ClusterControl 1.6 идва с по-тясна интеграция с AWS, Azure и Google Cloud, така че вече е възможно да стартирате нови екземпляри и да разгръщате MySQL, MariaDB, MongoDB и PostgreSQL директно от потребителския интерфейс на ClusterControl. В този блог ще ви покажем как да разположите клъстер в Amazon Web Services.
Имайте предвид, че тази нова функция изисква два модула, наречени clustercontrol-cloud и clustercontrol-clud . Първият е помощен демон, който разширява възможностите на CMON за комуникация в облак, докато вторият е клиент на файлов мениджър за качване и изтегляне на файлове в облачни екземпляри. И двата пакета са зависимости от пакета потребителски интерфейс на clustercontrol, който ще бъде инсталиран автоматично, ако не съществуват. Вижте страницата с документация на компонентите за подробности.
Облачни идентификационни данни
ClusterControl ви позволява да съхранявате и управлявате вашите облачни идентификационни данни под Интеграции (странично меню) -> Доставчици на облак:
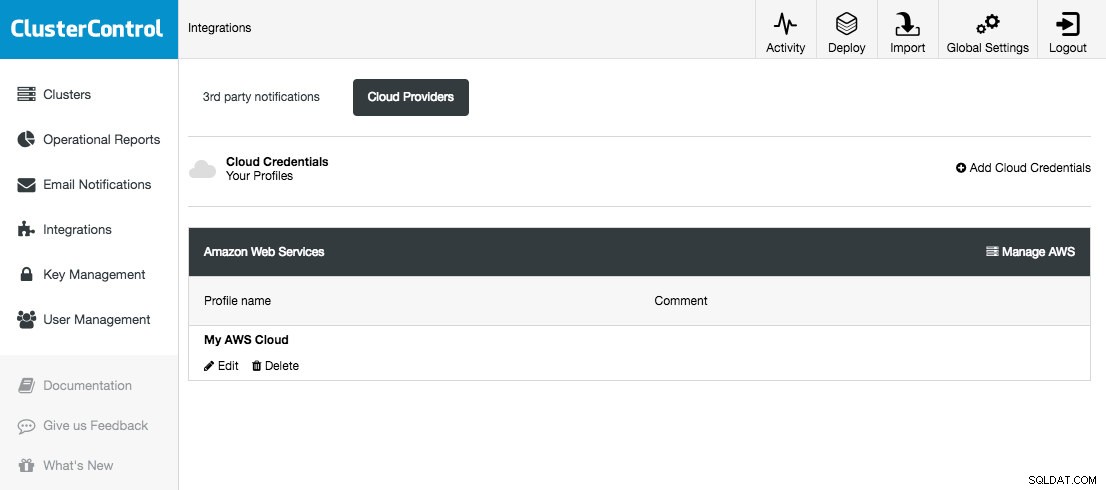
Поддържаните облачни платформи в тази версия са Amazon Web Services, Google Cloud Platform и Microsoft Azure. На тази страница можете да добавяте нови облачни идентификационни данни, да управлявате съществуващи и също така да се свързвате с вашата облачна платформа, за да управлявате ресурси.
