Това е писмената версия на новия ми видеоклип в YouTube ✍️ 🙂
В този урок за Redis ще научите за Redis и как Redis може да се използва като основна база данни за сложни приложения които трябва да съхраняват данни в множество формати.
Общ преглед 📝
- Какво представлява Redis и неговите употреби както и защо е подходящ за съвременни сложни микросервизни приложения?
- Как Redis поддържа съхраняване на множество формати на данни за различни цели чрез своите модули ?
- Как Redis като база данни в паметта може да запази данните и да се възстанови от загуба на данни ?
- Как да мащабирате и репликирате Redis ?
- Накрая, тъй като една от най-популярните платформи за стартиране на микроуслуги е Kubernetes и тъй като изпълнението на приложения с поддържане на състоянието в Kubernetes е малко предизвикателство, ще видим как можете лесно да изпълните Redis в Kubernetes
Какво е Redis?
Redis е съкращение от re мотедики речникси erver
Redis е база данни в паметта . Толкова много хора са го използвали като кеш върху други бази данни за подобряване на производителността на приложението. 🤓
Много хора обаче не знаят, че Redis е пълноценна първична база данни който може да се използва за съхраняване и запазване на множество формати на данни за сложни приложения. 😎
Така че нека видим случаите на употреба за това.
Защо мултимоделна база данни?
Нека разгледаме обща настройка за приложение за микросервизи.
Да кажем, че имаме сложно приложение за социални медии с милиони потребители. За това може да се наложи да съхраняваме различни формати на данни в различни бази данни:
- Релационна база данни , като Mysql, за да съхраняваме нашите данни
- ElasticSearch за бързо търсене и филтриране
- База данни с графики за представяне на връзките на потребителите
- База данни с документи , като MongoDB за съхраняване на медийно съдържание, споделяно от нашите потребители ежедневно
- Услуга за кеширане за по-добра производителност на приложението
Очевидно е, че това е доста сложна настройка.
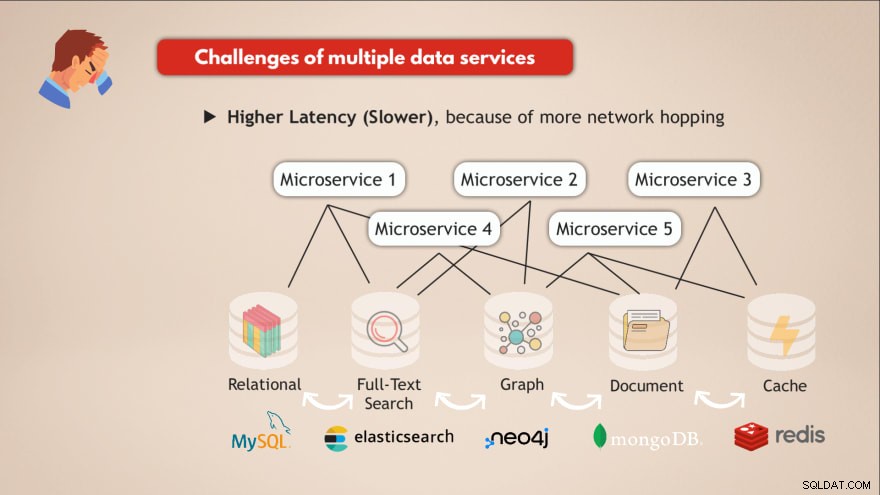
Предизвикателства от наличието на множество услуги за данни
- ❌ Всяка услуга за данни трябва да бъде разгърната и поддържана
- ❌ Ноу-хау е необходимо за всяка услуга за данни
- ❌ Различни изисквания за мащабиране и инфраструктура
- ❌ По-сложен код на приложението за взаимодействие с всички тези различни БД
- ❌ По-висока латентност (по-бавна), поради повече прескачане на мрежата
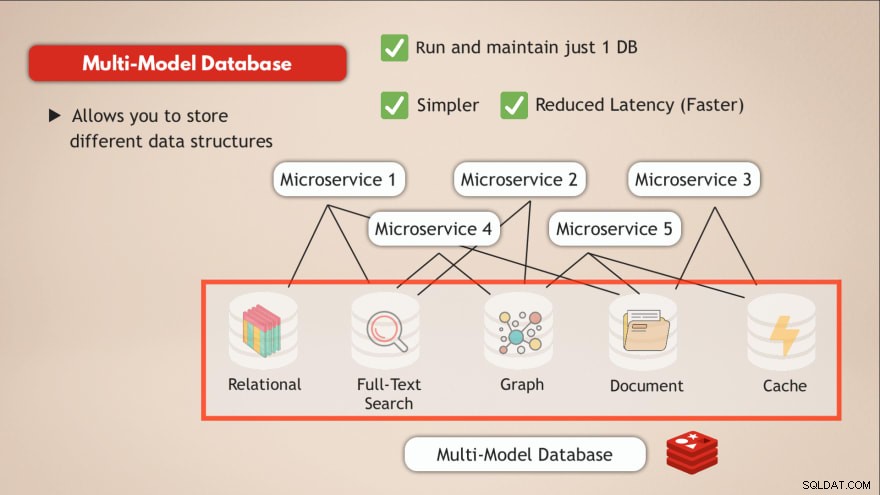
Наличие на база данни с множество модели
В сравнение с многомоделна база данни вие решавате повечето от тези предизвикателства. Преди всичко виеизпълнявате и поддържате само 1 услуга за данни . Така че вашето приложение също трябва да говори с едно хранилище за данни и това изисква само един програмен интерфейс за тази услуга за данни.
