В тази статия ще изградим скрепер за действителен Концерт на свободна практика, при който клиентът иска програма на Python да изстърже данни от Stack Overflow, за да вземе нови въпроси (заглавие на въпроса и URL). След това изпипаните данни трябва да се съхраняват в MongoDB. Струва си да се отбележи, че Stack Overflow има API, който може да се използва за достъп до точните същите данни. Клиентът обаче искаше скрепер, така че той получи скрепер.
Безплатен бонус: Щракнете тук, за да изтеглите скелет на проекта Python + MongoDB с пълен изходен код, който ви показва как да получите достъп до MongoDB от Python.
Актуализации:
- 01.03.2014 г. – Рефакториран паякът. Благодаря, @kissgyorgy.
- 18.02.2015 г. – Добавена част 2.
- 09.06.2015 г. – Актуализирано до най-новата версия на Scrapy и PyMongo – наздраве!
Както винаги, не забравяйте да прегледате условията за ползване/услуга на сайта и спазвайте robots.txt файл, преди да започнете работа по изстъргване. Уверете се, че се придържате към етичните практики за изстъргване, като не наводнявате сайта с многобройни заявки за кратък период от време. Отнасяйте се към всеки сайт, който изстъргвате, сякаш е ваш собствен .
Инсталиране
Нуждаем се от библиотеката Scrapy (v1.0.3) заедно с PyMongo (v3.0.3) за съхраняване на данните в MongoDB. Трябва да инсталирате и MongoDB (не е покрито).
Scrapy
Ако използвате OSX или версия на Linux, инсталирайте Scrapy с pip (с активиран virtualenv):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Ако сте на машина с Windows, ще трябва ръчно да инсталирате редица зависимости. Моля, вижте официалната документация за подробни инструкции, както и този видеоклип в YouTube, който създадох.
След като Scrapy е настроен, проверете инсталацията си, като изпълните тази команда в обвивката на Python:
>>>>>> import scrapy
>>>
Ако не получите грешка, можете да започнете!
PyMongo
След това инсталирайте PyMongo с pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Сега можем да започнем да създаваме робота.
Проект Scrapy
Нека започнем нов проект на Scrapy:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Това създава редица файлове и папки, които включват основен шаблон, за да започнете бързо:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Посочете данни
items.py файл се използва за дефиниране на „контейнери“ за съхранение на данните, които планираме да изстържем.
StackItem() класът наследява от Item (docs), който основно има редица предварително дефинирани обекти, които Scrapy вече е изградил за нас:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Нека добавим някои елементи, които всъщност искаме да съберем. За всеки въпрос клиентът се нуждае от заглавие и URL. Така че, актуализирайте items.py така:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Създайте паяка
Създайте файл, наречен stack_spider.py в директорията "паяци". Тук се случва магията – например, където ще кажем на Scrapy как да намери точното данни, които търсим. Както можете да си представите, това е специфично към всяка отделна уеб страница, която искате да изстържете.
Започнете с дефиниране на клас, който се наследява от Spider на Scrapy и след това добавяне на атрибути според нуждите:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Първите няколко променливи се обясняват сами (документи):
nameопределя името на паяка.allowed_domainsсъдържа базовите URL адреси за разрешените домейни, които паякът може да обхожда.start_urlsе списък с URL адреси, от които паякът да започне да обхожда. Всички следващи URL адреси ще започват от данните, които паякът изтегля от URL адресите вstart_urls.
Селектори на XPath
След това Scrapy използва XPath селектори за извличане на данни от уебсайт. С други думи, можем да изберем определени части от HTML данните въз основа на даден XPath. Както е посочено в документацията на Scrapy, "XPath е език за избор на възли в XML документи, който може да се използва и с HTML."
