Когато инсталирате ClusterControl, той има конфигурация по подразбиране, която може би не отговаря на вашите изисквания, така че вероятно ще трябва да персонализирате тази инсталация. За това можете да промените конфигурационните файлове, но също така можете да проверите или промените настройките на ClusterControl по време на изпълнение. В този блог ще ви покажем къде можете да видите тази конфигурация и какви са наличните опции за използване тук.
Къде можете да видите конфигурацията на ClusterControl Runtime?
Има два различни начина да проверите това. Първо можете да отидете на ClusterControl -> Глобални настройки -> Конфигурации по време на изпълнение, след което изберете своя клъстер.
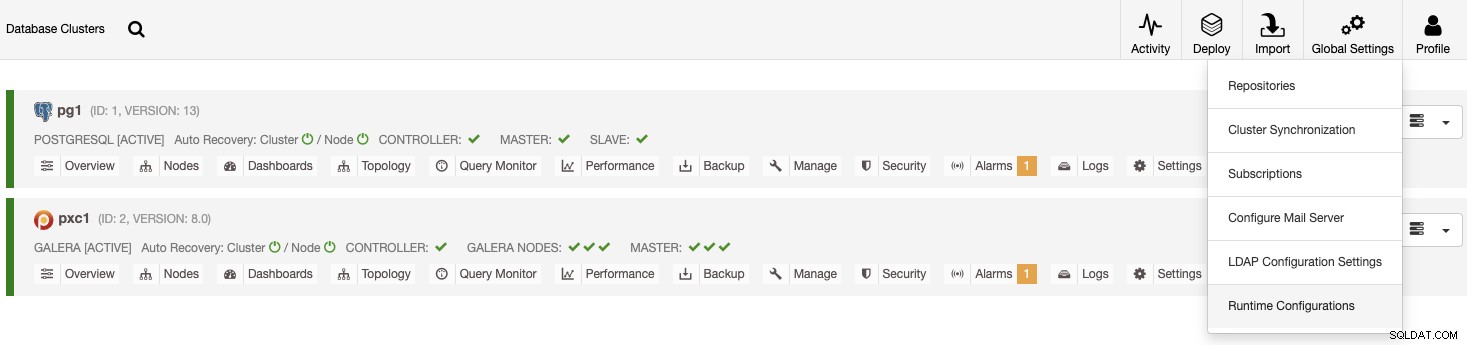
Друг начин е ClusterControl -> Изберете Cluster -> Settings -> Runtime Configurations .
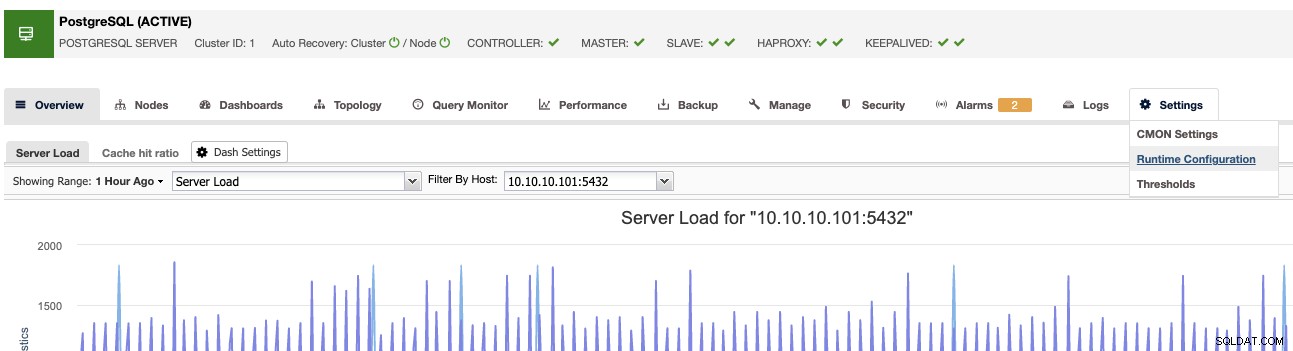
И в двата случая ще отидете на едно и също място, Runtime Configuration раздел.