В допълнение, забавянето ще бъде намалено чрез преминаване към една крайна точка за данни и елиминиране на няколко вътрешни мрежови хъба.
Така че наличието на една база данни, като Redis, ви позволява да съхранявате различни типове данни или по принцип ви позволява да имате няколко типа бази данни в една, както и да действате като кеш, решава такива предизвикателства.
- ✅ Стартирайте и поддържайте само 1 база данни
- ✅ По-просто
- ✅ Намалена латентност (по-бързо)
Как работи Redis?
Модули Redis 📦
Начинът, по който работи е, че имате Redis Core, което е хранилище за ключови стойности който вече поддържа съхранение на множество типове данни и след това можете да разширите това ядро с така наречените модули за различни типове данни , от които вашето приложение се нуждае за различни цели. Така например RediSearch за функционалност за търсене като ElasticSearch или Redis Graph за съхранение на графични данни и така нататък:

И страхотно нещо в това е, че е модулен . Така че тези различни типове функционалности на база данни не са тясно интегрирани в една база данни, а по-скоро можете да изберете точно коя функционалност на услугата за данни ви е необходима за вашето приложение и след това основно да добавите този модул.
Кеш в готово състояние ⚡️
Разбира се, когато използвате Redis като основна база данни, не се нуждаете от допълнителен кеш, тъй като имате това автоматично от кутията с Redis. Това отново означава по-малко сложност във вашето приложение, защото не е необходимо да прилагате логиката за управление на попълването и обезсилването на кеша.
Redis е бърз 🚀
Като база данни в паметта (данните се съхраняват в RAM), Redis е супер бърз и производителен, което разбира се прави самото приложение по-бързо.
Но в този момент може да се чудите:
Как може една база данни в паметта да запази данните? 🤔
Как Redis може да запази данните и да се възстанови от загуба на данни? 🧐
Ако процесът Redis или сървърът, на който работи Redis, се провали, всички данни в паметта са изчезнали, нали? И така, как се запазват данните и по принцип как мога да съм сигурен, че данните ми са безопасни? 👀
Репликация на Redis?
Е,най-простият начин за архивиране на данни е чрез копиране на Redis . Така че, ако главният екземпляр на Redis изпадне, репликите все още ще работят и ще имат всички данни. Така че, ако имате репликиран Redis, репликите ще имат данните.
Но, разбира се, ако всички екземпляри на Redis се свалят, ще загубите данните, защото няма да остане реплика. 🤯 Така че нуждаем се от истинска постоянство .
Моментно заснемане и AOF
Redis има множество механизми за запазване на данните и запазване на данните в безопасност.
Моментни снимки
Първият:моментните снимки, които можете да конфигурирате въз основа на време, брой заявки и т.н. Така че моментните снимки на вашите данни ще се съхраняват на диск , който можете да използвате за възстановяване на вашите данни, ако цялата база данни Redis е изчезнала.
Но имайте предвид, че ще загубите последните минути данни , защото обикновено правите моментни снимки на всеки пет минути или час в зависимост от вашите нужди. 😐
AOF
Така че като алтернатива Redis използва нещо, наречено AOF , което означава A добавете O само F ile.
В този случай всяка промяна се записва на диска за непрекъснато запазване . И при рестартиране на Redis или след прекъсване, Redis ще възпроизведе регистрационните файлове само за добавяне на файл, за да възстанови състоянието.
Така чеAOF е по-издръжлив , но може да бъде по-бавно от моментното снимане.
Най-добрата опция 💡 :Използвайте комбинация както от AOF, така и от моментни снимки, при които AOF запазва данните от паметта на диска непрекъснато, плюс имате редовни моментни снимки между тях, за да запазите състоянието на данните, в случай че трябва да ги възстановите:

Как да мащабирам база данни Redis?
