Повишаването на производителността на системата, особено за компютърните структури, изисква процес за получаване на добър преглед на производителността. Този процес обикновено се нарича наблюдение. Мониторингът е съществена част от управлението на базата данни и подробната информация за производителността на вашия MongoDB не само ще ви помогне да прецените функционалното му състояние; но също така дават представа за аномалии, което е полезно при извършване на поддръжка. Важно е да идентифицирате необичайни поведения и да ги коригирате, преди да ескалират в по-сериозни повреди.
Някои от видовете неизправности, които могат да възникнат, са...
- Забавяне или забавяне
- Недостатъчност на ресурсите
- Хълцане на системата
Мониторингът често е съсредоточен върху анализиране на показатели. Някои от ключовите показатели, които ще искате да наблюдавате, включват...
- Ефективност на базата данни
- Използване на ресурси (използване на процесора, налична памет и използване на мрежата)
- Появили се неуспехи
- Насищане и ограничаване на ресурсите
- Операции с пропускателна способност
В този блог ще обсъдим подробно тези показатели и ще разгледаме наличните инструменти от MongoDB (като помощни програми и команди.) Ще разгледаме и други софтуерни инструменти като Pandora, FMS с отворен код и Robo 3T. За по-голяма простота ще използваме софтуера Robo 3T в тази статия, за да демонстрираме показателите.
Ефективност на базата данни
Първото и основно нещо, което трябва да проверите в база данни, е нейната обща производителност, например дали сървърът е активен или не. Ако изпълните тази команда db.serverStatus() в база данни в Robo 3T, ще ви бъде представена тази информация, показваща състоянието на вашия сървър.
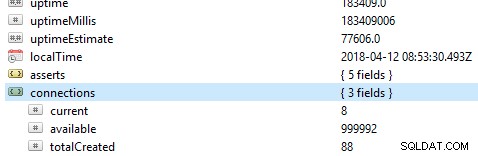

Набори реплики
Наборът реплики е група от процеси mongod, които поддържат един и същ набор от данни. Ако използвате набори от реплики, особено в производствен режим, операционните журнали ще осигурят основа за процеса на репликация. Всички операции по запис се проследяват с помощта на възли, тоест първичен възел и вторичен възел, които съхраняват колекция с ограничен размер. На първичния възел операциите за запис се прилагат и обработват. Ако обаче основният възел се провали, преди да бъдат копирани в регистрационните файлове на операциите, тогава се извършва вторичното записване, но в този случай данните може да не бъдат репликирани.
Ключови показатели, които да следите...
Закъснение при репликация
Това определя колко далеч е вторичният възел зад първичния възел. Оптималното състояние изисква разликата да бъде възможно най-малка. При нормална операционна система това изоставане се оценява на 0. Ако разликата е твърде голяма, целостта на данните ще бъде компрометирана, след като вторичният възел бъде повишен в първичен. В този случай можете да зададете праг, например 1 минута, и ако той бъде надвишен, се задава сигнал. Честите причини за голямо забавяне на репликацията включват...
- Шардове, които може да имат недостатъчен капацитет за запис, което често се свързва с насищане на ресурси.
- Вторичният възел предоставя данни с по-бавна скорост от първичния възел.
- Възлите може също да бъдат възпрепятствани по някакъв начин да комуникират, вероятно поради лоша мрежа.
- Операциите на основния възел също могат да бъдат по-бавни, като по този начин блокират репликацията. Ако това се случи, можете да изпълните следните команди:
- db.getProfilingLevel():ако получите стойност 0, тогава вашите db операции са оптимални.
Ако стойността е 1, тогава тя съответства на бавни операции, които впоследствие могат да се дължат на бавни заявки. - db.getProfilingStatus():в този случай проверяваме стойността на slowms, по подразбиране тя е 100ms. Ако стойността е по-голяма от тази, тогава може да имате тежки операции по запис на първичните или неадекватни ресурси на вторичните. За да разрешите това, можете да мащабирате вторичния, така че да има толкова ресурси, колкото и основния.
- db.getProfilingLevel():ако получите стойност 0, тогава вашите db операции са оптимални.
Курсори
Ако направите заявка за четене, например find, ще ви бъде предоставен курсор, който е указател към набора от данни на резултата. Ако изпълните тази команда db.serverStatus() и отидете до обекта metrics, след това курсора, ще видите това...

В този случай свойството cursor.timeOut беше актуализирано постепенно до 9, тъй като имаше 9 връзки, които умряха без затваряне на курсора. Последствието е, че той ще остане отворен на сървъра и следователно ще консумира памет, освен ако не бъде извлечен от настройката по подразбиране на MongoDB. Предупреждение за вас трябва да бъде идентифицирането на неактивни курсори и тяхното използване, за да спестите памет. Можете също да избегнете курсорите без изчакване, тъй като те често задържат ресурси, като по този начин забавят вътрешната производителност на системата. Това може да се постигне чрез задаване на стойността на свойството cursor.open.noTimeout на стойност 0.