Идентификационните данни, които са зададени тук, могат да се използват за:
- Управление на облачни ресурси
- Разгръщане на бази данни в облака
- Качете резервно копие в хранилище в облак
Следното ще видите, ако щракнете върху бутона „Управление на AWS“:
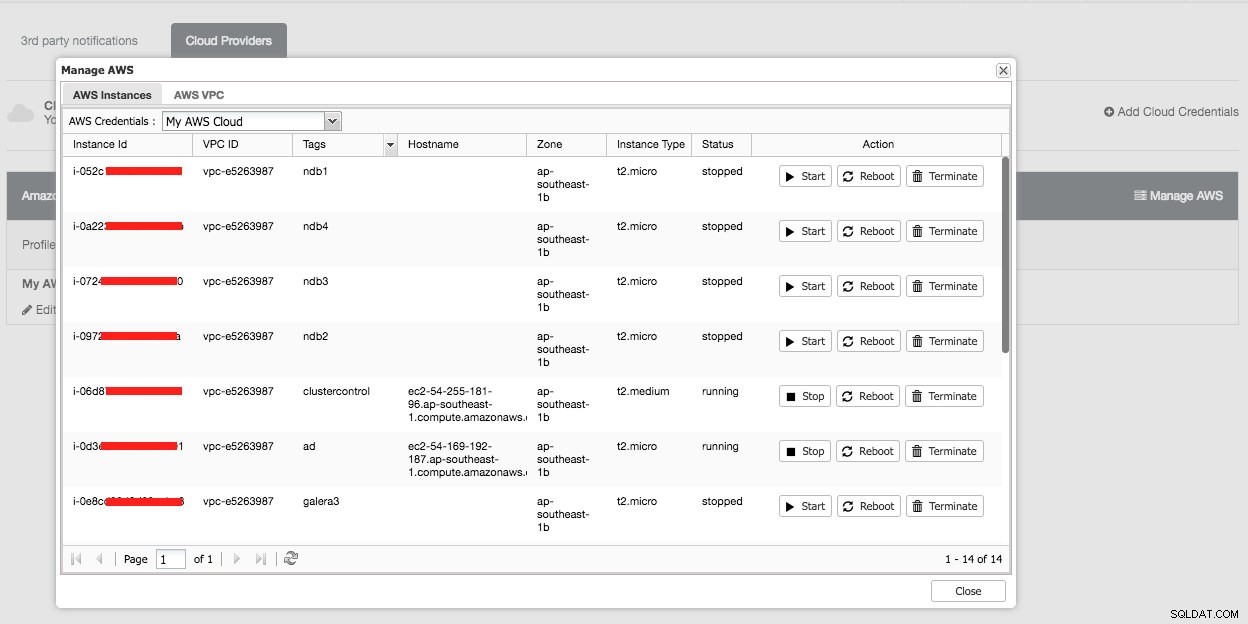
Можете да изпълнявате прости задачи за управление на вашите облачни екземпляри. Можете също да проверите настройките на VPC в раздела „AWS VPC“, както е показано на следната екранна снимка:
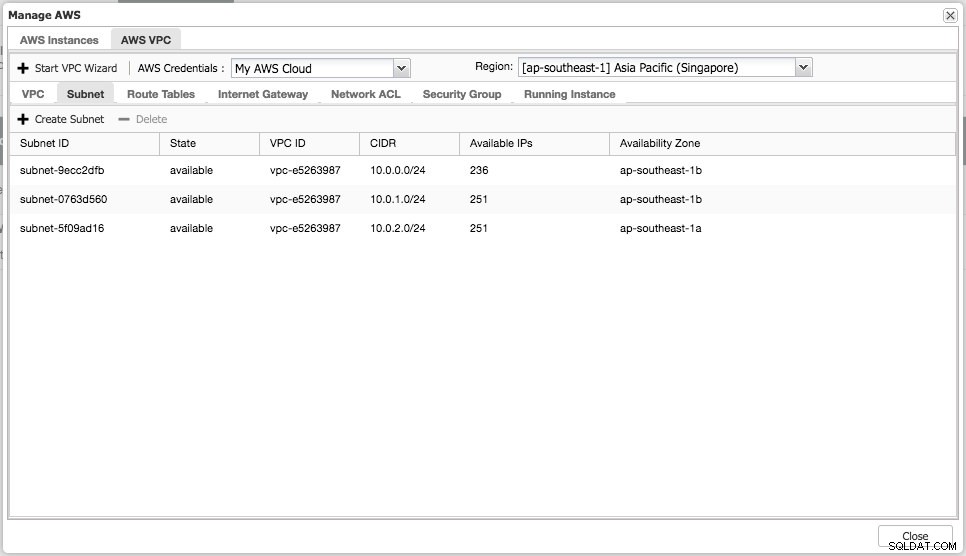
Горните функции са полезни като справка, особено когато подготвяте вашите облачни екземпляри, преди да започнете внедряването на базата данни.
