MongoDB зони
За да разберем зоните на MongoDB, първо трябва да разберем какво е зона:група от фрагменти, базирани на конкретен набор от тагове.
MongoDB Zones помагат при разпределението на парчета, базирани на тагове, между фрагменти. Цялата работа (четене и запис), свързана с документи в дадена зона, се извършва върху части, съответстващи на тази зона.
Може да има различни сценарии, при които разчленените клъстери (базирани на зони) могат да се окажат много полезни. Да кажем:
- Приложение, което е географски разпределено, може да изисква интерфейса, както и хранилището на данни
- Приложение има n-степенна архитектура, така че някои записи се извличат от хардуер с по-високо ниво (ниска латентност), докато други могат да бъдат извлечени от хардуер с ниско ниво (предизвикащ висока латентност)
Предимства от използването на MongoDB зони
С помощта на MongoDB Zones, администраторите на база данни могат да създават решения за съхранение на нива, които поддържат жизнения цикъл на данните, с често използвани данни, съхранявани в паметта, по-малко използвани данни, съхранявани на сървъра, и в подходящото време архивирани данни, взети офлайн.
Как да настроите зони
В разделени клъстери можете да създавате зони, които представляват група от фрагменти и да асоциирате един или повече диапазони от стойности на ключове за сегменти към тази зона. MongoDB насочва всички четения и всички записи, които влизат в обхвата на зоната, само към онези части вътре в зоната. Можете да асоциирате всяка зона с един или повече фрагменти в клъстера и един фрагмент може да се свърже с произволен брой зони.
Някои от най-често срещаните модели на разгръщане, при които могат да се прилагат зони, са както следва:
- Изолирайте конкретен подмножество от данни върху конкретен набор от фрагменти.
- Като се гарантира, че най-подходящите данни се намират в фрагменти, които са географски най-близо до сървърите на приложения.
- Насочвайте данните към фрагментите въз основа на производителността на хардуера на фрагмента.
Следното изображение илюстрира разделен клъстер с три парчета и две зони. Зоната А представлява диапазон с долна граница 0 и горна граница 10. Зоната В показва диапазон с долна граница от 10 и горна граница от 20. ЧЕРВЕНИ и СИНИ парчета имат зона А. Shard BLUE също има B зона. Shard GREEN няма зони, свързани с него. Клъстерът е в стабилно състояние и никакви парчета не нарушават нито една от зоните
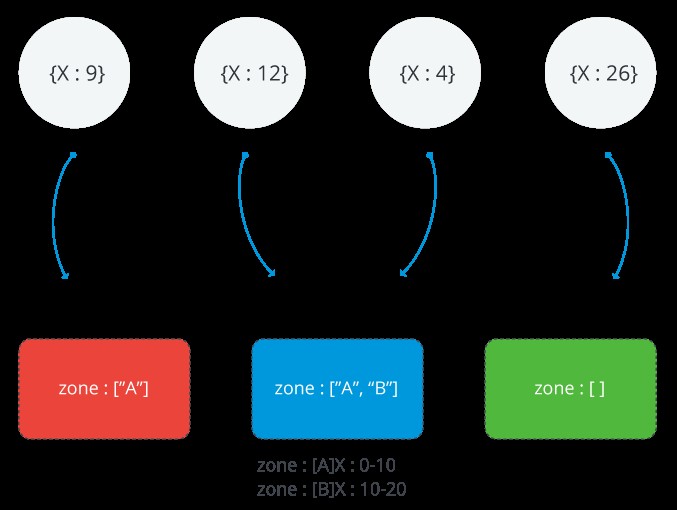
Обхват на зона MongoDB
Всяка зона покрива един или повече диапазони от стойности на ключове за сегменти. Всеки диапазон, който зона покрива, винаги включва долната й граница и изключва горната граница.
ПОМНЕТЕ: Зоните не могат да споделят диапазони и не могат да имат припокриващи се диапазони.
Добавяне на парчета към зона
Методът sh.addShardTag() се използва за добавяне на зони към шард. Един фрагмент може да има множество зони, а множество фрагменти също могат да имат една и съща зона. Следващият пример добавя зона А към един фрагмент.
sh.addShardTag("shard0000", "A")Премахване на парчета в зона
За да премахнете зона от фрагмент, се използва методът sh.removeShardTag(). Следният пример премахва зона А от фрагмент.
sh.removeShardTag("shard0002", "A")Съвети за MongoDB зони
Опростете документите
MongoDB е база данни без схеми. Това означава, че няма предварително дефинирана схема по подразбиране. Можем да добавим предварително дефинирана схема в по-нови версии, но това не е задължително. Не подценявайте трудностите, които възникват при работа с документи и масиви, тъй като може да стане наистина трудно да анализирате данните си в процеса от страна на приложението/ETL. Освен това масивите могат да навредят на производителността на репликацията:за всяка промяна в масива всички стойности на масива се репликират.
Най-добрият хардуер не винаги е най-добрата опция
Използването на добър хардуер определено помага за добра производителност. Но какво би могло да се случи в среда, когато един екземпляр от голяма машина умре? Отговорът е „отказ при отказ“.
Наличието на множество малки машини (вместо една или две) в разпределена среда може да гарантира, че прекъсванията ще засегнат само няколко части от фрагмента с малко или никакво възприемане от приложението. Но в същото време повече машини предполага голяма вероятност за повреда. Помислете за този компромис, когато проектирате вашата среда. Правилният избор влияе върху производителността.
Работен комплект
Колко голям е работният комплект? Обикновено приложението не използва всички данни. Някои данни се актуализират често, докато други не. Вашият работен набор от данни пасва ли на RAM? Оптимална производителност се получава, когато целият набор от работни данни е в RAM.