Записване в дневник
Като се има предвид WiredTiger Storage Engine, преди да бъдат записани данните, те първо се записват във файловете на диска. Това се нарича дневникиране. Журналирането гарантира наличността и трайността на данните при случай на повреда, от който може да се извърши възстановяване.
За целите на възстановяването често използваме контролни точки (особено за системата за съхранение на WiredTiger), за да се възстановим от последната контролна точка. Въпреки това, ако MongoDB се изключи неочаквано, тогава ние използваме техниката на журналиране, за да възстановим всички данни, които са били обработени или предоставени след последната контролна точка.
Журналирането не трябва да се изключва в първия случай, тъй като са необходими само 60 секунди, за да се създаде нова контролна точка. Следователно, ако възникне грешка, MongoDB може да възпроизведе дневника, за да възстанови данните, загубени в рамките на тези секунди.
Журналирането обикновено стеснява интервала от време от момента, когато данните се прилагат към паметта, до издръжливостта на диска. Обектът storage.journal има свойство, което описва честотата на записване, тоест commitIntervalMs, която често се задава на стойност от 100ms за WiredTiger. Настройването му на по-ниска стойност ще подобри честото записване на записи, като по този начин ще намали случаите на загуба на данни.
Ефективност на заключване
Това може да бъде причинено от множество заявки за четене и запис от много клиенти. Когато това се случи, е необходимо да се поддържа последователност и да се избягват конфликти при писане. За да постигне това, MongoDB използва многодискретно заключване, което позволява операциите по заключване да се извършват на различни нива, като глобално ниво, ниво на база данни или ниво на колекция.
Ако имате лоши модели за проектиране на схеми, тогава ще бъдете уязвими за задържане на брави за дълго време. Това често се случва при извършване на две или повече различни операции за запис в един документ в една и съща колекция, с последица от блокиране взаимно. За механизма за съхранение на WiredTiger можем да използваме билетната система, където заявките за четене или запис идват от нещо като опашка или нишка.
По подразбиране едновременният брой операции за четене и запис се дефинира от параметрите wiredTigerConcurrentWriteTransactions и wiredTigerConcurrentReadTransactions, които са зададени на стойност 128.
Ако мащабирате тази стойност твърде високо, в крайна сметка ще бъдете ограничени от ресурсите на процесора. За да увеличите операциите с пропускателна способност, би било препоръчително да мащабирате хоризонтално, като предоставите повече фрагменти.
Severalnines Станете DBA на MongoDB – Пренасяне на MongoDB в Производството Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате MongoDB Изтеглете безплатноИзползване на ресурси
Това обикновено описва използването на налични ресурси, като капацитет на процесора/скорост на обработка и RAM. Производителността, особено за процесора, може да се промени драстично в съответствие с необичайните натоварвания на трафика. Нещата, които трябва да проверите, включват...
- Брой връзки
- Съхранение
- Кеш
Брой връзки
Ако броят на връзките е по-голям от това, което системата за база данни може да обработи, тогава ще има много опашки. Следователно това ще претовари производителността на базата данни и ще накара вашата настройка да работи бавно. Този номер може да доведе до проблеми с драйвера или дори до усложнения с приложението ви.
Ако наблюдавате определен брой връзки за известен период и след това забележите, че тази стойност е достигнала пик, винаги е добра практика да зададете сигнал, ако връзката надвишава този брой.
Ако числото стане твърде голямо, можете да увеличите мащаба, за да се погрижите за това увеличение. За да направите това, трябва да знаете броя на наличните връзки в рамките на даден период, в противен случай, ако наличните връзки не са достатъчни, заявките няма да бъдат обработени навреме.
По подразбиране MongoDB осигурява поддръжка за до 1 милион връзки. С вашия мониторинг винаги се уверете, че текущите връзки никога не се доближават твърде близо до тази стойност. Можете да проверите стойността в обекта за връзки.

Съхранение
Всеки ред и запис на данни в MongoDB се нарича документ. Данните за документа са във формат BSON. В дадена база данни, ако изпълните командата db.stats(), ще ви бъдат представени тези данни.
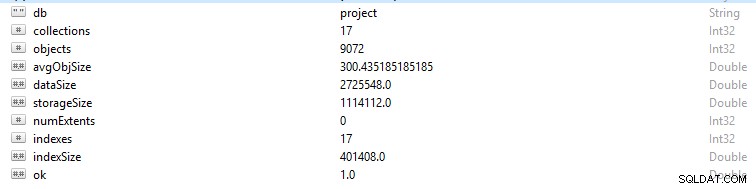
- StorageSize определя размера на всички екстенти на данни в базата данни.
- IndexSize очертава размера на всички индекси, създадени в тази база данни.
- размерът на данни е мярка за общото пространство, заето от документите в базата данни.