Разгръщане на база данни в облак
В предишни версии на ClusterControl разполагането на база данни в облака ще се третира подобно на внедряването на стандартни хостове, където трябваше да създадете облачните екземпляри предварително и след това да предоставите подробностите и идентификационните данни за екземпляра в съветника „Разгръщане на клъстер на база данни“. Процедурата по внедряване не е знаела за допълнителна функционалност и гъвкавост в облачната среда, като динамично разпределение на IP и име на хост, публичен IP адрес с NAT, еластичност на съхранение, конфигурация на виртуална частна облачна мрежа и т.н.
С версия 1.6 просто трябва да предоставите идентификационните данни в облака, които могат да се управляват чрез интерфейса „Доставчици на облака“ и да следвате съветника за внедряване „Внедряване в облака“. От потребителския интерфейс на ClusterControl щракнете върху Разгръщане и ще ви бъдат представени следните опции:
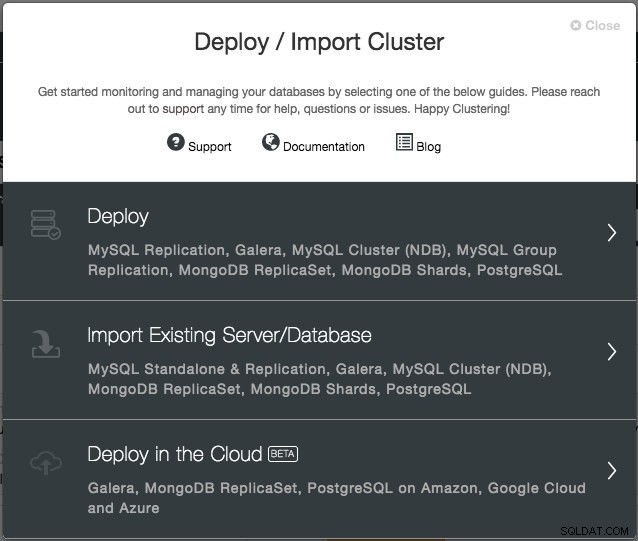
В момента поддържаните облачни доставчици са тримата големи играчи - Amazon Web Service (AWS), Google Cloud и Microsoft Azure. Ще интегрираме повече доставчици в бъдещата версия.
На първата страница ще ви бъдат представени опциите за подробности за клъстера:
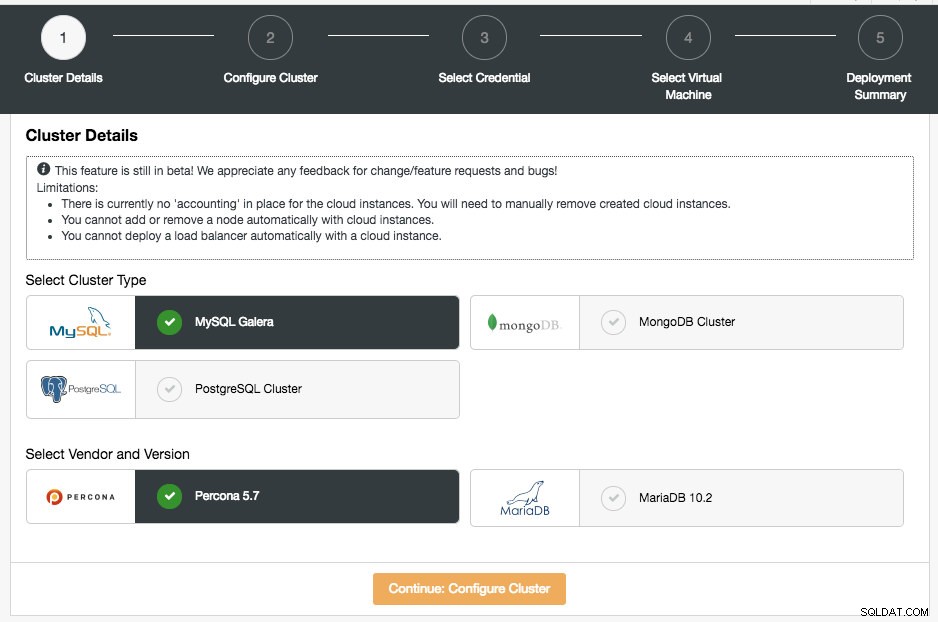
В този раздел ще трябва да изберете поддържания тип клъстер, MySQL Galera Cluster, MongoDB Replica Set или PostgreSQL Streaming Replication. Следващата стъпка е да изберете поддържания доставчик за избрания тип клъстер. В момента се поддържат следните доставчици и версии:
- MySQL Galera Cluster - Percona XtraDB Cluster 5.7, MariaDB 10.2
- MongoDB Cluster – MongoDB 3.4 от MongoDB, Inc и Percona Server за MongoDB 3.4 от Percona (само набор от реплики).
