TL;DR:mongoengine прекарва векове в преобразуване на всички върнати масиви в dicts
За да тествам това, създадох колекция с документ с DictField с голям вложен dict . Документът е приблизително във вашия диапазон от 5-10 MB.
След това можем да използваме timeit.timeit
за потвърждаване на разликата в четенията с помощта на pymongo и mongoengine.
След това можем да използваме pycallgraph и GraphViz за да видите какво отнема на mongoengine толкова дълго време.
Ето пълния код:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
И резултатът доказва, че mongoengine е много бавен в сравнение с pymongo:
pymongo took 0.87s
mongoengine took 25.81118331072267
Получената графика на повикванията илюстрира доста ясно къде е тясното място:
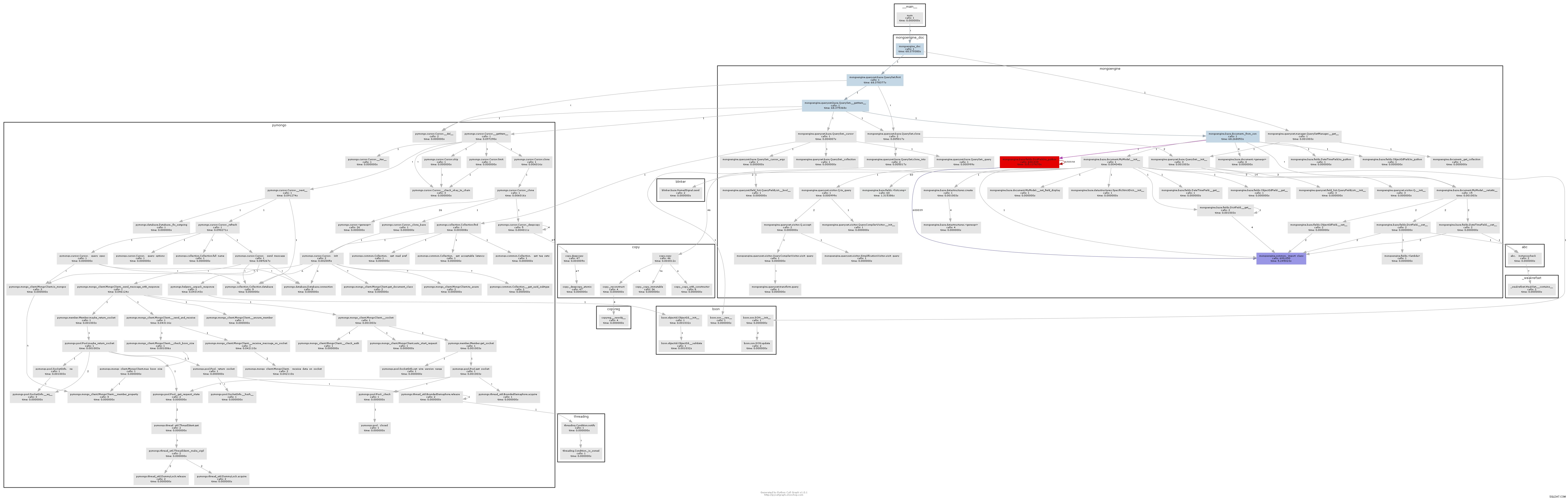
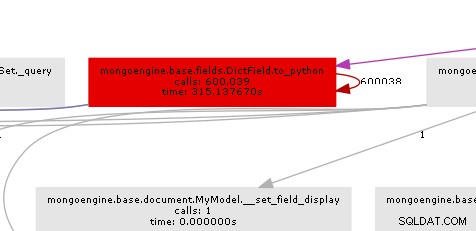
По същество mongoengine ще извика метода to_python на всяко DictField че се връща от db. to_python е доста бавен и в нашия пример се извиква безумен брой пъти.
Mongoengine се използва за елегантно картографиране на структурата на вашия документ към обекти на Python. Ако имате много големи неструктурирани документи (за които mongodb е страхотен), тогава mongoengine всъщност не е правилният инструмент и трябва просто да използвате pymongo.
Въпреки това, ако знаете структурата, можете да използвате EmbeddedDocument полета, за да получите малко по-добра производителност от mongoengine. Проведох подобен, но не еквивалентен тест код в тази същност
и изходът е:
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
Така че можете да направите mongoengine по-бърз, но pymongo все още е много по-бърз.
АКТУАЛИЗАЦИЯ
Добър пряк път към интерфейса на pymongo тук е да използвате рамката за агрегиране:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]