Понякога можете да видите промяна в паметта, особено ако са изтрити много данни. В този случай трябва да настроите сигнал, за да сте сигурни, че не се дължи на злонамерена дейност.
Понякога общият размер на хранилището може да се увеличи, докато графиката на трафика на базата данни е постоянна и в този случай трябва да проверите структурата на приложението или базата данни, за да избегнете дублиране, ако не е необходимо.
Подобно на общата памет на компютъра, MongoDB също има кешове, в които временно се съхраняват активни данни. Въпреки това, една операция може да поиска данни, които не са в тази активна памет, следователно да направи заявка от основната дискова памет. Тази заявка или ситуация се наричат грешка на страницата. Заявките за грешка в страницата идват с ограничение на отнемането на повече време за изпълнение и могат да бъдат вредни, когато се появяват често. За да избегнете този сценарий, уверете се, че размерът на вашата RAM винаги е достатъчен, за да се погрижи за наборите от данни, с които работите. Трябва също така да се уверите, че нямате излишни схеми или ненужни индекси.
Кеш
Кешът е елемент за временно съхранение на данни за често достъпни данни. В WiredTiger често се използват кешът на файловата система и кешът на двигателя за съхранение. Винаги се уверете, че работният ви комплект не надхвърля наличния кеш, в противен случай грешките на страницата ще се увеличат, причинявайки някои проблеми с производителността.
В даден момент може да решите да промените честите си операции, но промените понякога не се отразяват в кеша. Тези немодифицирани данни се наричат „мръсни данни“. Той съществува, защото все още не е прехвърлен на диск. Ще се получат тесни места, ако количеството „мръсни данни“ нарасне до някаква средна стойност, определена от бавно записване на диска. Добавянето на още парчета ще помогне да се намали този брой.
Използване на процесора
Неправилното индексиране, лошата структура на схемата и недружелюбно проектираните заявки ще изискват повече внимание на процесора, следователно очевидно ще увеличат използването му.
Операции с пропускателна способност
До голяма степен получаването на достатъчно информация за тези операции може да позволи на човек да избегне последващи неуспехи като грешки, насищане на ресурси и функционални усложнения.
Винаги трябва да отчитате броя на операциите за четене и запис в базата данни, тоест изглед на високо ниво на дейностите на клъстера. Познаването на броя на операциите, генерирани за заявките, ще ви позволи да изчислите натоварването, което се очаква да обработва базата данни. След това натоварването може да се обработва или чрез увеличаване на вашата база данни, или с мащабиране; в зависимост от вида на ресурсите, с които разполагате. Това ви позволява лесно да прецените коефициента, в който се натрупват заявките към скоростта, с която се обработват. Освен това можете да оптимизирате заявките си по подходящ начин, за да подобрите производителността.
За да проверите броя на операциите за четене и запис, изпълнете тази команда db.serverStatus(), след което отидете до обекта locks.global, стойността за свойството r представлява броя на заявките за четене и w броя на записите.
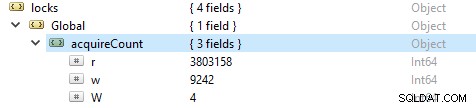
По-често операциите за четене са повече от операциите за запис. Активните клиентски показатели се отчитат под globalLock.
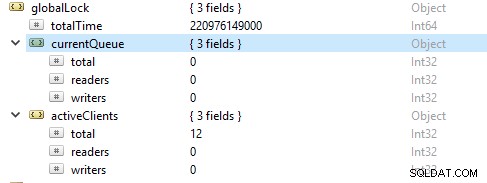
Насищане и ограничаване на ресурсите
Понякога базата данни може да не е в крак със скоростта на запис и четене, както се представя от нарастващия брой заявки на опашка. В този случай трябва да разширите своята база данни, като предоставите повече фрагменти, за да позволите на MongoDB да адресира заявките достатъчно бързо.
Нови проблеми
Регистрационните файлове на MongoDB винаги дават общ преглед на върнатите изключения за assert. Този резултат ще ви даде представа за възможните причини за грешки. Ако изпълните командата db.serverStatus(), някои от сигналите за грешки, които ще забележите, включват:

- Редовни твърдения:те са в резултат на неуспешна операция. Например в схема, ако стойност на низ е предоставена на цяло число, което води до неуспешно четене на BSON документа.
- Предупреждението твърди:това често са сигнали за някакъв проблем, но не оказват голямо влияние върху работата му. Например, когато надстроите своя MongoDB, може да бъдете предупредени чрез оттеглени функции.
- Съобщение твърди:те са в резултат на вътрешни изключения на сървъра, като бавна мрежа или ако сървърът не е активен.
- Потребителски асерти:подобно на обикновените твърдения, тези грешки възникват при изпълнение на команда, но често се връщат на клиента. Например, ако има дублирани ключове, недостатъчно дисково пространство или няма достъп за запис в базата данни. Ще изберете да проверите приложението си, за да коригирате тези грешки.