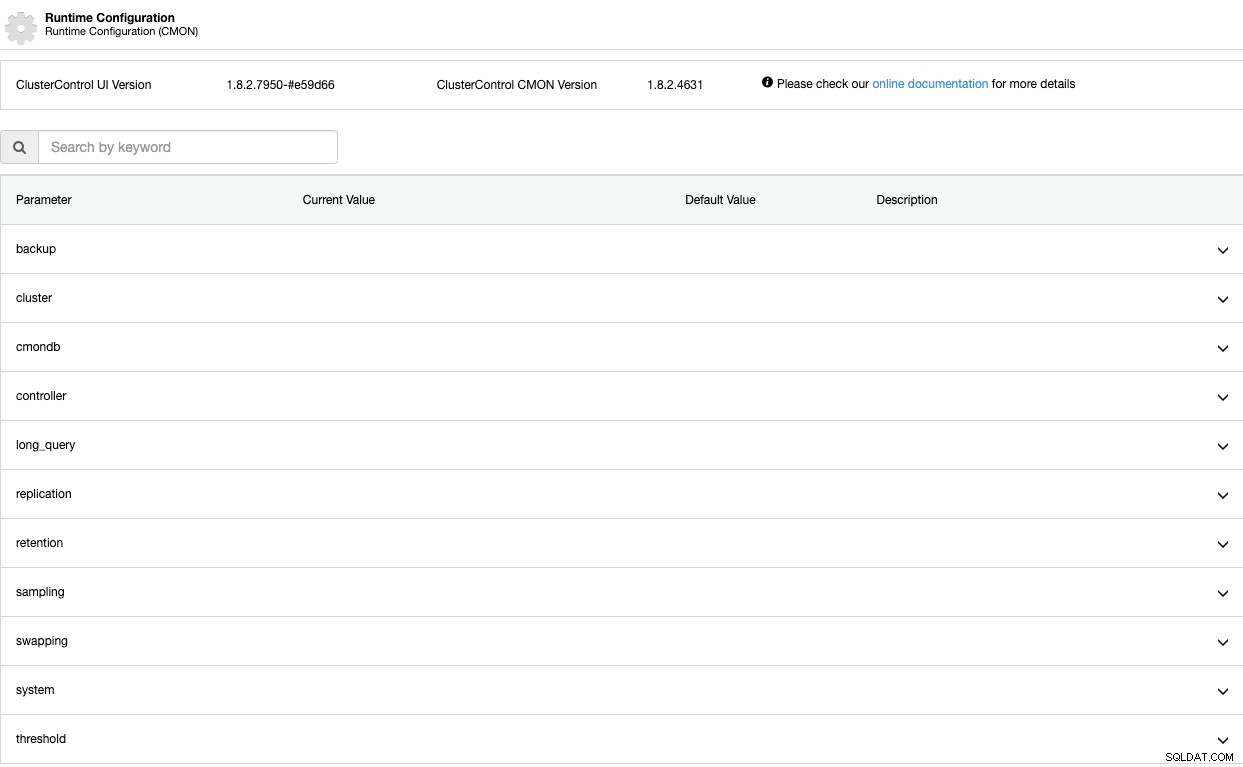
Конфигурационни параметри по време на изпълнение
Сега нека видим тези параметри един по един. Имайте предвид, че тези параметри зависят от технологията на базата данни, която използвате, така че най-вероятно няма да ги видите всички по едно и също време в един и същ клъстер.
