Тъй като използвате пролетта. Можете да използвате MultipartFile за да получите файла във вашия контролер и след това използвайте Binary на org.bson за съхраняване на файл в MongoDB, ако размерът на изображението ви е <16 MB (ако размерът на изображението е> 16 MB, можете да използвате GridFs
).
Трябва да добавите само една зависимост към вашия проект - spring-data-mongoDB
Нека вземем пример за потребителска колекция, която изглежда така:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Тук можете да видите Binary image който представлява вашия файл с изображение.
Сега създайте хранилище за тази потребителска колекция, като използвате MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Създайте контролер за демонстрационни цели. Използвайте @RequestParam MultipartFile file за да получите файл във вашия контролер, вземете байтове от файла и го задайте на потребителски обект user.setImage(new Binary(file.getBytes())); пълният пример е по-долу:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Стартирайте сървъра и натиснете крайната точка, както е показано на екранната снимка на пощальона по-долу
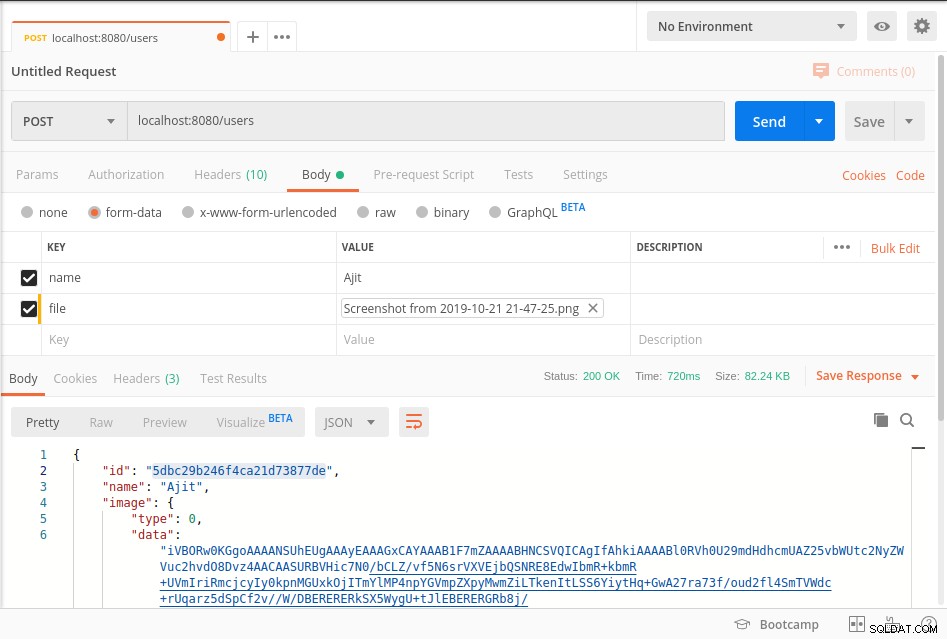
Вашите данни се съхраняват в mongoDb в BinData формат и за да получите данните от базата данни, моля, вижте getImage метод от горния код.
РЕДАКТИРАНЕ:
Задаващият въпроса използва tess4j библиотека за извличане на текст от изображение и doOCR е метод в тази библиотека. Следвах тези стъпки, за да извлека текст от изображение в моето пролетно приложение за зареждане.
-
Инсталирайте
tesseract-ocrвъв вашата система:sudo apt-get install tesseract-ocr -
Изтеглете
eng.traineddataданни за обучение от https://github.com/tesseract-ocr/tessdata и го преместете в основната папка на проекта. -
Добавете зависимостта по-долу към вашия проект:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Добавете кода по-долу към съществуващ проект:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}



