методология за съхранение на данни, като контейнери за данни, използвани техники за компресиране на данни, ако има такива.
- Правила за запазване на данни, тоест колко дълго искаме да запазим данните, преди да ги изтрием.
2. Оразмеряване на клъстера Hadoop
За определяне на размера на клъстера Hadoop обемът данни, който потребителите на Hadoop ще обработват в клъстера Hadoop, трябва да бъде ключов фактор.
Познавайки обема на данните, които трябва да бъдат обработени, помага при вземането на решение колко възли ще са необходими за ефективна обработка на данните и необходим капацитет на паметта за всеки възел. Трябва да има баланс между производителността и цената на одобрения хардуер.
3. Конфигуриране на Hadoop клъстер
Намирането на идеалната конфигурация за Hadoop Cluster не е лесна работа. Hadoop рамката трябва да бъде адаптирана към клъстера, който изпълнява, както и към заданието.
Най-добрият начин да решите идеалната конфигурация за Hadoop Cluster е да стартирате Hadoop заданията с наличната конфигурация по подразбиране, за да получите базова линия. След това можем да анализираме регистрационните файлове на историята на заданията, за да видим дали има слабост на ресурсите или времето, необходимо за изпълнение на заданията, е по-голямо от очакваното.
Ако е така, променете конфигурацията. Повтарянето на същия процес може да настрои конфигурацията на Hadoop Cluster, която най-добре отговаря на бизнес изискванията.
Производителността на клъстера Hadoop зависи до голяма степен от ресурсите, разпределени на демоните. За контекст на малки и средни данни Hadoop запазва едно ядро на процесора на всеки DataNode, докато за дългите набори от данни заделя 2 процесорни ядра на всеки DataNode за демони HDFS и MapReduce.
Управление на клъстери Hadoop
При внедряването на Hadoop Cluster в производството е очевидно, че той трябва да се мащабира по всички измерения, които са обем, разнообразие и скорост.
Различни функции, които трябва да притежава, за да стане готов за производство, са – денонощна наличност, стабилност, управляемост и производителност. Управлението на клъстер Hadoop е основният аспект на инициативата за големи данни.
Най-добрият инструмент за управление на клъстер Hadoop трябва да има следните функции:-
- Трябва да гарантира 24×7 висока наличност, осигуряване на ресурси, разнообразна сигурност, управление на натоварването, наблюдение на здравето, оптимизиране на производителността. Освен това трябва да осигури планиране на задания, управление на правилата, архивиране и възстановяване на един или повече възли.
- Внедряване на излишен HDFS NameNode висока наличност с балансиране на натоварването, горещ режим на готовност, повторно синхронизиране и автоматично отказване.
- Прилагане на базирани на правила контроли, които не позволяват на което и да е приложение да грабне непропорционално голям дял от ресурси в вече изчерпания Hadoop клъстер.
- Извършване на регресионно тестване за управление на внедряването на всякакви софтуерни слоеве върху клъстери на Hadoop. Това е, за да се гарантира, че работата или данните няма да се сринат или да срещнат тесни места в ежедневните операции.
Предимства на Hadoop Cluster
Различните предимства, предоставени от Hadoop Cluster са:
1. Мащабируем
Hadoop клъстерите са мащабируеми. Можем да добавим произволен брой възли към клъстера Hadoop без престой и без допълнителни усилия. С всяко добавяне на възел получаваме съответно увеличение на пропускателната способност.
2. Здравост
Клъстерът Hadoop е най-известен със своето надеждно съхранение. Той може да съхранява данни надеждно, дори в случаи като повреда на DataNode, повреда на NameNode и мрежов дял. DataNode периодично изпраща сигнал за пулс до NameNode.
В мрежовия дял набор от DataNode се отделя от NameNode, поради което NameNode не получава сърдечен ритъм от тези DataNode. След това NameNode счита тези възли на данни за мъртви и не препраща никаква I/O заявка към тях.
Също така, коефициентът на репликация на блоковете, съхранени в тези DataNodes, пада под тяхната определена стойност. В резултат на това NameNode инициира репликацията на тези блокове и се възстановява след грешка.
3. Ребалансиране на клъстер
Архитектурата HDFS на Hadoop автоматично извършва ребалансиране на клъстера. Ако свободното пространство в DataNode падне под праговото ниво, тогава HDFS архитектурата автоматично премества някои данни в друг DataNode, където има достатъчно място.
4. Икономичен
Създаването на клъстер Hadoop е рентабилно, тъй като включва евтин хардуер. Всяка организация може лесно да настрои мощен Hadoop клъстер, без да харчи много за скъп сървърен хардуер.
Също така, клъстерите Hadoop със своята разпределена топология за съхранение преодоляват ограниченията на традиционната система. Ограниченото съхранение може да бъде разширено само чрез добавяне на допълнителни евтини единици за съхранение към системата.
5. Гъвкав
Hadoop клъстерите са много гъвкави, тъй като могат да обработват данни от всякакъв тип, структурирани, полуструктурирани или неструктурирани и с всякакви размери, вариращи от гигабайти до петабайти.
6. Бърза обработка
В Hadoop Cluster данните могат да се обработват паралелно в разпределена среда. Това осигурява бързи възможности за обработка на данни на Hadoop. Клъстерите Hadoop могат да обработват терабайти или петабайти данни за части от секунди.
7. Цялост на данните
За да провери за повреда в блоковете данни, дължаща се на бъгове в софтуера, грешки в устройство за съхранение и т.н. Hadoop Cluster прилага контролна сума за всеки блок от файла. Ако открие повреден блок, той го търси от друг DataNode, който съдържа репликата на същия блок. По този начин клъстерът Hadoop поддържа целостта на данните.
Резюме
След като прочетете тази статия, можем да кажем, че Hadoop Cluster е специален изчислителен клъстер, предназначен за анализиране и съхранение на големи данни. Hadoop Cluster следва архитектурата главен-подчинен.
Главният възел е компютърната машина от висок клас, а подчинените възли са машини с нормална конфигурация на процесора и паметта. Видяхме също, че Hadoop клъстерът може да бъде настроен на една машина, наречена Hadoop клъстер с един възел, или на множество машини, наречени Hadoop клъстер с много възли.
В тази статия разгледахме и най-добрите практики, които трябва да се следват при изграждането на Hadoop клъстер. Видяхме и много предимства на клъстера Hadoop, включително мащабируемост, гъвкавост, рентабилност и т.н.