Да кажем, че моят 1 екземпляр на Redis свърши без памет, така че данните стават твърде големи, за да се задържат в паметта, или Redis се превръща в тесно място и не може да обработва повече заявки. В такъв случай как да увелича капацитета и размера на паметтата за моята база данни Redis? 🤔
Имаме няколко опции за това:
1. Групиране
На първо място, Redis поддържа клъстериране . Това означава, че можете да имате основен или главен екземпляр на Redis, който може да се използва за четене и запис на данни и можете да имате множество реплики на този първичен екземпляр за четене на данните :
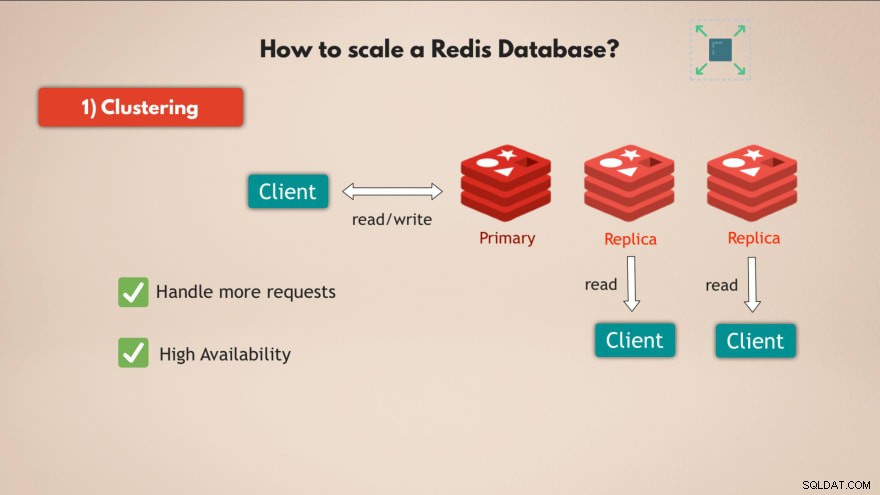
По този начин можете да мащабирате Redis, за да обработвате повече заявки и в допълнение увеличите високата наличност на вашата база данни, тъй като ако главният не успее, 1 от репликите може да поеме управлението и вашата база данни Redis може да продължи да функционира без никакви проблеми.
2. Разделяне
Е, това изглежда достатъчно добре, но какво ще стане, ако
- Вашият набор от данни става твърде голям, за да се побере в памет на един сървър .
- Освен това, ние сме мащабирали показанията в базата данни, така че всички заявки, които по същество просто правят заявки за данните. Но нашият главен екземпляр все още е сам и все още трябва да обработва всички записвания .
И така, какво е решението тук? 🤔
За това използваме концепцията за разчленяване , което е общо понятие в базите данни и което Redis също поддържа.
И така, разделяне по същество означава, че вземате пълния си набор от данни и го разделяте на по-малки парчета или подмножества от данни , където всеки шард отговаря за своя собствена подгрупа от данни.
Това означава, че вместо да имате един главен екземпляр, който обработва всички записи в пълния набор от данни, можете да го разделите на да речем 4 сегмента, всеки от които отговаря за четене и запис в подмножество от данни . 💡
Освен това всеки фрагмент се нуждае от по-малко капацитет на паметта , защото имат само една четвърт от данните. Това означава, че можете да разпространявате и стартирате фрагменти на по-малки възли и основно да мащабирате хоризонтално своя клъстер:
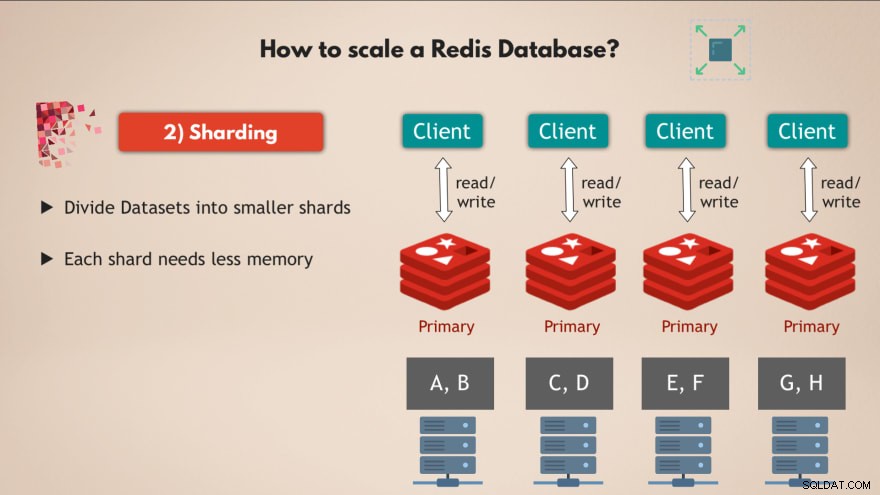
Така че има множество възли , които изпълняватмножество реплики на Redis, които са всички раздробени ви дава много ефективна високодостъпна база данни Redis, която може да обработва много повече заявки, без да създава пречки 👍
Още теми...
Вижте моето видео по-долу за последните 2 теми и сценарии:
- Приложения, които се нуждаят от още по-висока наличност и производителност на различни географски местоположения
- Новият стандарт за стартиране на микроуслуги е платформата Kubernetes, така че изпълнението на Redis в Kubernetes е много интересен и често срещан случай на употреба
Цялото видео е достъпно тук:🤓
Надявам се това да е било полезно и интересно за някои от вас! 😊
Харесайте, споделете и ме последвайте 😍 за повече съдържание:
- Instagram – Публикуване на много неща зад кадър
- Частна FB група