Резервно копие
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| disable_backup_email | false | Тази настройка контролира дали имейлите се изпращат или не, ако архивирането е завършено или неуспешно. |
| backup_user | backupuser | Потребителското име на акаунта в базата данни, използван за управление на резервни копия. |
| backup_create_hash | true | Конфигурира ClusterControl, ако трябва да изчисли md5hash върху създадените архивни файлове и да ги провери. |
| pitr_retention_hours | 0 | Часове на задържане (за изтриване на стари архивни журнали на WAL) за PITR. |
| netcat_port | 9999,9990-9998 | Списък с Netcat портове и диапазони от портове, използвани за поточно архивиране. По подразбиране ще се предпочитат „9999,9990-9998“ и порт 9999, ако има такива. |
| backupdir | /home/user/backups | Резервната директория по подразбиране, която трябва да бъде предварително попълнена във Frontend. |
| backup_subdir | РЕзервно копие-%I | Задайте името на поддиректорията за архивиране. Този низ може да съдържа стандартни разделители на полета „%X“, например „%06I“ ще бъде заменен от цифровия идентификатор на резервното копие във формат 6 за цялото поле, който използва „0“ като водещи символи за попълване. Ето списъка с полета, които бекендът поддържа в момента:- B Датата и часът, когато е започнало създаването на резервно копие. - H Името на хоста за архивиране, хоста, който е създал архива. - i Числовият идентификатор на клъстера. - I Числовият идентификатор на архива. - J Числовият идентификатор на заданието, създало архива. - M Методът за архивиране (напр. "mysqldump"). - O Името на потребителя, който инициира заданието за архивиране. - S Името на хоста за съхранение, хоста, който съхранява архивните файлове. - % Самият знак за процент. Използвайте знака за два процента, „%%“ по същия начин, по който стандартната функция printf() го интерпретира като знак за един процент. |
| backup_retention | 31 | Настройката за колко дни да се съхраняват резервните копия. Архивните копия, съответстващи на периода на задържане, се премахват. |
| backup_cloud_retention | 180 | Настройката за колко дни да се съхраняват резервните копия, качени в облак. Архивните копия, съответстващи на периода на задържане, се премахват. |
| backup_n_safety_copies | 1 | Настройката за това колко завършени пълни резервни копия ще се съхраняват, независимо от състоянието им на запазване. |
Клъстер
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| име_клъстер | Името на клъстера за лесна идентификация. | |
| enable_node_autorecovery | true | Настройка за автоматично възстановяване на възел. |
| enable_cluster_autorecovery | true | Ако е вярно, ClusterControl ще извърши автоматично възстановяване на клъстера, ако е false, възстановяването на клъстера няма да се извърши автоматично. |
| configdir | /etc/ | Конфигурационната директория на сървъра на базата данни. |
| created_by_job | Идентификационният номер на заданието създаде този клъстер. | |
| ssh_keypath | /home/user/.ssh/id_rsa | SSH ключовият файл, използван за свързване с възли. |
| selection_server_try_once | true | Опция за URI за връзка с MongoDB. Определя дали изборът на сървър трябва да се повтори при неуспех, докато изтече времето за изчакване на избор на сървър, или просто да се върне с грешка наведнъж. |
| server_selection_timeout_ms | 30000 | Опция за URI за връзка с MongoDB. Определя стойността за изчакване, докато mongodriver трябва да се опита да извърши успешна операция за избор на сървър. |
| собственик | Потребителският идентификатор на ClusterControl на собственика на обекта на клъстера. | |
| group_owner | Идентификаторът на групата ClusterControl на групата, която притежава обекта на клъстера. | |
| cdt_path | Местоположението на обекта на клъстера в дървото на директорията на ClusterControl. | |