Можете лесно да намерите конкретен Xpath с помощта на инструментите за разработчици на Chrome. Просто проверете конкретен HTML елемент, копирайте XPath и след това настройте (ако е необходимо):
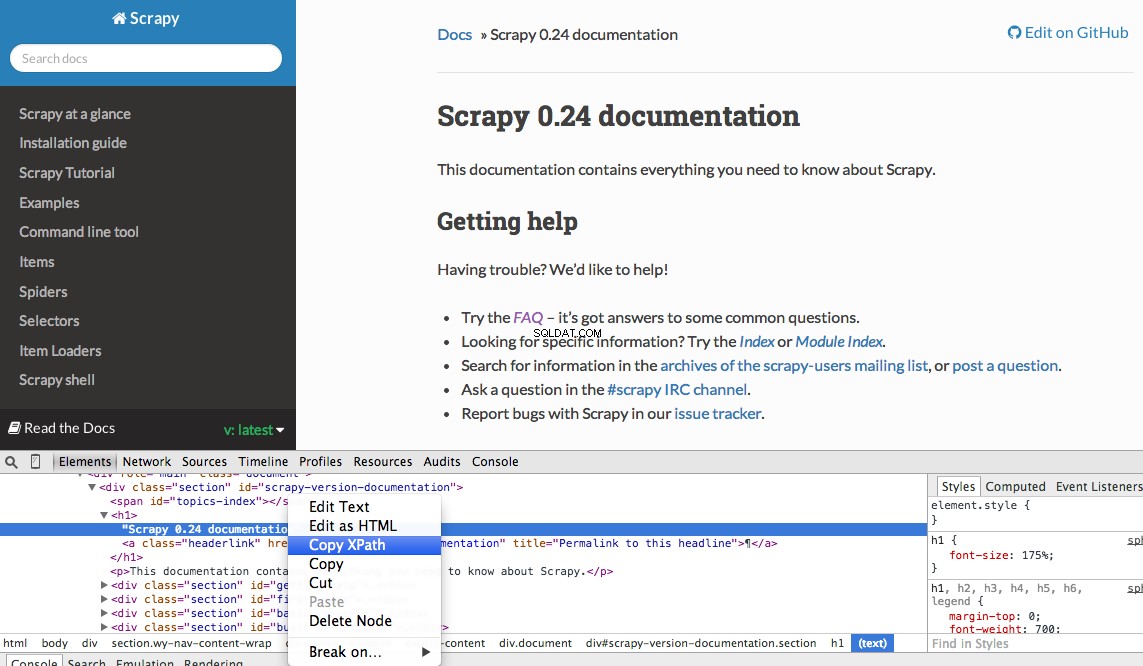
Инструментите за разработчици също ви дават възможността да тествате XPath селектори в конзолата на JavaScript, като използвате $x - т.е., $x("//img") :
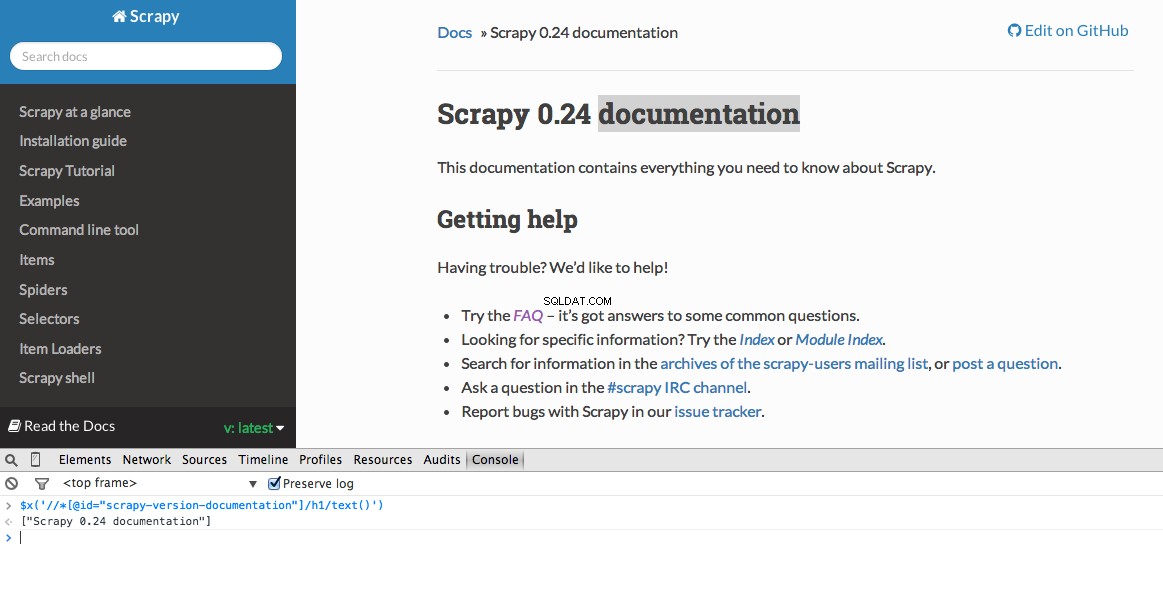
Отново, ние основно казваме на Scrapy откъде да започне да търси информация въз основа на дефиниран XPath. Нека отидем до сайта на Stack Overflow в Chrome и да намерим селекторите XPath.