- PostgreSQL Cluster – PostgreSQL 10.0 (само поточно репликация).
В следващата стъпка ще ви бъде представен следния диалогов прозорец:
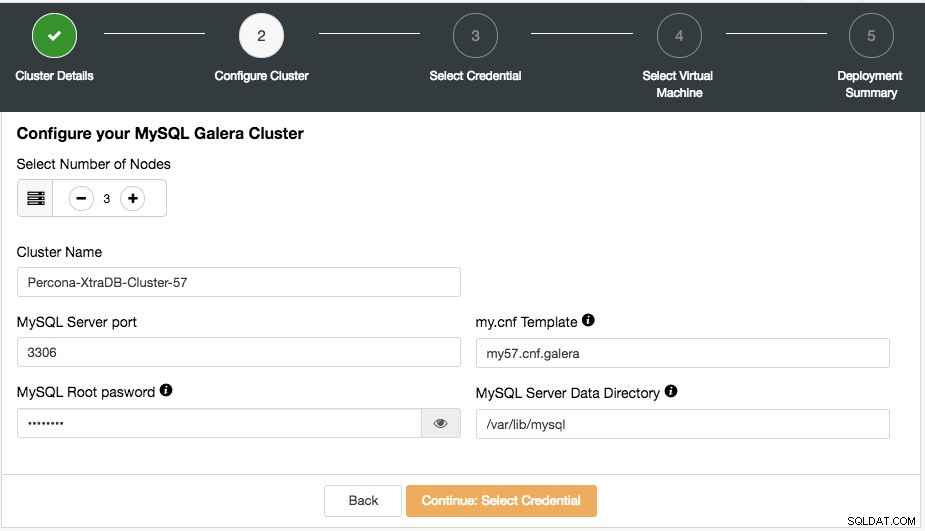
Тук можете да конфигурирате съответно избрания тип клъстер. Изберете броя на възлите. Името на клъстера ще се използва като маркер на екземпляра, така че можете лесно да разпознаете това внедряване в таблото за управление на вашия доставчик на облак. Не се допуска интервал в името на клъстера. My.cnf Template е конфигурационният файл на шаблона, който ClusterControl ще използва за разгръщане на клъстера. Той трябва да се намира под /usr/share/cmon/templates на хоста на ClusterControl. Останалите полета са доста разбираеми.