| маркери | / | Набор от низове, които потребителят може да посочи. |
| acl | Списъкът за контрол на достъпа като низ, контролиращ достъпа до обекта на клъстера. | |
| mongodb_user | admindb | Потребителското име на MongoDB. |
| mongodb_basedir | /usr/ | Базата за инсталиране на MongoDB. |
| mysql_basedir | /usr/ | Основната база за инсталиране на MySQL. |
| scriptdir | /usr/bin/ | Директорията на скриптовете на инсталацията на MySQL. |
| постановителна_директория | /home/user/s9s_tmp | Пътека за изготвяне на временни файлове. |
| bindir | /usr/bin | Директорията /bin на инсталацията на MySQL. |
| monitored_mysql_port | 3306 | Номерът на порта на наблюдавания MySQL сървър. |
| ndb_connectstring | 127.0.0.1:1186 | Настройката на низ за свързване на NDB за MySQL Cluster. |
| ndbd_datadir | Директорът с данни на NDBD възлите. | |
| mgmd_datadir | Директорът с данни на NDB MGMD възлите. | |
| os_user | Потребителското име на SSH, използвано за достъп до възли. | |
| repl_user | cmon_replication | Потребителското име за репликация. |
| доставчик | Името на доставчика на базата данни, използвано за внедряване. | |
| galera_version | Използвания номер на версията на Galera. | |
| версия_сървър | Използваната версия на сървъра на базата данни за внедряване. | |
| postgresql_user | admindb | Потребителското име на PostgreSQL. |
| galera_port | 4567 | Портът на galera, който да се използва при добавяне на възли/garbd и конструиране на wsrep_cluster_address. Не променяйте по време на изпълнение. |
| auto_manage_readonly | true | Разрешаване на ClusterControl да управлява флага само за четене на управляваните MySQL сървъри. |
| node_recovery_lock_file | Посочете файл за заключване и ако присъства на възел, възелът няма да се възстанови. Отговорност на администратора е да създаде/премахне файла. |
Cmondb
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| cmon_db | cmon | Името на локалната база данни на ClusterControl. |
| cmondb_hostname | 127.0.0.1 | Име на хост на сървъра на локалната база данни ClusterControl MySQL. |
| mysql_port | 3306 | Локалният порт на MySQL сървър на база данни ClusterControl. |
| cmon_user | cmon | Името на акаунта за достъп до локалната база данни ClusterControl. |
Контролер
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| controller_id | 5a3a993d-xxxx | Произволен низ от идентификатор на този екземпляр на контролера. |
| cmon_hostname | 192.168.xx.xx | Името на хоста на контролера. |
| diror_report_dir | /home/user/s9s_tmp | Местоположение за съхранение на отчети за грешки. |
Дълга_заявка
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| long_query_time | 0,5 | Прагова стойност за бавна проверка на заявката. |
| query_monitor_alert_long_running_query | true | Вдига аларма, ако заявка се изпълнява за по-дълго от query_monitor_long_running_query_ms. |
| query_monitor_kill_long_running_query | false | Прекратете заявката, ако заявката се изпълнява по-дълго от query_monitor_long_running_query_ms. |
| query_monitor_long_running_query_time_ms | 30000 | Вдига аларма, ако заявка се изпълнява за по-дълго от query_monitor_long_running_query_ms. Минималната стойност е 1000. |
| query_monitor_long_running_query_matching_info | Съпоставете само заявки с 'Информация', отговаряща само на този POSIX регулярен израз. Няма стойност по подразбиране, съвпада с всяка информация. | |
| query_monitor_long_running_query_matching_info_negate | false | Отказ на резултата от query_monitor_long_running_query_matching_info. |
| query_monitor_long_running_query_matching_host | Съответствие само на заявки с 'Host', отговарящ само на този POSIX регулярен израз. Няма стойност по подразбиране, съответства на всеки хост. | |
| query_monitor_long_running_query_matching_db | Съпоставете само заявки с 'Db', отговарящ само на този POSIX регулярен израз. Няма стойност по подразбиране, съвпада с всеки Db. | |