Щракнете с десния бутон върху първия въпрос и изберете „Проверка на елемента“:
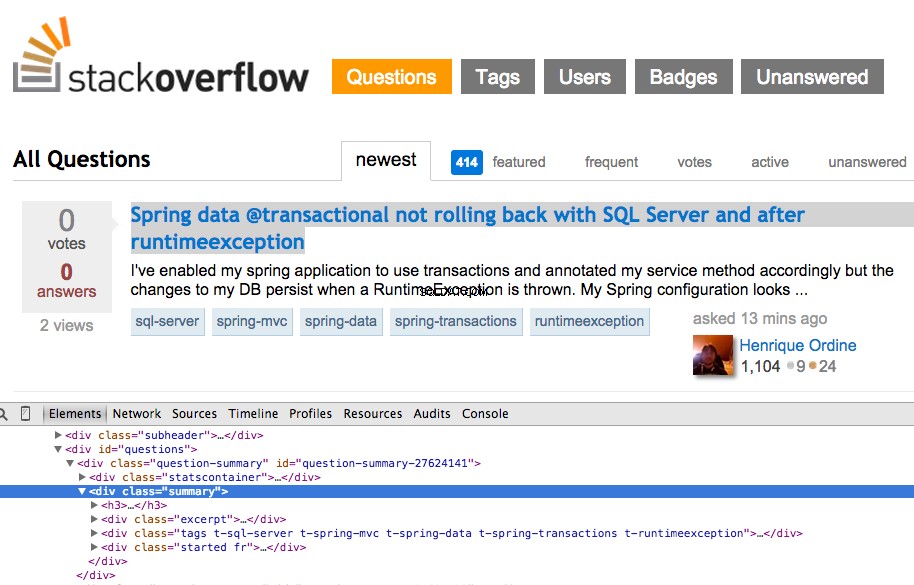
Сега вземете XPath за <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , и след това го тествайте в конзолата на JavaScript:
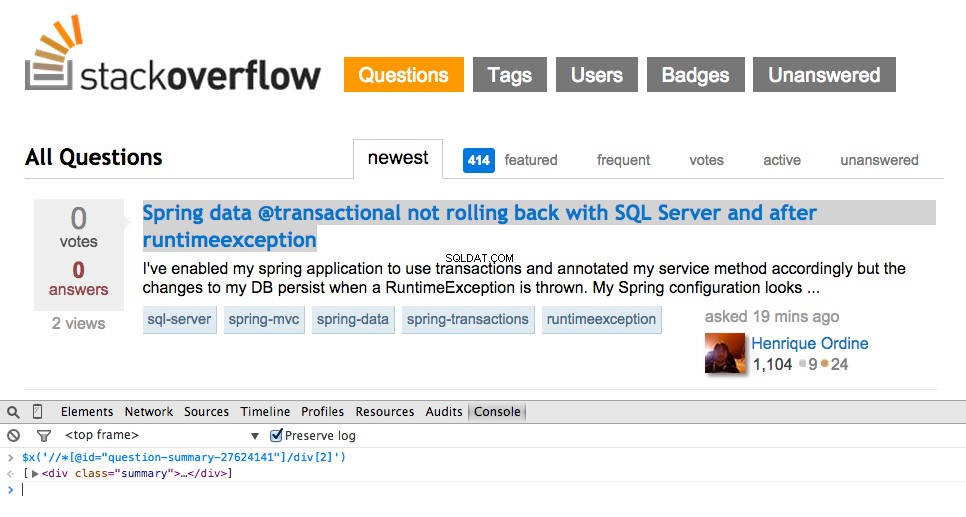
Както можете да разберете, той просто избира този един въпрос. Така че трябва да променим XPath, за да вземем всички въпроси. Някакви идеи? Просто е://div[@class="summary"]/h3 . Какво означава това? По същество този XPath гласи:Вземете всички <h3> елементи, които са дъщерни на <div> който има клас summary . Тествайте този XPath в конзолата на JavaScript.
Забележете как не използваме действителния изход на XPath от Chrome Developer Tools. В повечето случаи изходът е само полезен настрана, което обикновено ви насочва в правилната посока за намиране на работещия XPath.
Сега нека актуализираме stack_spider.py скрипт:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Извличане на данните
Все още трябва да анализираме и изстържем данните, които искаме, които попадат в рамките на <div class="summary"><h3> . Отново актуализирайте stack_spider.py така:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Заедно с проследяването на стека на Scrapy, трябва да видите изведени 50 заглавия на въпроса и URL адреси. Можете да изобразите изхода в JSON файл с тази малка команда:
$ scrapy crawl stack -o items.json -t json
Вече внедрихме нашия Spider въз основа на нашите данни, които търсим. Сега трябва да съхраняваме изпипаните данни в MongoDB.
Съхранете данните в MongoDB
Всеки път, когато даден елемент бъде върнат, искаме да потвърдим данните и след това да ги добавим към колекция Mongo.
