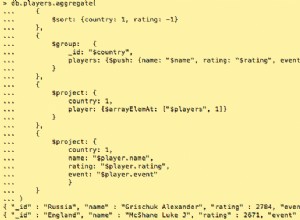
Втората версия добавя изпълнение на тръбопровод за агрегиране за всеки документ в обединената колекция .
Документацията казва:
Конвейерът се изпълнява за всеки документ в колекцията, а не за всеки съответстващ документ.
В зависимост от това колко голяма е колекцията (както броя документи, така и размера на документа) това може да излезе за приличен период от време.
Има смисъл - всички допълнителни документи, дължащи се на премахването на ограничението, също трябва да имат изпълнена линия за агрегиране за тях.
Възможно е изпълнението на конвейер за агрегиране за всеки документ да не е толкова оптимизирано, колкото би могло да бъде. Например, ако конвейерът е настроен и съборен за всеки документ, лесно може да има повече режийни разходи в това отколкото в условията на $match.
Изпълнението на конвейер за агрегиране за съединен документ осигурява допълнителна гъвкавост. Ако имате нужда от тази гъвкавост, може да има смисъл да изпълните тръбопровода, въпреки че независимо от това трябва да се вземе предвид производителността. Ако не го направите, разумно е да използвате по-ефективен подход.