| query_monitor_long_running_query_matching_user | Съпоставете само заявки с „Потребител“, отговарящ само на този POSIX регулярен израз. Няма стойност по подразбиране, съответства на всеки потребител. | |
| query_monitor_long_running_query_matching_user_negate | false | Отказ на резултата от query_monitor_long_running_query_matching_user. |
| query_monitor_long_running_query_matching_command | Заявка | Съпоставете само заявки с „Команда“, отговаряща само на този POSIX регулярен израз. По подразбиране е „Заявка“. |
Репликация
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| max_replication_lag | 10 | Максимално разрешено забавяне на репликацията в секунди преди изпращане на аларма. |
| replication_stop_on_error | true | Контролира дали процедурите за отказ/превключване трябва да се провалят, ако се срещнат грешки, които могат да причинят загуба на данни. |
| replication_auto_rebuild_slave | false | Ако SQL THREAD е спрян и кодът на грешката е различен от нула, тогава подчиненият ще бъде автоматично възстановен. |
| replication_failover_blacklist | Списък, разделен със запетая, с имена на хост:двойки портове. Сървърите в черния списък няма да се считат за кандидат по време на отказ. replication_failover_blacklist се игнорира, ако replication_failover_whitelist е зададен. | |
| replication_failover_whitelist | Списък, разделен със запетая, с имена на хост:двойки портове. Само сървърите в белия списък ще се считат за кандидати по време на отказ. Ако няма наличен сървър в белия списък (нагоре/свързан), преминаването при отказ ще бъде неуспешно. replication_failover_blacklist се игнорира, ако replication_failover_whitelist е зададен. | |
| replication_onfail_failover_script | Този скрипт се изпълнява веднага след като се установи, че е необходимо преминаване при отказ. Ако скриптът върне различен от нула или не съществува, преминаването при отказ ще бъде прекратено. Четири аргумента се доставят на скрипта и се задават, ако са известни, в противен случай празни:arg1='всички сървъри' arg2='неуспешен главен' arg3='избран кандидат', arg4='подчинени на oldmaster (кандидатите)' и се предава като това:'scripname arg1 arg2 arg3 arg4' Скриптът трябва да бъде достъпен на контролера и изпълним. | |
| replication_pre_failover_script | Този скрипт се изпълнява преди да се случи превключването при отказ, но след като кандидатът е избран и е възможно да се продължи процеса на отказ. Ако скриптът върне различен от нула или не съществува, преминаването при отказ ще бъде прекратено. Четири аргумента се доставят на скрипта и се задават, ако са известни, в противен случай празни:arg1='всички сървъри' arg2='неуспешен главен' arg3='избран кандидат', arg4='подчинени на oldmaster (кандидатите)' и се предава като това:'scripname arg1 arg2 arg3 arg4' Скриптът трябва да бъде достъпен на контролера и изпълним. | |
| replication_post_failover_script | Този скрипт се изпълнява, след като се случи отказът (избира се нов главен и работи и работи). Ако скриптът върне различен от нула или не съществува, преминаването при отказ ще бъде прекратено. Четири аргумента се предоставят на скрипта и се задават, ако са известни, в противен случай празни.:arg1='всички сървъри' arg2='неуспешен главен' arg3='избран кандидат', arg4='подчинени на oldmaster (кандидатите)' и се предава така:'scripname arg1 arg2 arg3 arg4' Скриптът трябва да бъде достъпен на контролера и изпълним. | |
| replication_post_unsuccessful_failover_script | Този скрипт се изпълнява, ако опитът за преодоляване е неуспешен. Ако скриптът върне различен от нула или не съществува, преминаването при отказ ще бъде прекратено. Четири аргумента се предоставят на скрипта и се задават, ако са известни, в противен случай празни.:arg1='всички сървъри' arg2='неуспешен главен' arg3='избран кандидат', arg4='подчинени на oldmaster (кандидатите)' и се предава така:'scripname arg1 arg2 arg3 arg4' Скриптът трябва да бъде достъпен на контролера и изпълним. |