Следващият диалогов прозорец е да изберете облачните идентификационни данни:
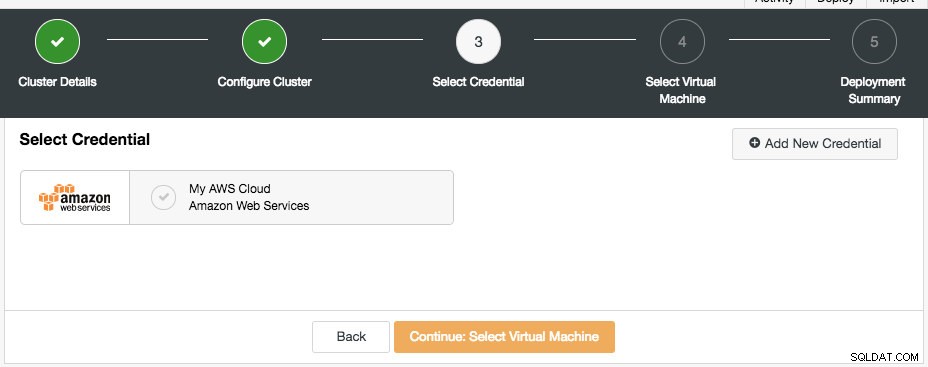
Можете да изберете съществуващите идентификационни данни в облак или да създадете нов, като щракнете върху бутона „Добавяне на нов идентификационен номер“. Следващата стъпка е да изберете конфигурацията на виртуалната машина:
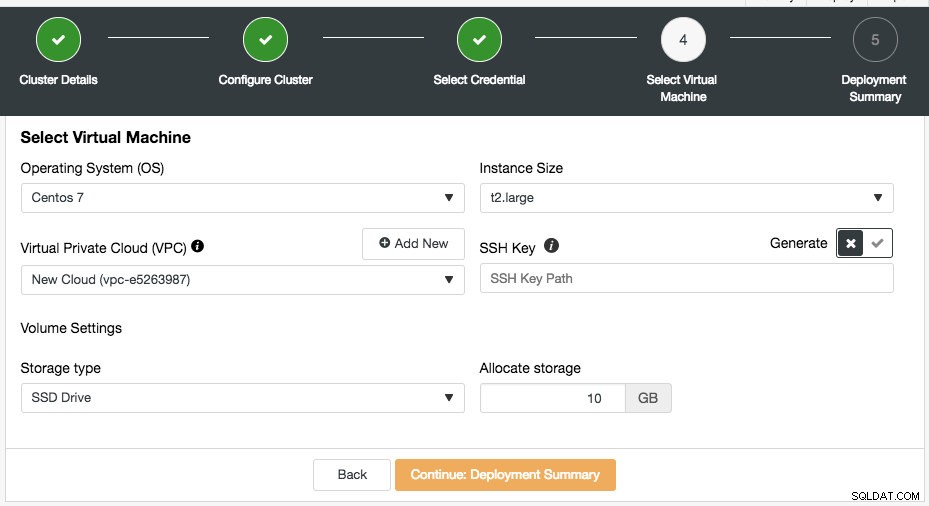
Повечето от настройките в тази стъпка се попълват динамично от облачния доставчик от избраните идентификационни данни. Можете да конфигурирате операционната система, размера на екземпляра, настройката на VPC, типа и размера на съхранение, както и да посочите местоположението на SSH ключа на хоста на ClusterControl. Можете също да оставите ClusterControl да генерира нов ключ специално за тези случаи. Когато щракнете върху бутона „Добавяне на нов“ до Virtual Private Cloud, ще ви бъде представен формуляр за създаване на нов VPC:
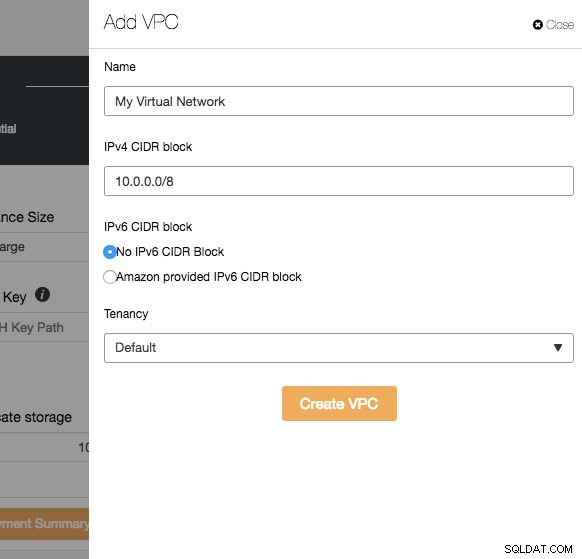
VPC е логическа мрежова инфраструктура, която имате във вашата облачна платформа. Можете да конфигурирате вашия VPC, като промените неговия диапазон от IP адреси, създадете подмрежи, конфигурирате таблици с маршрути, мрежови шлюзове и настройки за сигурност. Препоръчително е да разположите инфраструктурата на вашата база данни в тази мрежа за изолация, сигурност и контрол на маршрутизирането.