Първоначалната стъпка е да създадем базата данни, която планираме да използваме, за да запазим всички наши обходени данни. Отворете settings.py и посочете конвейера и добавете настройките на базата данни:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Управление на тръбопровода
Настроихме нашия паяк да обхожда и анализира HTML и сме настроили настройките на нашата база данни. Сега трябва да свържем двете заедно чрез конвейер в pipelines.py .
Свържете се с базата данни
Първо, нека дефинираме метод за действително свързване с базата данни:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Тук създаваме клас, MongoDBPipeline() и имаме функция конструктор за инициализиране на класа, като дефинираме настройките на Mongo и след това се свързваме с базата данни.
Обработете данните
След това трябва да дефинираме метод за обработка на анализираните данни:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Ние установяваме връзка с базата данни, разопаковаме данните и след това ги запазваме в базата данни. Сега можем да тестваме отново!
Тест
Отново изпълнете следната команда в директорията „стек“:
$ scrapy crawl stack
ЗАБЕЛЕЖКА :Уверете се, че имате демона Mongo -
mongod- работи в друг прозорец на терминала.
Ура! Успешно съхранихме нашите обходени данни в базата данни:
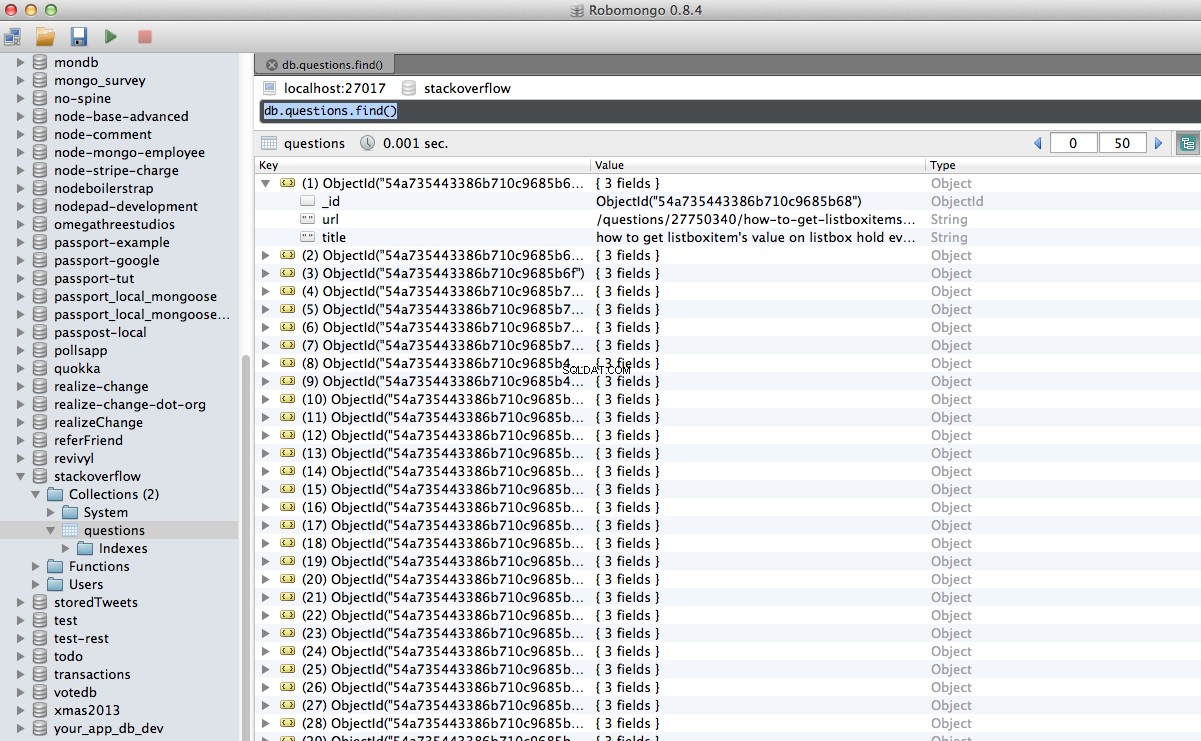
Заключение
Това е доста прост пример за използване на Scrapy за обхождане и изстъргване на уеб страница. Действителният проект на свободна практика изисква скриптът да следва връзките за пагинация и да изстърже всяка страница с помощта на CrawlSpider (docs), което е супер лесно за изпълнение. Опитайте да приложите това сами и оставете коментар по-долу с връзката към хранилището на Github за бърз преглед на кода.
Нужда от помощ? Започнете с този скрипт, който е почти завършен. След това вижте част 2 за пълното решение!
Безплатен бонус: Щракнете тук, за да изтеглите скелет на проекта Python + MongoDB с пълен изходен код, който ви показва как да получите достъп до MongoDB от Python.
Можете да изтеглите целия изходен код от хранилището на Github. Коментирайте по-долу с въпроси. Благодаря за четенето!