Задържане
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| ops_report_retention | 31 | Настройката за колко дни да се съхраняват оперативните отчети. Отчетите, съответстващи на периода на задържане, се премахват. |
Извадка
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| enable_icmp_ping | true | Превключва дали ClusterControl трябва да измерва ICMP времената за пинг към хоста. |
| host_stats_collection_interval | 30 | Настройка за интервала на събиране на хоста (CPU, памет и т.н.). |
| host_stats_window_size | 180 | Задаване на размера на прозореца (в секунди) за проверка на статистиката за повишаване/изчистване на алармите за статистика на хоста. |
| db_stats_collection_interval | 30 | Настройка за интервал за събиране на статистически данни от базата данни. |
| db_proc_stats_collection_interval | 5 | Настройка за интервал за събиране на статистически данни за процеса на база данни. Минималната допустима стойност е 1 секунда. Изисква рестартиране на услугата cmon. |
| lb_stats_collection_interval | 15 | Настройка за интервал за събиране на статистики за балансиране на натоварването. |
| db_schema_stats_collection_interval | 108000 | Настройка за интервал за наблюдение на статистиката на схемата. |
| db_deadlock_check_interval | 0 | Колко често да проверявате за блокиране. Посочено за секунди. Откриването на застой ще повлияе на използването на процесора на възлите на базата данни. |
| log_collection_interval | 600 | Контролира интервала между колекциите на регистрационни файлове. |
| db_hourly_stats_collection_interval | 5 | Контролира колко секунди са между всяка отделна извадка в статистиката за часовия диапазон. |
| monitored_mountpoints | Списъкът с точки за монтиране, които трябва да бъдат наблюдавани. | |
| monitor_cpu_temperature | false | Наблюдавайте температурата на процесора. |
| log_queries_not_using_indexes | false | Настройте монитора на заявки да открива заявки, които не използват индекси. |
| query_sample_interval | 1 | Контролира интервала на монитора на заявките в секунди, -1 означава липса на наблюдение на заявки. |
| query_monitor_auto_purge_ps | false | Ако е активирано, P_S таблицата events_statements_summary_by_digest ще бъде автоматично изчистена (TRUNCATE TABLE) на всеки час. |
| schema_change_detection_address | Ще бъдат извършени проверки (използвайки ПОКАЖЕТЕ ТАБЛИЦИТЕ/ПОКАЖЕТЕ СЪЗДАВАНЕ НА ТАБЛИЦА), за да се определи дали схемата се е променила. Проверките се изпълняват на посочения адрес и са във формат HOSTNAME:PORT. Базите данни schema_change_detection_databases също трябва да бъдат зададени. Създава се разлика на променена таблица. | |
| schema_change_detection_databases | Списък с бази данни, разделени със запетая, за наблюдение за промени в схемата. Ако е празно, не се правят проверки. | |
| schema_change_detection_pause_time_ms | 0 | Време за пауза в ms между всяко ПОКАЖЕНЕ СЪЗДАВАНЕ НА ТАБЛИЦА. Времето за пауза ще повлияе на продължителността на процеса на откриване. |
| enable_is_queries | true | Указва дали заявките към information_schema ще бъдат изпълнени или не. Заявките към information_schema може да не са подходящи, когато имате много обекти на схема (100s бази данни, 100s таблици във всяка база данни, тригери, потребители, събития, sprocs). Ако е деактивирано, заявката, която ще бъде изпълнена, ще бъде регистрирана, за да може да се определи дали заявката е подходяща във вашата среда. |
Размяна
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| swap_warning | 20 | Праг на предупредителна аларма за размяна. |
| swap_critical | 90 | Критичен праг на аларма за размяна. |