Когато създавате нов VPC, посочете името на VPC и IPv4 адресния блок с подмрежа. След това изберете дали IPv6 трябва да бъде част от мрежата и опцията за наемане. След това можете да използвате тази виртуална мрежа за вашата инфраструктура на база данни.
Последната стъпка е резюмето на внедряването:
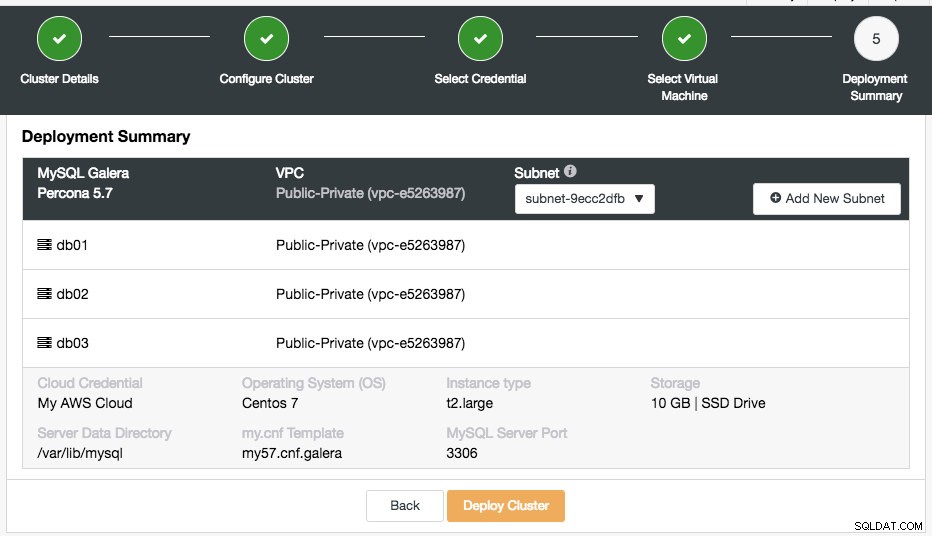
На този етап трябва да изберете коя подмрежа в избраната виртуална мрежа искате да работи базата данни. Обърнете внимание, че избраната подмрежа ТРЯБВА да има активиран автоматично присвояване на публичен IPv4 адрес. Можете също да създадете нова подмрежа под този VPC, като щракнете върху бутона „Добавяне на нова подмрежа“. Проверете дали всичко е правилно и натиснете бутона „Разгръщане на клъстер“, за да започнете внедряването.