| swap_inout_period | 0 | Интервалът за размяна на входно/изходни аларми (<=0 деактивира). |
| swap_inout_warning | 10240 | Броят на разменените I/O страници в посочения интервал (swap_inout_period, по подразбиране 10 минути) за предупреждение. |
| swap_inout_critical | 102400 | Броят на разменените I/O страници в посочения интервал (swap_inout_period, по подразбиране 10 минути) за критични. |
Система
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| cmon_config_path | /etc/cmon.d/cmon_x.cnf | Пътят на конфигурационния файл. Тази конфигурационна стойност е само за четене. |
| os | debian/redhat | Типът на ОС. Възможните стойности са 'debian' или 'redhat'. |
| libssh_timeout | 30 | Стойността на изчакване на мрежата за SSH връзки. |
| sudo | sudo -n 2>/dev/null | Командата, използвана за получаване на привилегии на суперпотребител. |
| ssh_port | 22 | Портът за SSH връзки към възлите. |
| local_repo_name | Използваните имена на локално хранилище за внедряване на клъстер. | |
| frontend_url | URL адресът, изпратен в имейлите, за да насочи получателя към уеб интерфейса на ClusterControl. | |
| изчистване | 7 | Колко дълго ClusterControl ще съхранява данни. Измерено в дни, работни места, съобщения за работа, аларми, събрани регистрационни файлове, оперативни отчети, информация за растеж на базата данни, по-стара от тази, ще бъде изтрита. |
| os_user_home | /home/user | НАЧАЛНАТА директория на потребителя, използван на възли. |
| cmon_mail_sender | Използваният изпращач на имейл за изпратени имейли. | |
| plugin_dir | Пътят на директорията на плъгините. | |
| use_internal_repos | false | Настройка, която деактивира настройването на хранилището на трета страна. |
| cmon_use_mail | false | Настройка за използване на командата 'mail' за изпращане на имейли. |
| enable_html_emails | true | Разрешава изпращането на HTML имейли. |
| send_clear_alarm | true | Превключва изпращането на имейл в случай на изчистване на аларми в клъстера. |
| software_packagedir | Това е мястото за съхранение на софтуерни пакети, т.е. всички необходими файлове за успешно инсталиране на възел, ако няма налично хранилище yum/apt, трябва да бъдат поставени тук. Прилага се главно за MySQL Cluster или по-стари инсталации на Codership/Galera. |
Праг
| Име | Стойност по подразбиране | Описание |
|---|---|---|
| ram_warning | 80 | Предупредителен праг на аларма за използване на RAM. |
| ram_critical | 90 | Критичен праг на аларма за използване на RAM. |
| предупреждение_за_дисковото_пространство | 80 | Праг на аларма за предупреждение за използване на диск. |
| критично_дисково_пространство | 90 | Критичен праг на аларма за използване на диск. |
| cpu_warning | 80 | Праг на предупредителна аларма за използване на процесора. |
| cpu_critical | 90 | Критичен праг на аларма за използване на процесора. |
| cpu_steal_warning | 10 | Праг на предупредителна аларма за кражба на процесора. |
| cpu_steal_critical | 20 | Критичен праг на аларма за кражба на процесора. |
| cpu_iowait_warning | 50 | Праг на предупредителна аларма за CPU IO Изчакайте. |
| cpu_iowait_critical | 60 | Критичен праг на аларма за CPU IO Изчакайте. |
| slow_ssh_warning | 6 | Ще се вдигне предупредителна аларма, ако отнеме повече време от определеното време за настройване на SSH връзка (сек.). |
| slow_ssh_critical | 12 | Критична аларма ще бъде повдигната, ако отнеме повече време от определеното време за настройване на SSH връзка (сек.). |
Заключение
Както можете да видите, има много параметри, които трябва да промените, ако трябва да адаптирате ClusterControl към вашето работно натоварване или бизнес. Може да е отнемаща време задача да прегледате всички стойности и да ги промените съответно, но в края на деня това ще спести време, тъй като можете да извлечете максимума от всички функции на ClusterControl.