След това можете да наблюдавате напредъка, като щракнете върху Активност -> Работни места -> Създаване на клъстер -> Пълни подробности за работата:
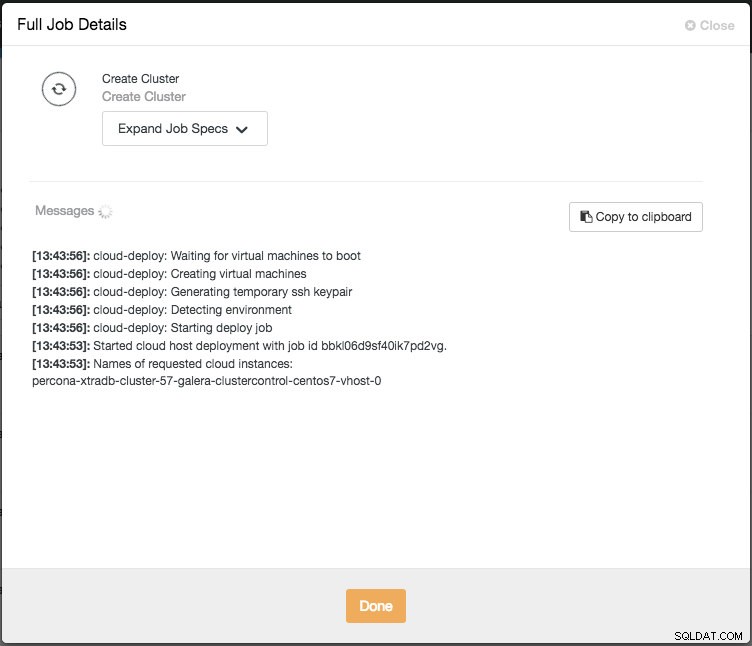
В зависимост от връзките, това може да отнеме от 10 до 20 минути. След като приключите, ще видите нов клъстер на база данни, посочен под таблото за управление на ClusterControl. За клъстер за поточно репликация на PostgreSQL може да се наложи да знаете главния и подчинения IP адрес, след като разполагането завърши. Просто отидете на раздела Nodes и ще видите публичните и частните IP адреси в списъка с възли вляво:
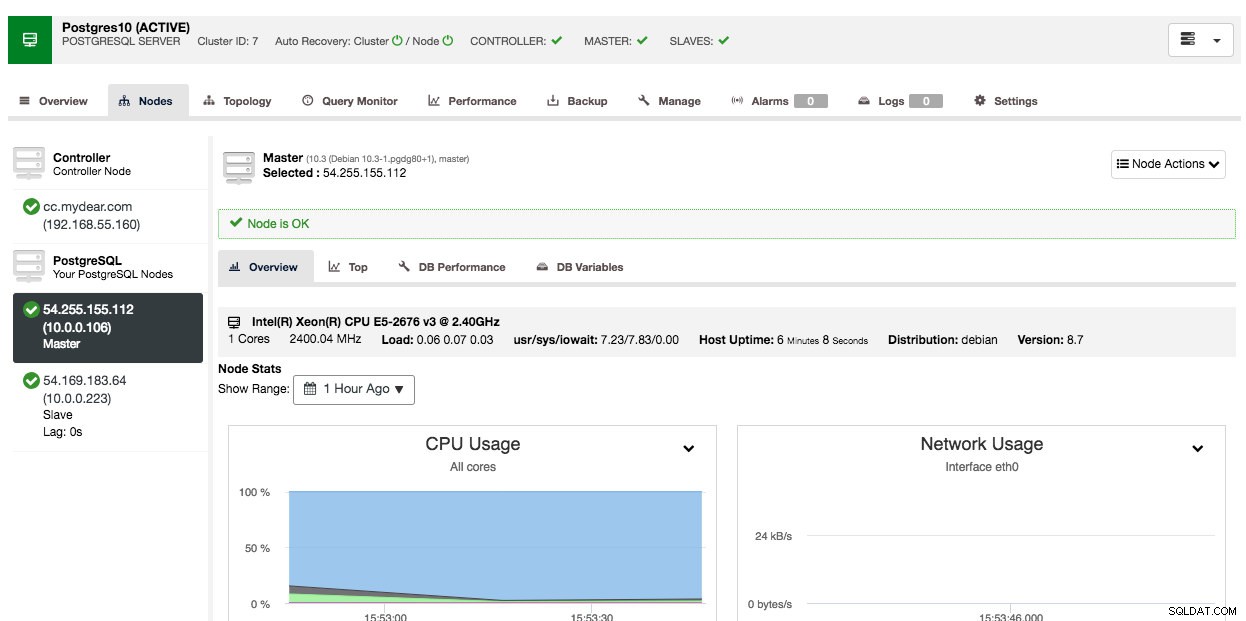
Вашият клъстер от база данни вече е разгърнат и работи на AWS.
В момента мащабирането работи подобно на стандартния хост, където трябва ръчно да създадете облачен екземпляр предварително и да посочите хоста под ClusterControl -> изберете клъстера -> Добавяне на възел.
Под капака процесът на внедряване прави следното:
- Създаване на облачни екземпляри
- Конфигуриране на групи за защита и работа в мрежа
- Проверете SSH свързаността от ClusterControl към всички създадени екземпляри
- Разгръщане на база данни на всеки екземпляр
- Конфигуриране на връзките за клъстериране или репликация
- Регистрирайте внедряването в ClusterControl
Имайте предвид, че тази функция все още е в бета версия. Въпреки това можете да използвате тази функция, за да ускорите вашата среда за разработка и тестване, като контролирате и управлявате клъстера на базата данни в различни доставчици на облак от един потребителски интерфейс.
Архивиране на база данни в облак
Тази функция съществува от ClusterControl 1.5.0 и сега добавихме поддръжка за Azure Cloud Storage. Това означава, че вече можете да качвате и изтегляте създаденото резервно копие и на трите основни доставчици на облак (AWS, GCP и Azure). Процесът на качване се случва веднага след успешното създаване на архива (ако превключите „Качване на архивно копие в облака“) или можете ръчно да щракнете върху бутона с иконата на облак в списъка с архивиране:
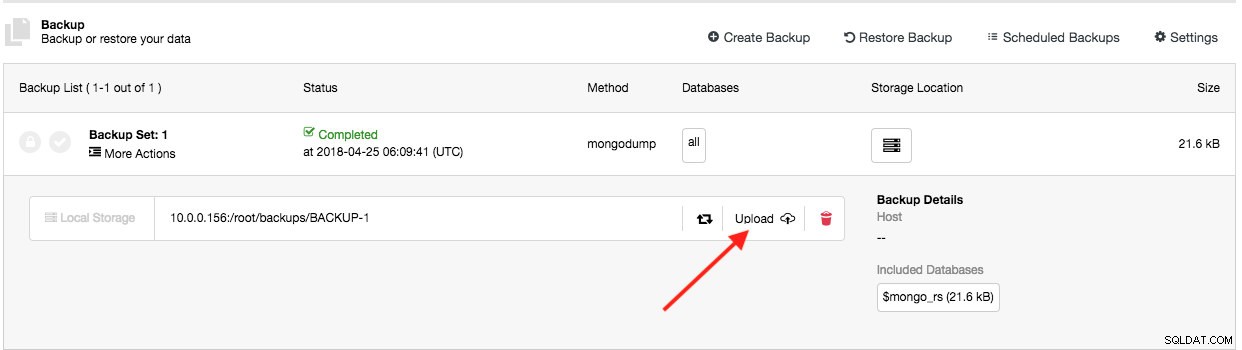
След това можете да изтеглите и възстановите резервни копия от облака, в случай че сте загубили локалното си хранилище за архивиране или ако трябва да намалите използването на локално дисково пространство за вашите резервни копия.
Текущи ограничения
Има някои известни ограничения за функцията за внедряване в облак, както е посочено по-долу:
- Понастоящем няма „отчитане“ за екземпляри в облака. Ще трябва да премахнете ръчно екземплярите в облака, ако премахнете клъстер от база данни.
- Не можете да добавяте или премахвате възел автоматично с облачни екземпляри.
- Не можете да разгръщате автоматично балансиране на натоварването с облачен екземпляр.
Тествахме подробно функцията в много среди и настройки, но винаги има ъглови случаи, които може да сме пропуснали. За повече информация, моля, разгледайте регистъра на промените.
Приятно групиране в облака!



